







_11LeetCode代码随想录算法训练营第十一天-C++队列的应用 | 239.滑动窗口最大值、347.前K个高频元素
- 239.滑动窗口最大值
- 347.前K个高频元素
239.滑动窗口最大值
代码随想录地址:https://programmercarl.com/0239.%E6%BB%91%E5%8A%A8%E7%AA%97%E5%8F%A3%E6%9C%80%E5%A4%A7%E5%80%BC.html
题目
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 。
示例 1:
输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7
示例 2:
输入:nums = [1], k = 1
输出:[1]
提示:
- 1 <= nums.length <= 1 0 5 10^5 105
- - 1 0 4 10^4 104 <= nums[i] <= 1 0 4 10^4 104
1 <= k <= nums.length
整体思路
要实现一个单调递减队列:
对于滑动窗口的滑动,移除前面的元素,加入后面的元素。当移除前面的元素时,如果当前这个元素等于队头元素,那么就出队;当加入后面的元素时,如果队尾的元素小于这个元素,那么就将队尾元素出队,直到队尾元素小于这个元素时,将这个元素入队。这样队首元素即为当前滑动窗口的最大值。
这样的队列维护了每次滑动窗口的最大值信息,而且不用存储滑动窗口所有的值,就挺好的。
代码
/*
* @lc app=leetcode.cn id=239 lang=cpp
*
* [239] 滑动窗口最大值
*/
// @lc code=start
class Solution {
private:
class myQuene
{
private:
deque<int> dq;//这是一个双向队列,可以从队首队尾都可以作为入口和出口
public:
void push(int data)
{
//出队列的情况
while(!dq.empty() && data > dq.back())
dq.pop_back();
dq.push_back(data);
}
void pop(int data)
{
//入队列的情况
if(!dq.empty() && dq.front() == data)
dq.pop_front();
}
int front()
{
return dq.front();
}
};
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
vector<int> res;
myQuene mq;
//首先将前k个元素入队列
for(int i = 0; i < k; i++)
{
mq.push(nums[i]);
}
//将第一个滑动窗口的最大值存起来;
res.push_back(mq.front());
for(int i = k; i < nums.size(); i++)
{
mq.pop(nums[i-k]);
mq.push(nums[i]);
res.push_back(mq.front());//将当前滑动窗口的最大值存储起来
}
return res;//返回结果
}
};
// @lc code=end
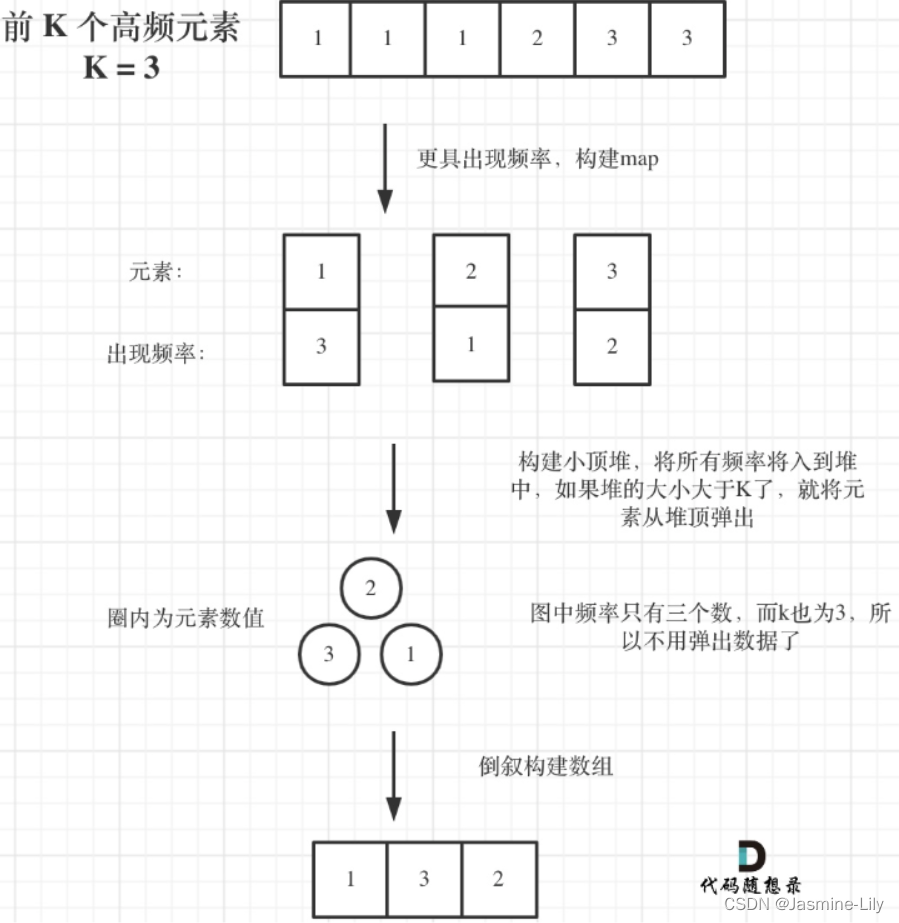
347.前K个高频元素
代码随想录地址:https://programmercarl.com/0347.%E5%89%8DK%E4%B8%AA%E9%AB%98%E9%A2%91%E5%85%83%E7%B4%A0.html
题目
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
示例 2:
输入: nums = [1], k = 1
输出: [1]
提示:
- 1 <= nums.length <= 1 0 5 10^5 105
k的取值范围是[1, 数组中不相同的元素的个数]- 题目数据保证答案唯一,换句话说,数组中前
k个高频元素的集合是唯一的
**进阶:**你所设计算法的时间复杂度 必须 优于 O(n log n) ,其中 n 是数组大小。
优先级队列
优先级队列对外接口只是从队头取元素,从队尾添加元素。
优先级队列内部元素是自动依照元素的权值排列。
排列的方式:缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
堆
堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
整体思路
为什么不用快排?
使用快排要将map转换为vector的结构,然后对整个数组进行排序, 而这种场景下,我们其实只需要维护k个有序的序列就可以了,所以使用优先级队列是最优的。
使用大顶堆还是小顶堆?
使用大顶堆的话,每次弹出的是最大值,然后大顶堆里面存储的就不是频率为前k的元素;使用小顶堆的话,每次弹出的是最小值,然后小顶堆里面存储的就是频率为前k的元素。
代码
/*
* @lc app=leetcode.cn id=347 lang=cpp
*
* [347] 前 K 个高频元素
*/
// @lc code=start
class Solution {
public:
class myCompare{
public:
bool operator()(pair<int,int>& left,pair<int,int>& right)
{
return left.second > right.second;
}
};
vector<int> topKFrequent(vector<int>& nums, int k) {
//统计元素出现的频率
unordered_map<int, int> map;
for(int data : nums)
{
map[data]++;
}
//对频率进行排序
//这里的第三个参数必须是类,不能是函数
priority_queue<pair<int, int>, vector<pair<int, int>>, myCompare> priQueue;
for(auto it = map.begin(); it != map.end(); it++)
{
priQueue.push(*it);
if(priQueue.size() > k)
priQueue.pop();
}
//取出元素
vector<int>res;
for(int i = 0; i < k; i++)
{
res.push_back(priQueue.top().first);
priQueue.pop();
}
return res;
}
};
// @lc code=end
















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











