







Evidential Deep Learning to Quantify Classification Uncertainty
摘要
确定性神经网络已被证明:对于广泛的机器学习问题,确定性神经网络能够学习到有效的预测器。然而,由于标准的方法是训练网络以最小化预测损失,合成的模型仍然不知道其预测置信度。与通过权重不确定性间接推断预测不确定性的贝叶斯神经网络相比时,我们提出使用主观逻辑理论对其进行显式建模。通过在类概率上放置狄利克雷分布,我们将神经网络的预测视为主观意见,并学习从数据中收集导致这些意见的证据的函数。一个多类分类问题的预测器是另一个狄利克雷分布,其参数由一个神经网络的连续输出设置。我们提供了一个初步的分析,我们的新的损失函数的特性如何驱动改进的不确定性估计。我们观察到,我们的方法在检测分布外查询和对抗对抗性扰动的耐力方面取得了前所未有的成功。
1 介绍(待补充)
2 使用softmax建模类概率的不足(待补充)
3 不确定性和证据理论(部分内容)
Dempster–Shafer Theory of Evidence(DST)是贝叶斯理论对主观概率[7]的推广。它将信念质量分配给一个识别框架的子集,子集表示排他的可能状态的集合,例如一个样本的可能的类标签。一个信念质量可以被分配给框架的任何子集,包括整个框架本身,它表示这样的信念——真理可以是任何可能的状态,例如,任何类标签都是等可能的。换句话说,通过将所有的信念质量分配到整个框架中,一个人可以表达“我不知道”作为对超出可能状态的事实的意见[14]。主观逻辑Subjective Logic (SL)将在识别框架上信念分配的DST概念形式化为狄利克雷分布[14]。因此,它允许人们使用证据理论的原则来通过一个明确定义的理论框架来量化信念的质量和不确定性。更具体地说,SL考虑了K个互斥单例(例如,类标签)的框架,通过为每个单例K=1,…,K提供一个信念质量bk,并提供一个总体的不确定性质量u。这些K+1的质量值都是非负的,总和为1,即,

其中对于k=1,…,K,bk≥0并且u≥0,单例k的信念质量bk是利用单例的证据计算的。设ek≥0为第k个单例的证据,然后计算信念bk和不确定性u
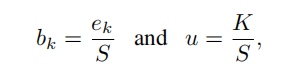
其中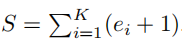
请注意,不确定性与总证据成反比。当没有证据时,每个单例的信念为零,不确定性为1。与贝叶斯建模命名法不同,我们将证据称为从数据中收集到的支持量的度量,以有利于样本被分类为某一类。一个信念质量分配,即主观意见,对应于一个参数为αk=ek+1的狄利克雷分布。也就是说,使用bk=(αk−1)/S可以很容易地从相应的狄利克雷分布参数中得到主观意见,其中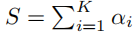
被称为狄利克雷强度。一个标准的神经网络分类器的输出是对每个样本的可能类的概率分配。然而,在证据上参数化的狄利克雷分布表示每个这样的概率分配的密度;因此,它模拟了二阶概率和不确定性[14]。
狄利克雷分布是概率质量函数(probability mass function,pmf)p的可能值的一个概率密度函数(probability density function,pdf)
4 Learning to Form Opinions(公式太多省略)
实现过程,具体讲了损失函数的选择
5 实验(待补充)
数据集: MNIST and CIFAR10
- 预测不确定性性能
指标:准确性,概率分布函数随熵值的变化曲线(预测的熵值) - 在对抗样本上的准确率和不确定性
6 相关工作
学习不确定性感知预测器的历史与现代贝叶斯机器学习方法的出现是同步的。沿着这条线的一个主要分支是高斯过程(GPs)[29],它在做出准确的预测方面和为其预测的不确定性提供可靠的测量方面都很强大。它们的预测能力已经在不同的环境下得到了证明,如迁移学习[15]和深度学习[32]。他们的不确定性计算的价值奠定了主动学习[12]的水平。由于GPs是非参数模型,它们没有确定性的或随机的模型参数的概念。GPs在不确定性建模中的一个显著优势是,其预测的方差可以以封闭的形式计算,尽管它们能够将广泛的非线性预测函数拟合到数据。因此,它们是普遍的预测因器[31]。
预测不确定性建模的另一个研究方向是利用模型参数的先验分布(当模型是参数化的时),推断后验分布,并使用合成的后验预测分布的高阶矩来解释不确定性。BNN也属于这类[25]。BNN建立在解释参数不确定性的基础上,通过应用突触连接权值的先验分布。由于连续层之间的非线性激活,计算权重的最终后验是棘手的。专门为BNN的可伸缩推理而定制的近似技术的改进,如变分贝叶斯Variational Bayes (VB) [2, 6, 27, 23, 9]和随机梯度蒙特卡罗Stochastic Gradient Hamiltonian Monte Carlo (SG-HMC) [3],是一个活跃的研究领域。尽管BNN的预测能力巨大,但其后验预测分布仍不能以封闭的形式计算。目前的技术是用蒙特卡罗积分近似后验预测密度,这给不确定性估计带来了显著的噪声因子。与此方法相比,我们绕过了预测器的不确定性来源,通过确定性神经网络从数据中学习超参数,直接建模狄利克雷后验。
7 结论
在这项工作中,我们设计了一个用于分类的预测分布,通过放置一个狄利克雷分布到类概率上,并分配神经网络输出到狄利克雷分布的参数。我们通过最小化相对于 L2-Norm loss的贝叶斯风险将这个预测分布拟合到数据中,L2-Norm loss由一个信息理论的复杂性项正则化的。所得到的预测器是类概率上的狄利克雷分布,它提供了一个比标准softmax输出的深度网络的点估计更详细的不确定性模型。我们从证据推理的角度来解释这个预测器的行为,通过建立从其预测到主观逻辑的信念质量和不确定性分解的联系。我们的预测器在两个不确定性建模基准中显著提高了最新的技术水平:i)检测分布外查询,以及ii)对抗对抗性扰动的耐力。

















 2367
2367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









