







一、传统神经网络
1、 神经元:
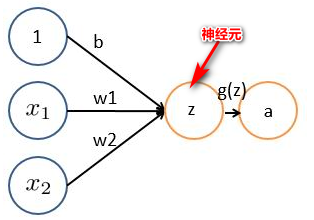
一个神经元的神经网络基本为
z
=
W
X
+
b
z = WX+b
z=WX+b。其中:
(1)
x
i
\displaystyle x_{i}
xi表示输入向量
(2)
w
i
\displaystyle w_{i}
wi为权重,几个输入则意味着有几个权重,即每个输入都被赋予一个权重
(3)b为偏置bias,提高泛化能力。
(4)g(z) 为激活函数,一般为sigmoid函数,目的是将输出压缩到0-1之间。
(5)a 为输出
2、激活函数:
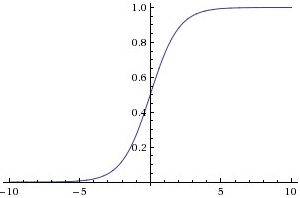
常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者relu常见于卷积层。
如sigmoid函数
g
(
z
)
=
1
1
+
e
−
z
\displaystyle g( z) =\frac{1}{1+e^{-z}}
g(z)=1+e−z1,其中z是一个线性组合,比如z可以等于
z
=
w
1
∗
x
1
+
w
2
∗
x
2
+
b
\displaystyle z=w_{1} *x_{1} +w_{2} *x_{2} +b
z=w1∗x1+w2∗x2+b。通过代入很大的正数或很小的负数到g(z)函数中,其结果趋近于0或1。
sigmoid函数的功能是相当于把一个实数压缩至0到1之间。当z是非常大的正数时,g(z)会趋近于1,而z是非常小的负数时,则g(z)会趋近于0。这样一来便可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。
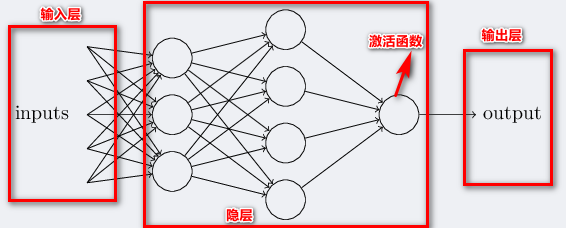
3、神经网络
下图是一个三层神经网络结构,最左边的原始输入信息称之为输入层,最右边的神经元称之为输出层(上图中输出层只有一个神经元),中间的叫隐藏层。
(1)输入层(Input layer),众多神经元(Neuron)接受大量非线形输入信息。输入的信息称为输入向量。
(2)输出层(Output layer),信息在神经元链接中传输、分析、权衡,形成输出结果。输出的信息称为输出向量。
(3)隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。如果有多个隐藏层,则意味着多个激活函数。每个连线上的权重不同。
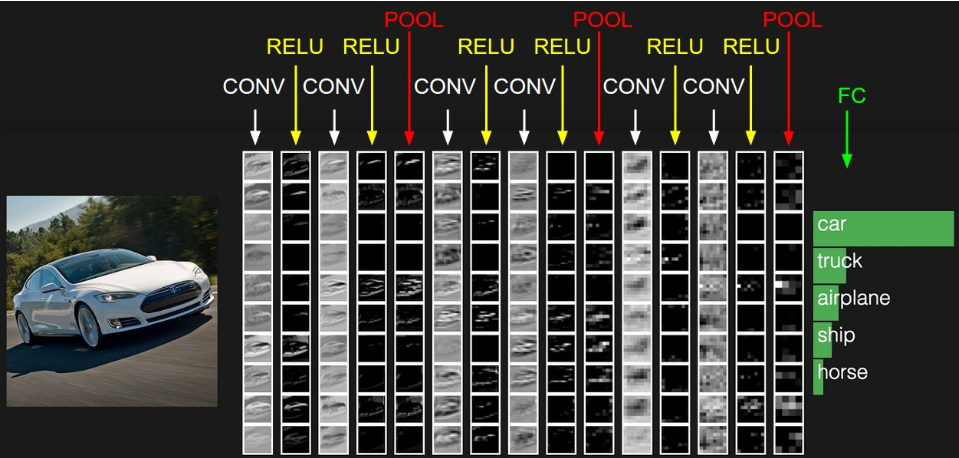
二、CNN
卷积神经网络保留了传统神经网络的结构,但每个隐层有不同的运算与功能。前面几层先学轮廓,后面学细节。
1、数据输入层(input layer):
常见的三种数据处理方式:
(1)去均值:把数据各个维度都中心化到0,避免数据过多偏差,影响训练效果
(2)归一化:幅度归一化到同样范围
(3)PCA/白化:降维,并对每个特征进行幅度归一化
2、卷积计算层(CONV layer)
(1)原理:
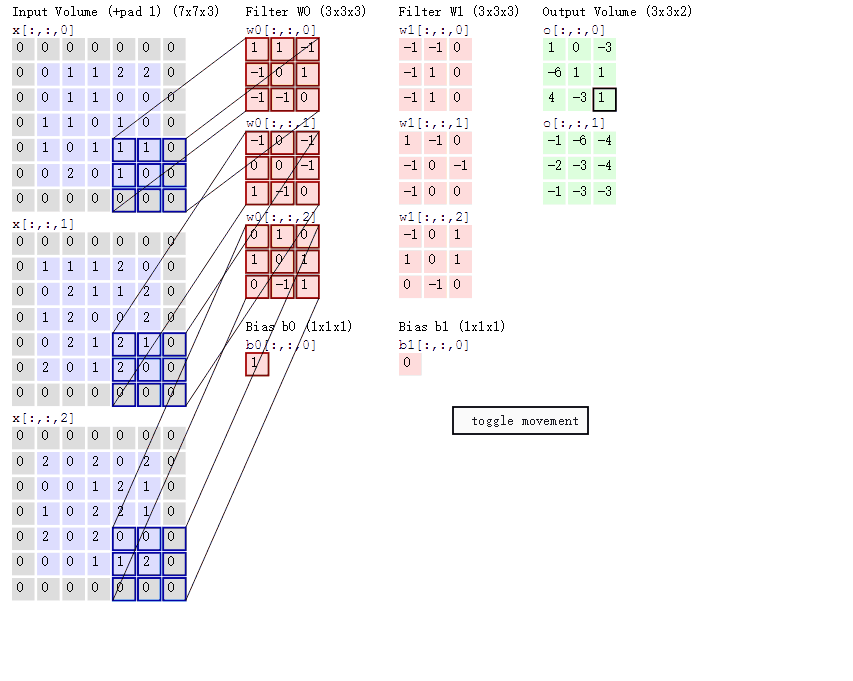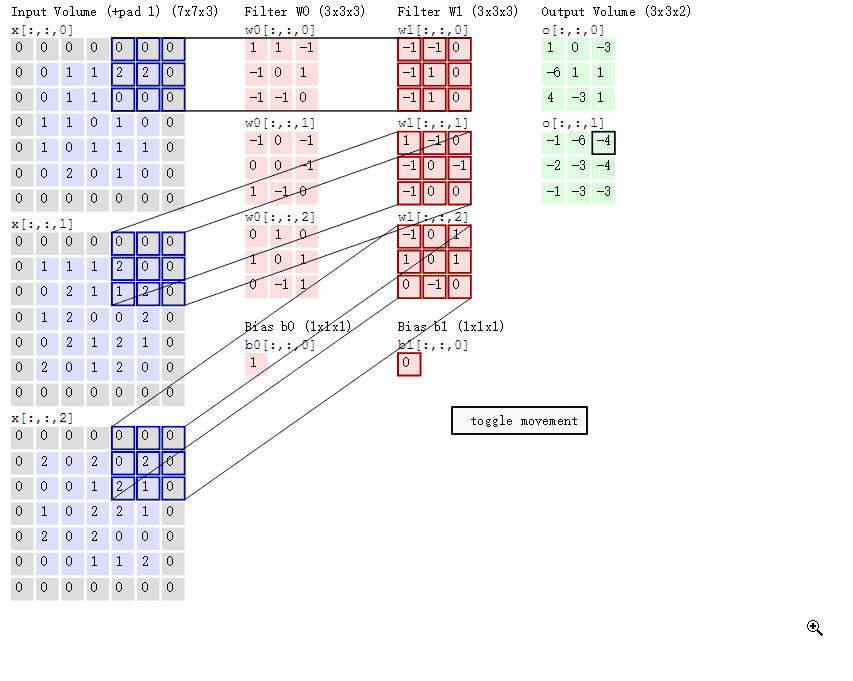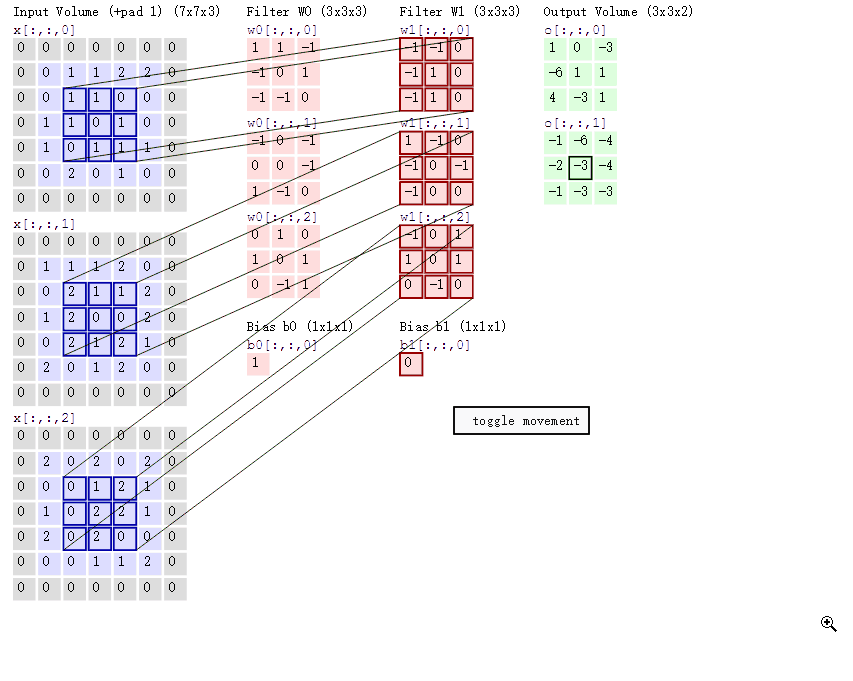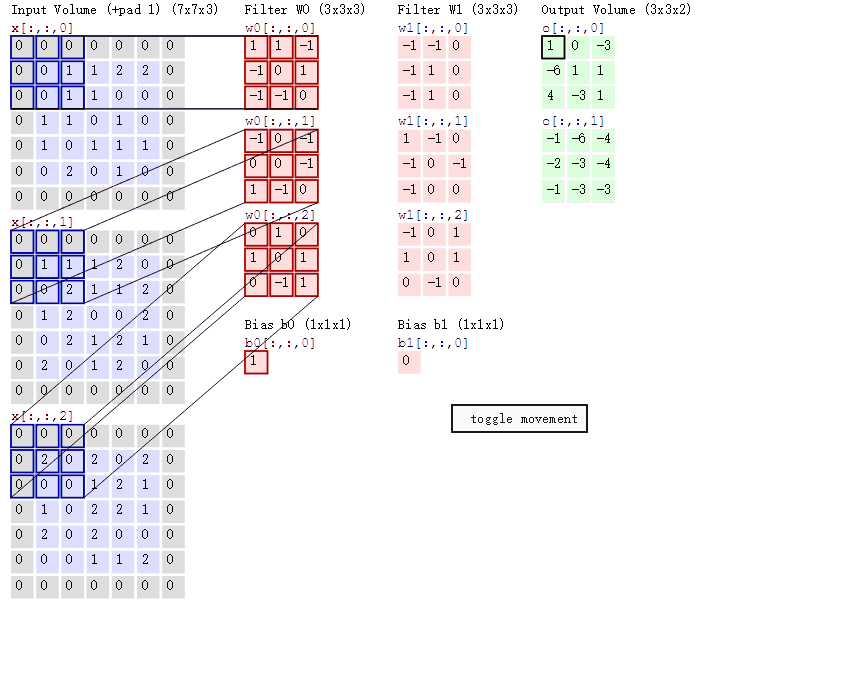
对应位置上是数字先相乘后相加。如,中间滤波器filter(带着一组固定权重的神经元)与数据窗口做内积,其具体计算过程:40 + 00 + 00 + 00 + 01 + 01 + 00 + 01 + -4*2 = -8特征抽取的主要工作在这层进行。不同的滤波器filter会得到不同的输出数据,比如颜色深浅、轮廓。相当于如果想提取图像的不同特征,则用不同的滤波器filter,提取想要的关于图像的特定信息:颜色深浅或轮廓。
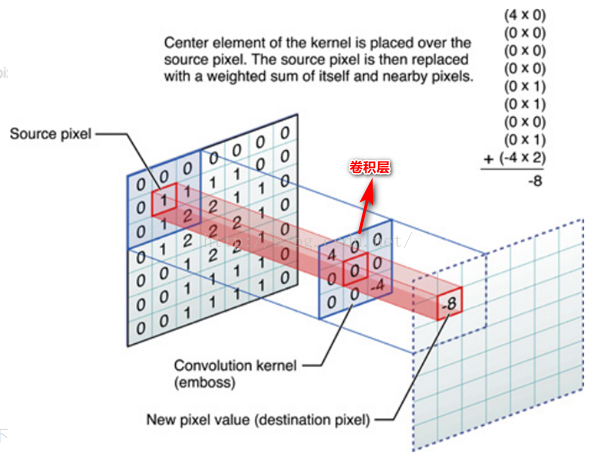
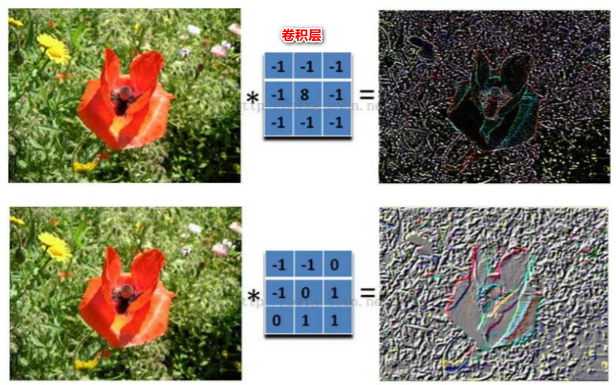
(2)GIF动态卷积图详解
在CNN中,滤波器filter(带着一组固定权重的神经元)对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据。CNN中的参数(权重)共享机制。参数如下:
- 深度depth:神经元个数,决定输出的depth厚度。同时代表滤波器个数。
- 步长stride:决定滑动多少步可以到边缘。
- 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。
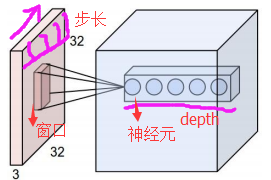
动态图如下:
随着左边数据窗口的平移滑动,滤波器Filter w0 / Filter w1对不同的局部数据进行卷积计算。得到两组不同的结果。 - 两个神经元,即depth=2,意味着有两个滤波器。
- 数据窗口每次移动两个步长取3*3的局部数据,即stride=2。
- zero-padding=1。
3、激励层
常使用ReLU是激活函数的一种,因为实际梯度下降中,sigmoid连乘容易引起梯度爆炸或梯度消失,且没有0中心化。

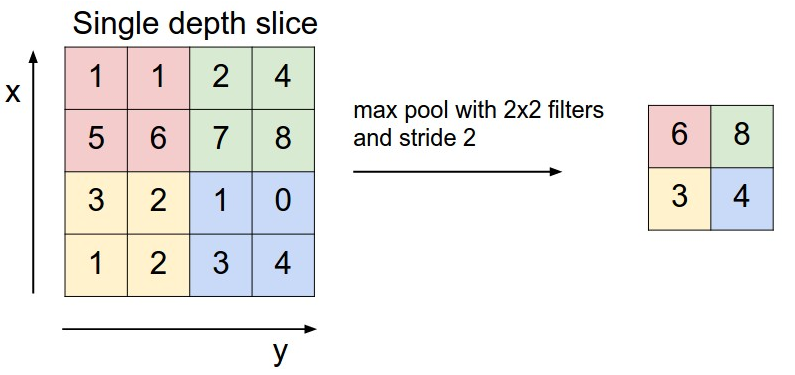
4、池化层
即取区域平均或最大。如下图左边部分中 左上角2x2的矩阵中6最大,右上角2x2的矩阵中8最大,左下角2x2的矩阵中3最大,右下角2x2的矩阵中4最大,所以得到上图右边部分的结果:6 8 3 4。可以降低维度。
5、全连接层
在卷积神经网络的最后,往往会出现一两层全连接层,全连接一般会把卷积输出的二维特征图转化成一维的一个向量
输入层:
128
∗
256
∗
256
∗
3
128*256*256*3
128∗256∗256∗3 (batch=128,图片大小
256
∗
256
256*256
256∗256,3个通道)
第一层卷积层:
128
∗
256
∗
256
∗
16
128*256*256*16
128∗256∗256∗16(batch=128,图片大小
256
∗
256
256*256
256∗256,16个通道)(以
4
∗
4
4*4
4∗4的窗口滑动,步长strid=1,填充padding=3;16个神经元)(为了方便理解,对边框进行填充,使得卷积后维度不变。16个神经元计算并行做卷积和,每个神经元计算后3个通道的值相加)
第一层池化:
128
∗
128
∗
128
∗
16
128*128*128*16
128∗128∗128∗16(batch=128,以
2
∗
2
2*2
2∗2的窗口滑动,图片尺寸缩小二分之一,步长strid=2;16个神经元)
第二层卷积层:
128
∗
128
∗
128
∗
32
128*128*128*32
128∗128∗128∗32(batch=128,以
4
∗
4
4*4
4∗4的窗口滑动,32个神经元,步长strid=1,填充padding=3,32个神经元计算并行做卷积和,每个神经元计算后16个通道的值相加)
第二层池化:
128
∗
64
∗
64
∗
32
128*64*64*32
128∗64∗64∗32(batch=128,以
2
∗
2
2*2
2∗2步长strid=2的窗口滑动)
全连接层过程:
方法一:将32层特征图片相加,将6464的矩形展平成。生成长度为(128,6464)维
方法二:将646432全部展平(128,646432)维,如:
特征展平操作reshape:
128
∗
(
64
∗
64
∗
32
)
128*(64*64*32)
128∗(64∗64∗32)
DNN1:
(
64
∗
64
∗
32
)
∗
100
(64*64*32)*100
(64∗64∗32)∗100
维度变为:
128
∗
100
128*100
128∗100
DNN2:
100
∗
10
100*10
100∗10
维度变为:
128
∗
10
128*10
128∗10 (10为最后分类时类别的个数)
softmax:
128
∗
10
128*10
128∗10 将输出结果压缩到0-1之间,得到概率值。
(省去了RELU层,RELU不改变维度和尺寸,只是加入了非线性变化的作用)

参考文献:
https://blog.csdn.net/v_JULY_v/article/details/51812459















 6535
6535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









