






1.首先要有krita,其次需要krita_ai_diffusion插件:
Releases · Acly/krita-ai-diffusion
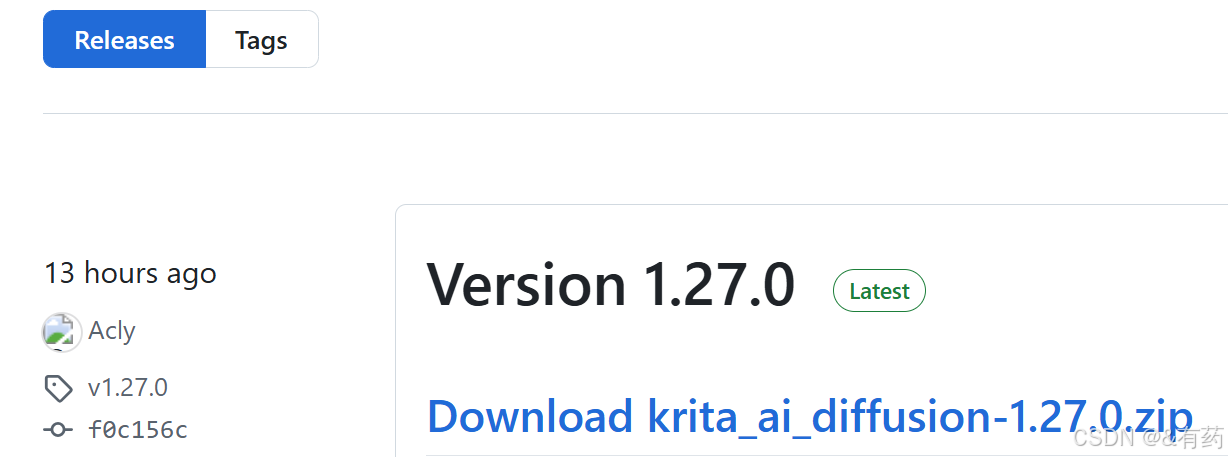
点击下载,版本随便,我选择的是1.26.0,不需要解压zip文件。打开krita-新建图像,建立完成之后在工具栏选择工具-脚本-从文件导入python插件
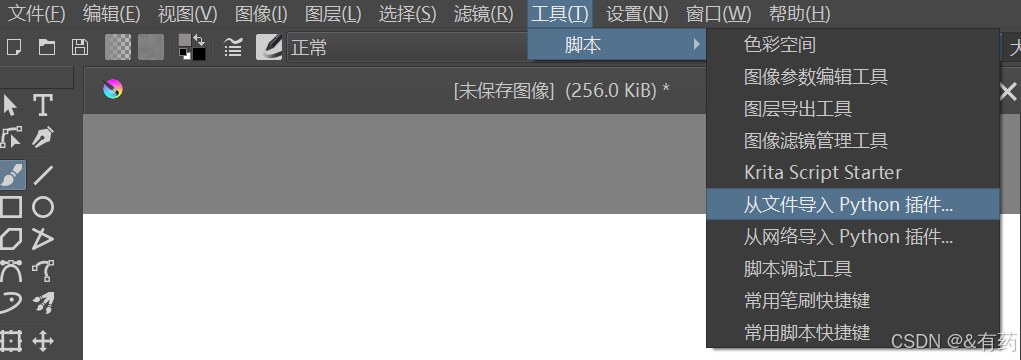
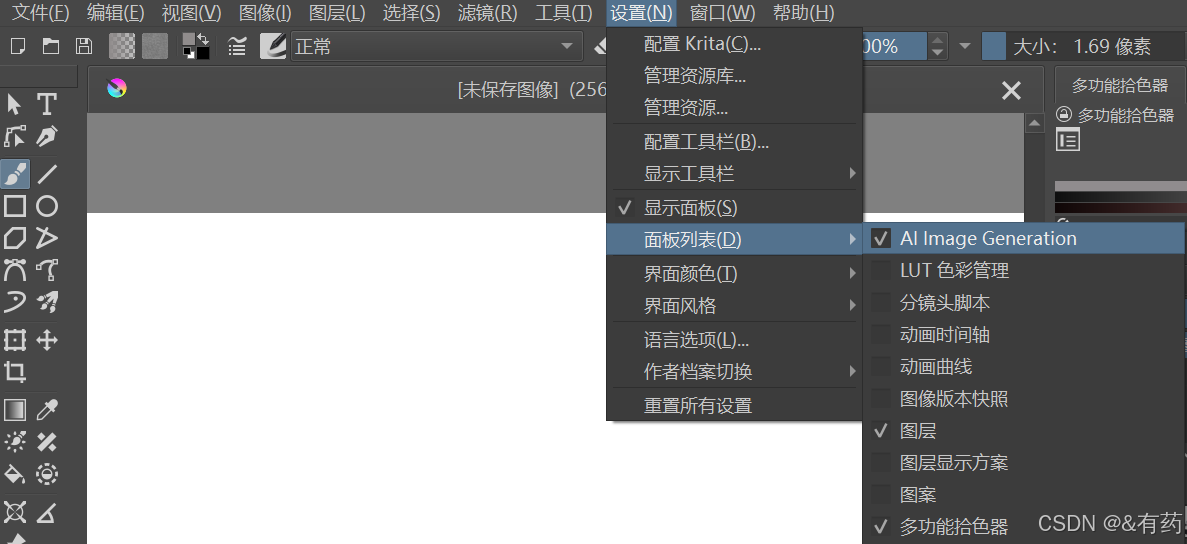
按下图继续设置:勾选AI Image Generation
重新启动krita
2.ComfyUI
在krita安装目录下创建一个文件夹ai_diffusion
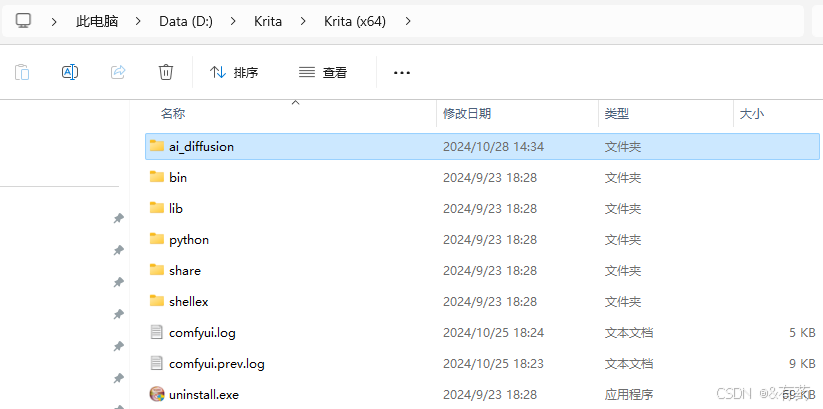
win+r 输入cmd打开命令行界面,进入到ai_diffusion文件夹下:
进入ComfyUI官方网站
复制git链接,或者下载zip文件解压到ai_diffusion目录, 在终端输入
D:\Krita\Krita (x64)\ai_diffusion>git clone https://github.com/comfyanonymous/ComfyUI.git
此时会在ai_diffusion目录下生成ComfyUI文件:
进入Python Releases for Windows | Python.org,下载:
把下载好的python-3.11.9-embed-amd64.zip复制到ai_diffusion文件夹下,并解压,重命名为python:
进入网站:Index of /,然后下载get-pip.py文件,把这个文件放到python文件夹下:
接着在终端输入 .\python\python.exe .\python\get-pip.py
D:\Krita\Krita (x64)\ai_diffusion>.\python\python.exe .\python\get-pip.py继续打开python文件夹中的python311._pth文件,在文件中添加语句Lib\site-packages和../ComfyUI
接着在终端输入命令,安装ComfyUI所需要的依赖包:
D:\Krita\Krita (x64)\ai_diffusion>.\python\Scripts\pip.exe install -r .\ComfyUI\requirements.txt
如果安装太慢的话,在上述命令中添加镜像源 -i https://pypi.tuna.tsinghua.edu.cn/simple
D:\Krita\Krita (x64)\ai_diffusion>.\python\Scripts\pip.exe install -r .\ComfyUI\requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple打开网站:ComfyUI Setup · Acly/krita-ai-diffusion Wiki
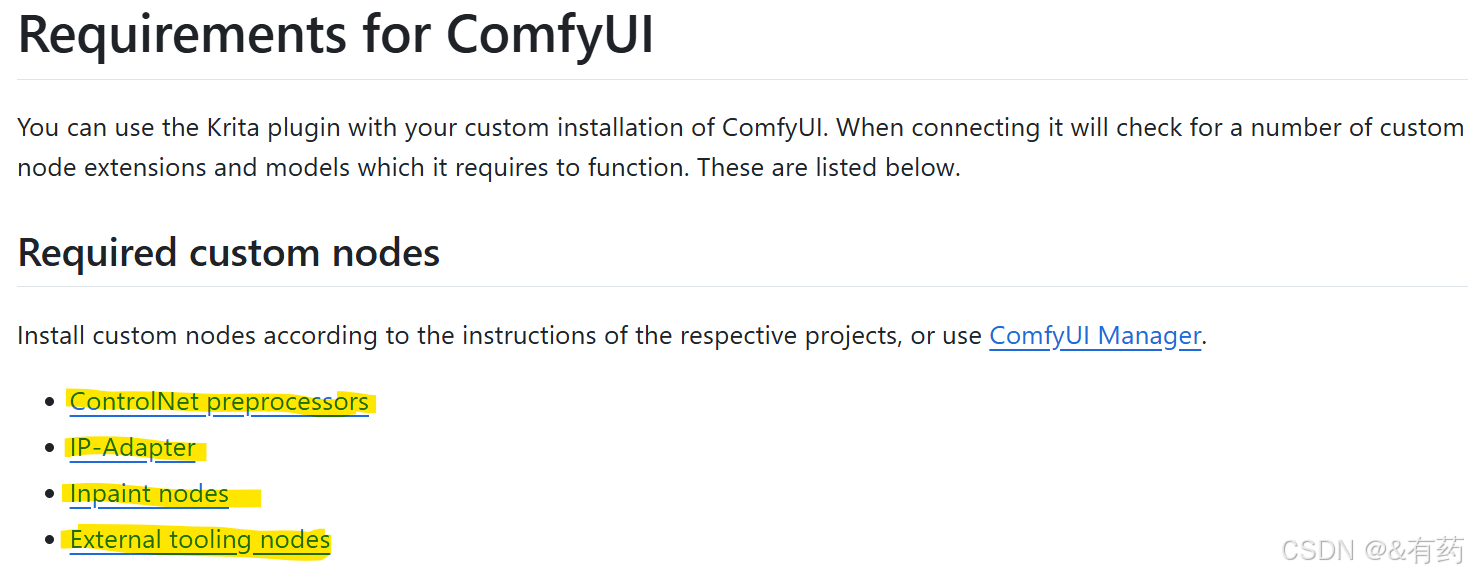
这4个节点,比如说第一个,点进去,复制项目地址,然后在终端里进入到ComfyUI的custom_nodes文件夹:
D:\Krita\Krita (x64)\ai_diffusion>cd ComfyUI\custom_nodes
D:\Krita\Krita (x64)\ai_diffusion\ComfyUI\custom_nodes>git clone https://github.com/Fannovel16/comfyui_controlnet_aux.git此时,你会在custom_node文件夹下看到
这是一个的,其余三个按照这个步骤重复,节点就安装好了,这四个是基本的,以后你还会接触到其他的节点,安装方法和上面描述的一样。------------还有一种方法,就是先安装ComfyUI-Manager(这也是个节点,图中标红那个),安装方法和上面的步骤也一样,之后就可以使用ComfyUI-Manager来安装其他你需要的节点了(方便点),具体方法后面介绍
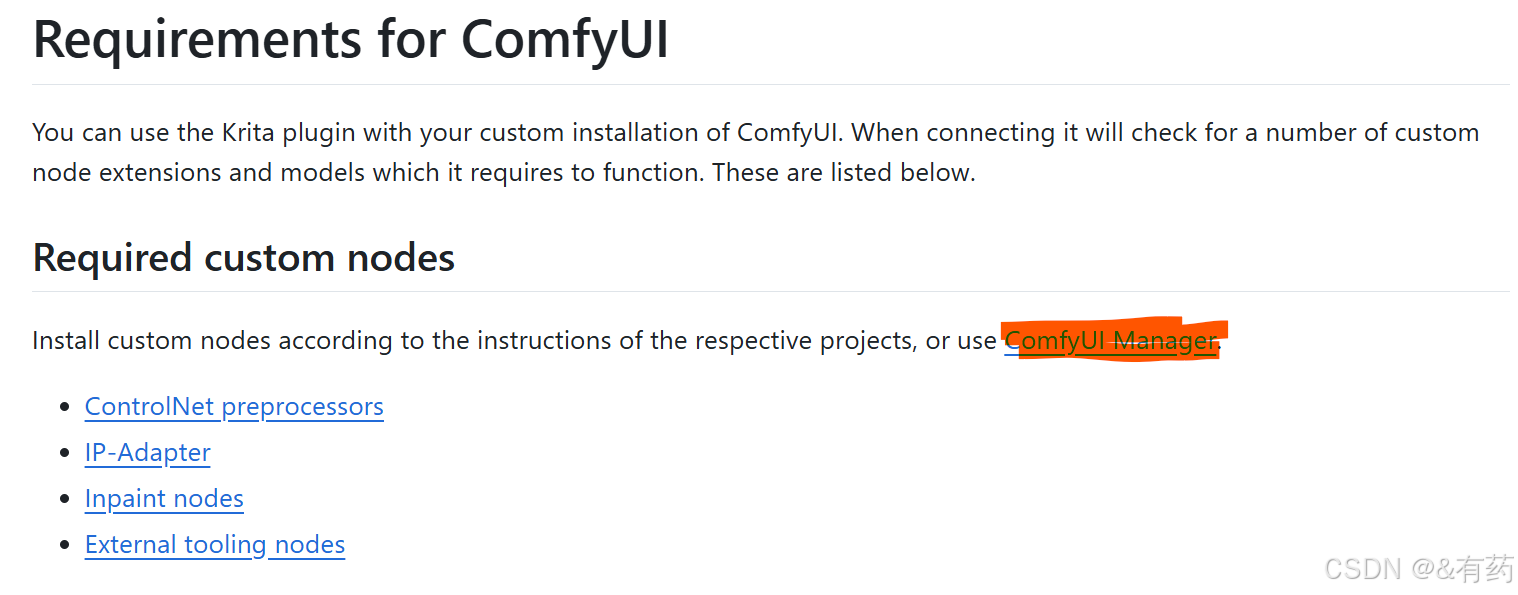
接着安装模型:
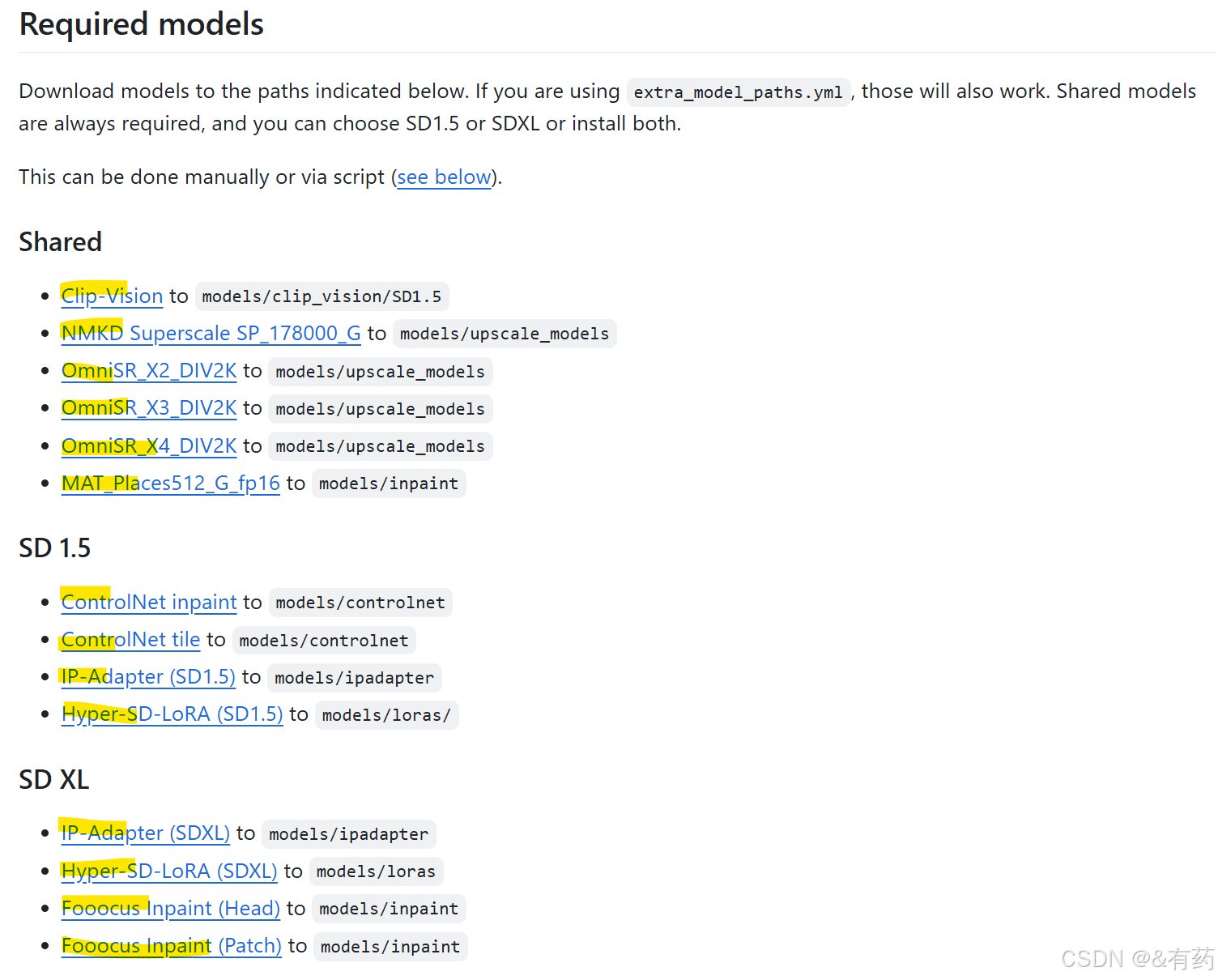
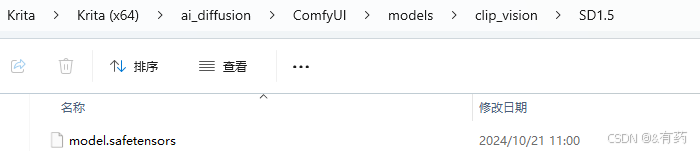
上图中标记的模型,全部下载,点进去,将下载好的模型放到对应的文件夹下,就是上面模型后面的那句话,比说第一个模型后面显示 to models/clip_vision/SD1.5 , 那就把下载的模型放到models/clip_vision/SD1.5下(这个models文件夹在ComfyUI目录下,以此类推,具体的路径就是ComfyUI/models/clip_vision/SD1.5),如果没有对应的文件夹,就创建一个,就像这样:
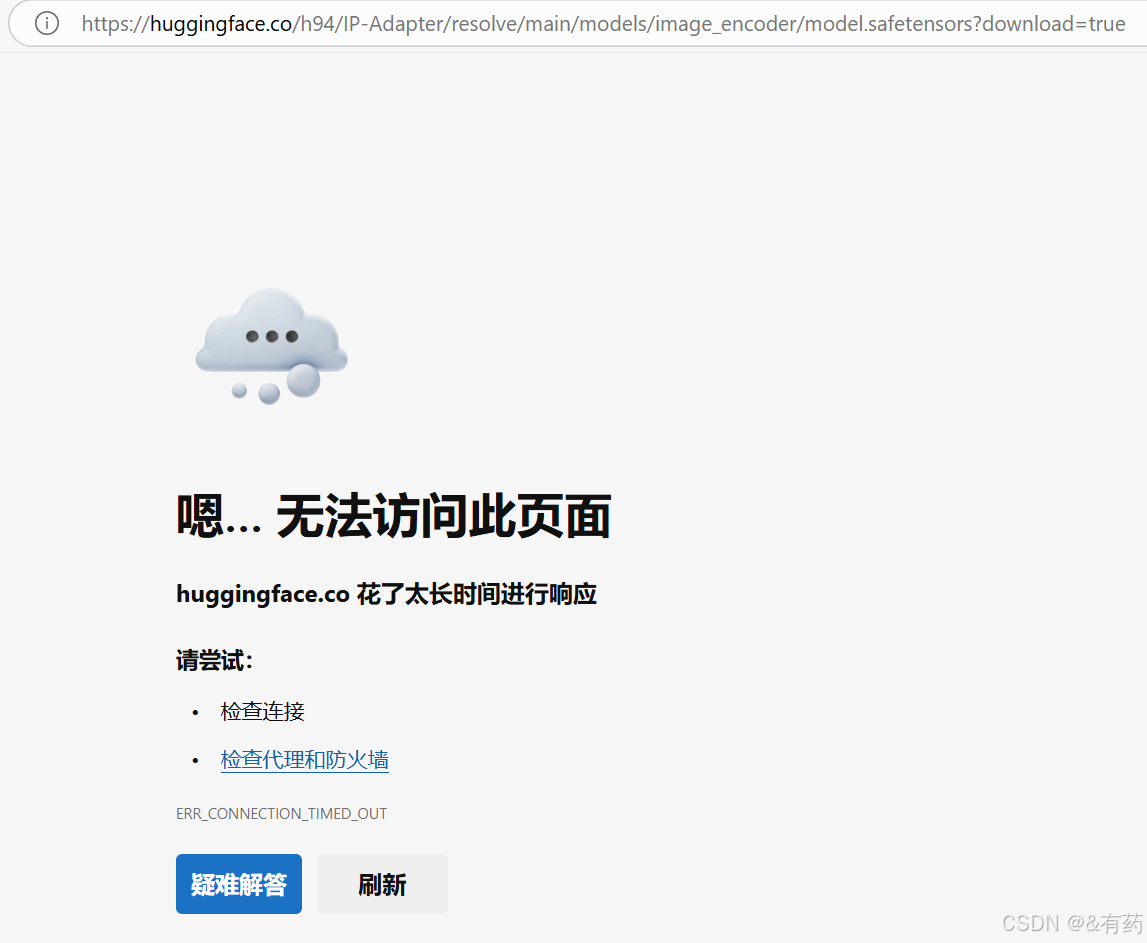
但是,一般情况下是不能下载的,无法访问页面的,此时,修改浏览器中的网址,把huggingface.co改为hf-mirror.com,就可以下载成功了
接下来继续安装:
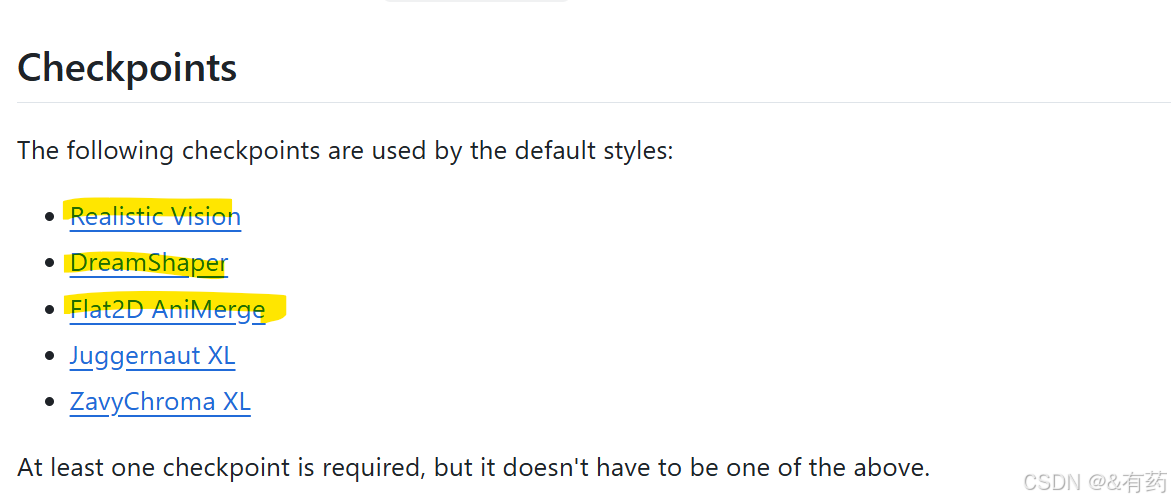
上面的模型,也是点击下载,看情况,你想装几个模型都行,这几个模型适用的类型不同,适用于艺术风格或者动画风格,下载好的模型放到models/checkpoints文件夹下,是这样的路径:
![]()
此时,ComfyUI就安装完成了,在终端输入命令连接ComfyUI:
D:\Krita\Krita (x64)\ai_diffusion>.\python\python.exe .\ComfyUI\main.py运行之后,会在界面显示:
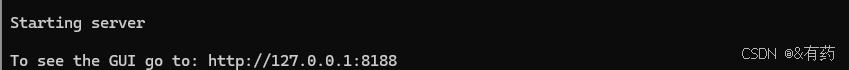
在浏览器中输入http://127.0.0.1:8188,显示ComfyUI界面之后,连接成功,接着打开krita:
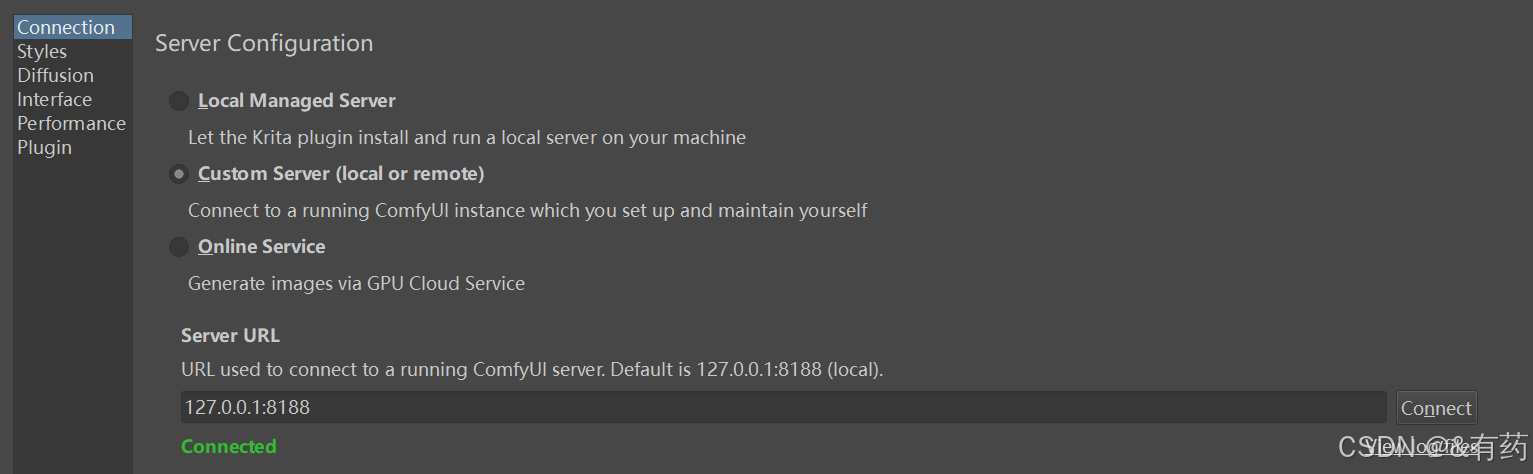
按照图中的,点击connet,就会连接成功
到这一步还没完,继续下载模型:进入网站lllyasviel/ControlNet-v1-1 at main
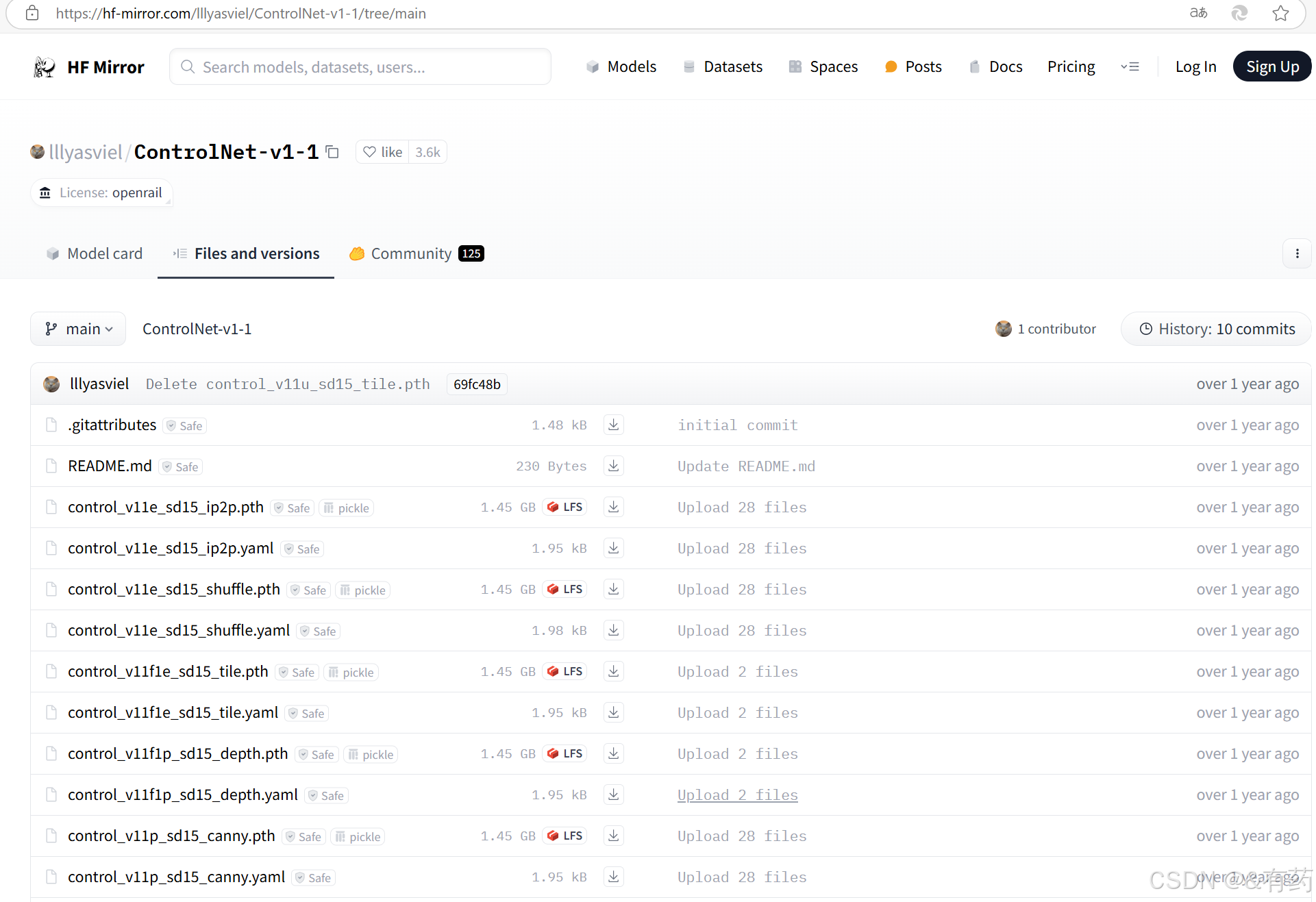
这些模型是ControlNet,图像处理类的模型,搭配SD模型来使用,可以把他理解为插件,看你需要,你可以下载,比如:control_v11p_sd15_canny.pth和control_v11p_sd15_canny.yaml(pth和yaml文件要一起下载),把模型放到models/controlnet文件夹下
上面的ControlNet中的图像处理方法(Scribble, Line art, Canny edge, Pose, Depth, Normals, Segmentation, +more)可以使用ComfyUI-Advanced-ControlNet节点调用(这回通过ComfyUI-Manager来安装这个节点)
首先安装上面遗留的ComfyUI-Manager节点,命令是一样的,终端进入到custom_nodes文件目录下,运行命令:
D:\Krita\Krita (x64)\ai_diffusion\ComfyUI\custom_nodes>git clone https://github.com/ltdrdata/ComfyUI-Manager.git此时ComfyUI-Manager就安装成功了,运行ComfyUI界面之后,你会在ComfyUI界面上发现多出来的红圈标注的Manager,然后打开Manager
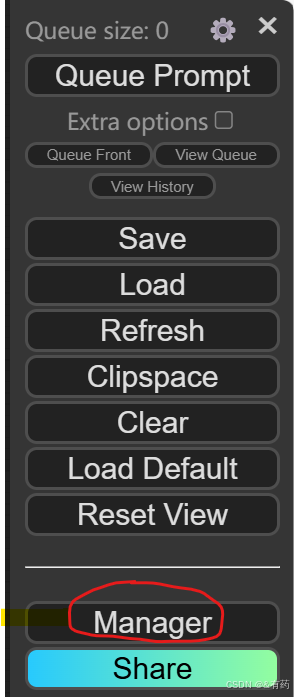
打开Custom Node Manager
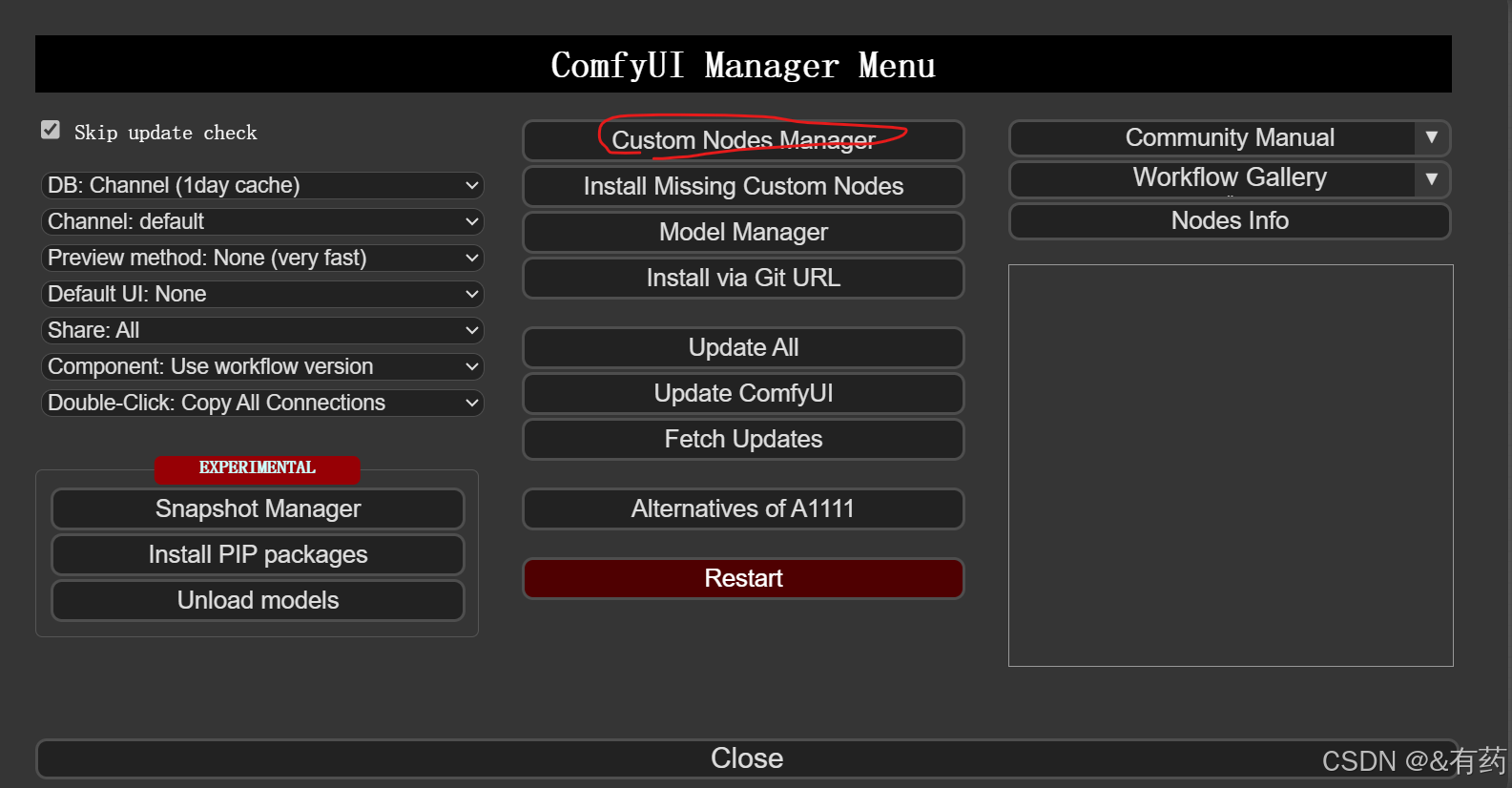
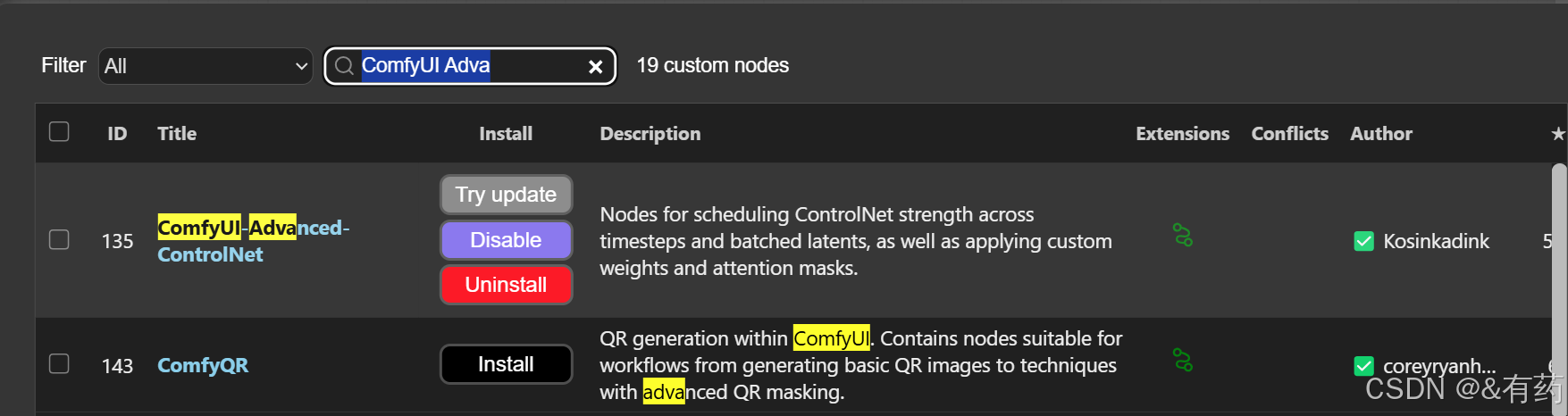
输入你要安装的节点,就可以安装了,比如:ComfyUI-Advanced-ControlNet以及ComfyUI_essentials(这两个节点很有用),直接点击安装就可以:
到此,ComfyUI就部署完成了
----------------------------------------
除此之外,我也安装了DynamicrafterWrapper + ToonCrafter,这两个是视频,动态画生成的模型,给两张图像,然后可以在两张图像之间生成许多帧,这两个模型也可以部署在ComfyUI上,也可以运行成功,只不过这两个模型需要的显存太大了,我8G的显存,根本不行,如果你们的显卡内存很大的话,就可以运行这两个模型,具体可以自己看看这两个模型,如果你需要,可以接着安装这两个模型
3.ComfyUI-DynamicrafterWrapper
安装流程是一样的,进入网站:
kijai/ComfyUI-DynamiCrafterWrapper: Wrapper to use DynamiCrafter models in ComfyUI
然后在custom_nodes文件夹下git项目
D:\Krita\Krita (x64)\ai_diffusion\ComfyUI\custom_nodes>git clone https://github.com/kijai/ComfyUI-DynamiCrafterWrapper.git此时,你会在custom_nodes目录下看见这个项目文件夹
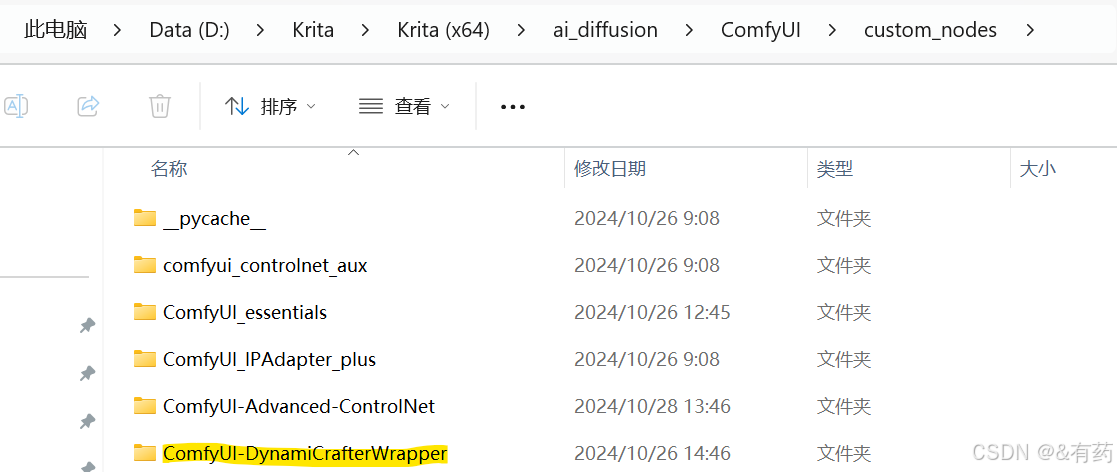
终端进入到ComfyUI-DynamiCrafterWrapper这个目录下,安装需要的依赖包,只不过原来安装ComfyUI的时候已经安装过一些依赖包了,打开ComfyUI-DynamiCrafterWrapper文件夹下的requirements.txt文件看看,有的包是不是在安装ComfyUI的时候已经安装过了,把已经安装过的依赖包注释掉(就是重复的),把xformers这个库也给注释掉,后面单独安装,运行下面的命令:
D:\Krita\Krita (x64)\ai_diffusion>.\python\python.exe install -r .\ComfyUI\custom_nodes\ComfyUI-DynamiCrafterWrapper\requirements.txtxformers是一个加速transformer模型的工具,安装这个库的时候注意和pytorch版本要对应,我的pytroch版本是2.4.1+cu12.4,对应的xformers的版本是0.0.28.post1,下载链接如下:
download.pytorch.org/whl/cu124/xformers/
选择这个文件安装:xformers-0.0.28.post1-cp311-cp311-win_amd64.whl,把这个文件放在python目录下
D:\Krita\Krita (x64)\ai_diffusion>.\python\python.exe install .\python\xformers-0.0.28.post1-cp311-cp311-win_amd64.whl一般情况下不会有错,但是安装各种库的时候可能会报错,上网可以查查,太细节的东西,我就不叙述了。
接着安装需要的模型,进入网站:
Kijai/DynamiCrafter_pruned at main
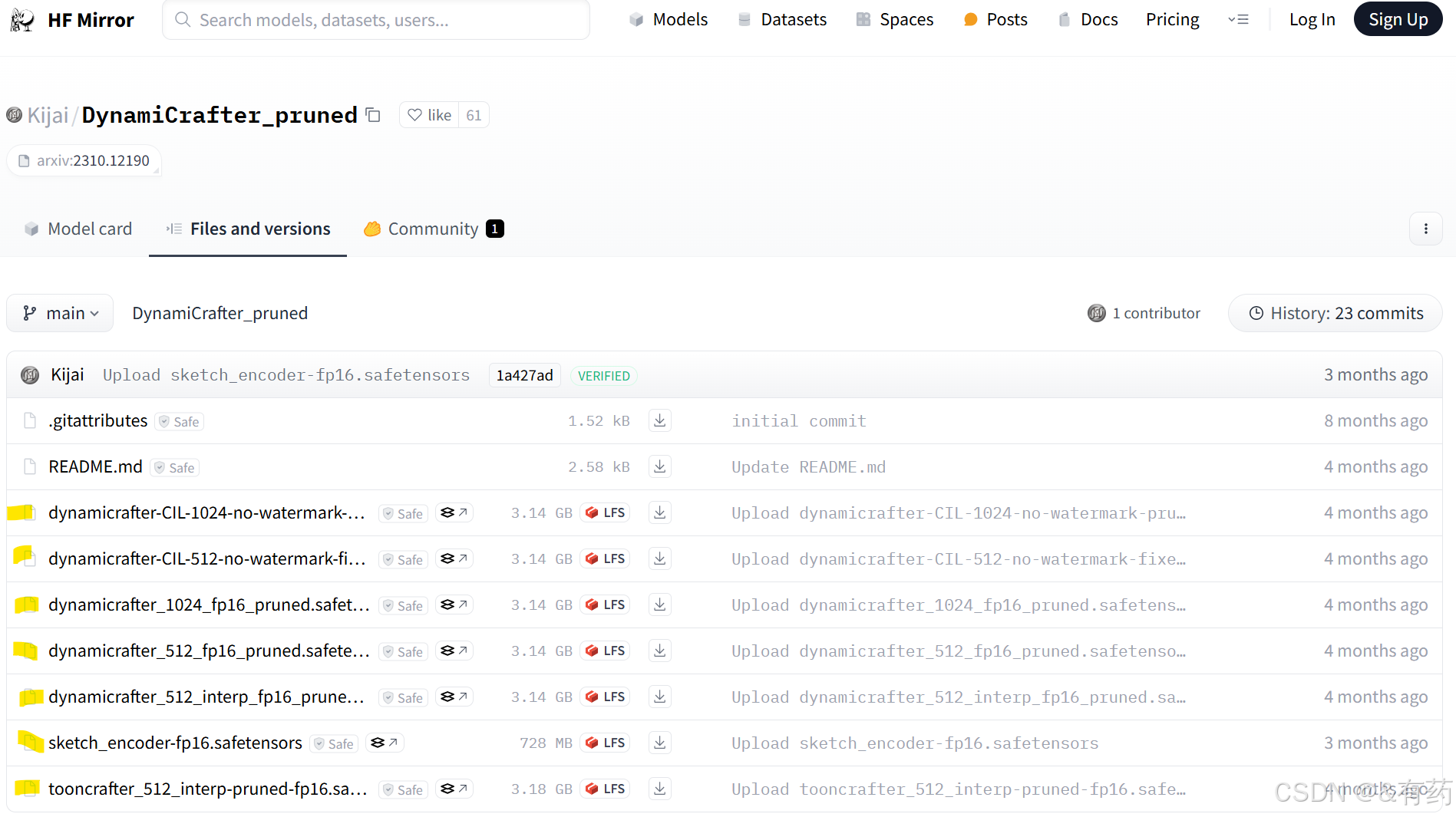
这些模型你都可以下载,下载之后把这些模型放到ComfyUI/models/checkpoints目录下,但是其中的tooncrafter_512_interp-pruned-fp16.safetensors模型需要放在ComfyUI/models/checkpoints/dynamicrafter目录下
接着下载两个模型,一个是stable-diffusion-2-1-clip-fp16.safetensors,一个是CLIP-ViT-H-fp16.safetensors,这两个模型是文本编码,嵌入到图像中的,下面是两个模型的下载链接:
clip/stable-diffusion-2-1-clip-fp16.safetensors · fofr/comfyui at main
CLIP-ViT-H-fp16.safetensors · Kijai/CLIPVisionModelWithProjection_fp16 at main
stable-diffusion-2-1-clip-fp16.safetensors模型放到ComfyUI/models/clip目录下,CLIP-ViT-H-fp16.safetensors放到ComfyUI/models/clip_vision目录下
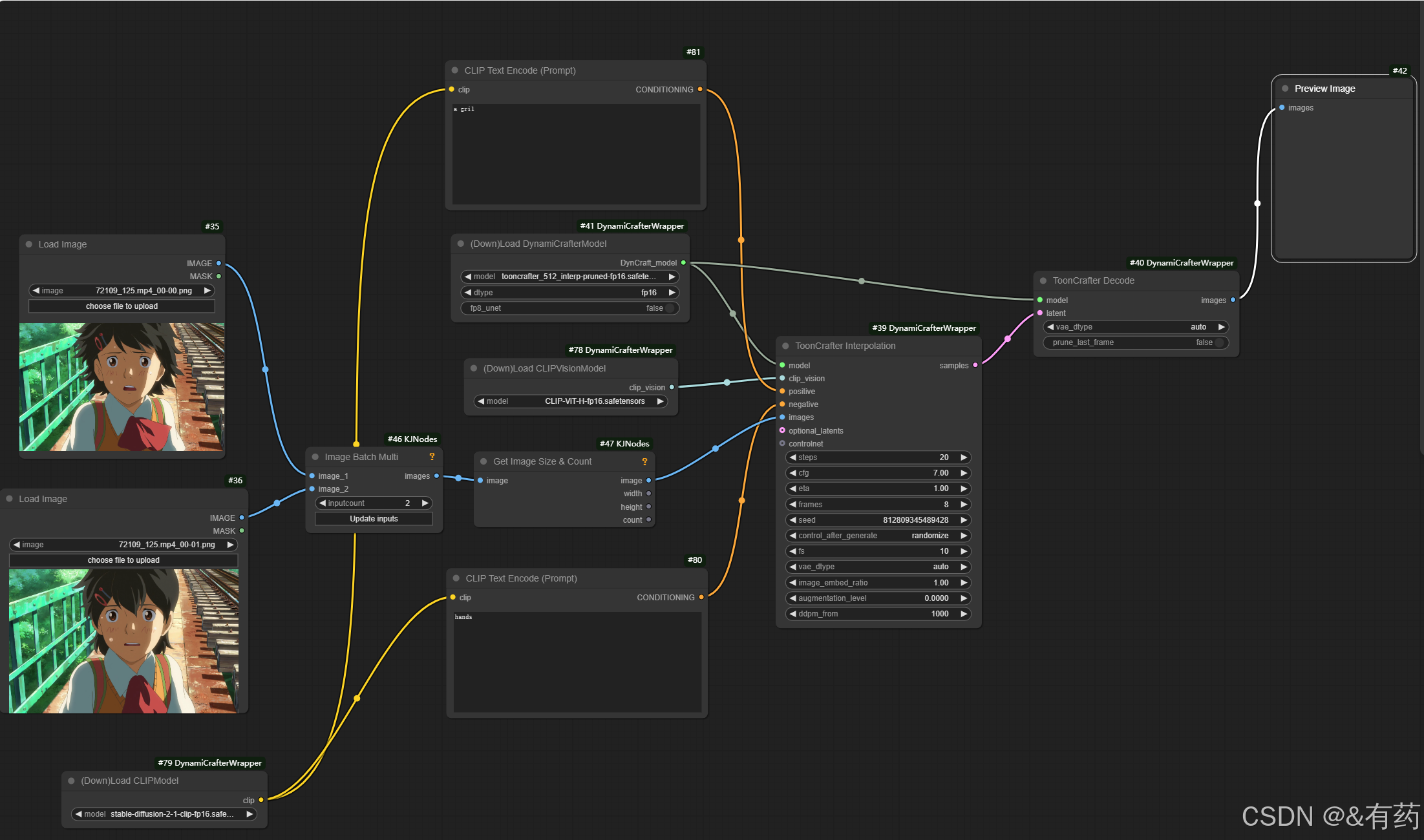
ComfyUI-DynamicrafterWrapper模型,就部署完成了,其中是自带ToonCrafter模型的,按照下图的节点流程,你应该可以生成图片以及视频,这个模型虽然是裁剪过的,但是对显存还是有要求的,不然运行不了
4.ComfyUI-ToonCrafter
这个模型是独立出来的,单独使用,用于动态图像以及视频的生成,安装流程也和上面的一样,进入网站,复制链接:
ccAIGODLIKE/ComfyUI-ToonCrafter: This project is used to enable ToonCrafter to be used in ComfyUI.
然后在custom_nodes文件夹下git项目
D:\Krita\Krita (x64)\ai_diffusion\ComfyUI\custom_nodes>git clone https://github.com/AIGODLIKE/ComfyUI-ToonCrafter.gitComfyUI-ToonCrafter也是需要安装依赖包的,看一下自己以前安装的依赖包,看看是否重复,如果重复的话,注释掉,然后再安装requirements.txt文件。(安装方法和上面介绍的一样)
需要下载的模型:tooncrafter_512_interp-pruned-fp16.safetensors模型,就是上面提到的模型,把这个模型放到ComfyUI-ToonCrafter\ToonCrafter\checkpoints\tooncrafter_512_interp_v1
目录下,具体的路径就是ComfyUI\custom_nodes\ComfyUI-ToonCrafter\ToonCrafter\checkpoints\tooncrafter_512_interp_v1,如果看不到对应的文件夹,就创建一个。
在跑模型的时候,你会遇到模型参数不匹配的问题,直接报错,解决方法:找到ComfyUI-ToonCrafter\ToonCrafter\scripts\evaluation文件夹下的funcs.py文件,打开这个文件,找到141行:
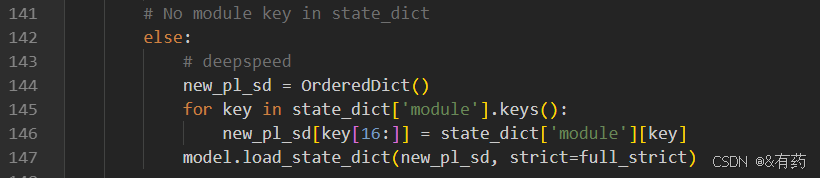
原来代码是注释掉的,把这段代码的注释去掉,改成和上图一样就行。此时运行就不会报错了。
之后,参照官网给的示例,这个直接搬过来,在你的ComfyUI下运行,应该可以运行吧,我的是内存不够,你们显存高的,应该可以运行成功。
-----------------------------------------------------
5.打包分享项目
按照这个流程安装的话,如果你安装部署成功了,你可以压缩ai_diffusion这个总的项目文件,压缩成ai_diffusion.zip(文件可能会很大,我的已经40G了) , 这样你可以把这个压缩包分享给身边的任何人,然后对方在对应目录下(也可以是任意目录)解压这个压缩包,在终端输入命令就可以直接运行,不需要对方配置环境。(应该是这样)
-------------------------------------------------------
6.到此,全部结束

















 1546
1546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









