







一、前言
仅代表个人见解,如有错误,纯属我个人问题!!!
如有不对,还请不吝赐教!
方法
💡 Tips:目前由于个人技术受限+见识浅薄,个人操作下来机器学习方法性能效果好一点(因为样本<灾害点>数量少导致)
- 常见的机器学习方法-->针对灾害点
点(即样本大小为1*1)上的数据进行训练预测 - 深度学习方法-->针对灾害
点+周边(即比如说7*7的样本大小)环境进行预测
数据
- 灾害点数据
- 各类因子数据(如DEM、坡度、坡向等等) 不排除因子越多越好,当然有的有因子加了也可能会导致准确度变差
流程
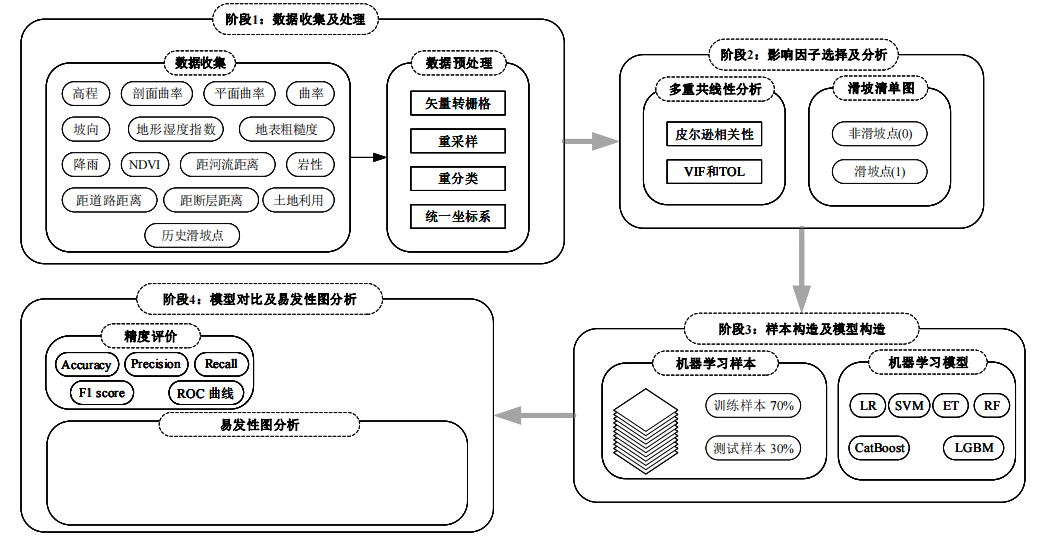
下面进行详细讲解
二、具体步骤
1.数据准备
- 收集各种数据 无需多言
- 将以上收集到的各种数据,统一分辨率,如 30 m * 30 m , 90 m * 90 m ,统一坐标系 注:矢量数据也要转成栅格数据
- 灾害点数据,暂时是不用转成栅格
2.数据预处理
此块是将 前面前面准备好的各种因子数据,由于 它们的 单位 什么的 还有就是属性值什么的都不一样,因此需要将数据进行转换
2.1 影响因子数据处理
!!!切记最后的一定影响因子是只有里面的数据不一样,其它均一样--地理参考、分辨率,tif的大小等
转换的常见方法有 直接重分类、频率比、信息量等
频率比 和 信息量 都是在 重分类 的基础之上进行的
重分类的目的是将拥有 某一条件 的地物分成一类 如:将高程0~200(注:我随意选的规则,打胡乱说的)的划分为平原
以下进行重分类展示,频率比和信息量 建议百度 B站上也有视频 可直接搜 易发性评价
将前期准备的因子数据按照一定规则进行重分类
如以下,都是我自己找的别人论文的重分类的规则

重分类完一般是将分类的结果值命名为数字 如 1、2、3、... 如0~200为1、200~400为2
(但是出图的时候记得修改标注 如将1改回为0~200)
基于以上步骤你就可以得到 各个因子数据 因子的数据均是由 1 2 3 4 5 .... 构成
信息量其实就是和在不同分区中,和灾害点建立关系。
2.2 灾害点数据处理
由于机器学习/深度学习均需要正、负样本进行训练 而这里我们只有灾害点的数据(即为正样本) 无负样
现在绝大多数论文所采用的方法 就是 随机采样负样本
具体方法为:
在灾害点的附近生成一点范围大小(如1km或者500m 视情况而定)的缓冲区,然后在缓冲区外&研究区内 生成相同灾害点数量的随机点 将这些随机点 命为 负样本点 相同灾害点数量是因为要照顾 正负样本均衡
而后将灾害点的属性赋值为 1 ,非灾害点(负样本点)赋值为 0
2.3 多值提取至点
利用arcgis 多值提取至点工具 ,将因子数据提取到灾害点和非灾害点的属性表上
后续如果是机器学习的话,用属性表里面的excel进行训练就行了
shp的属性表转excel 可以用表转EXCEL工具实现
3 影响因子筛选
因此有的因子会有共线性会影响结果,用共线性分析以下更为严谨
相关性分析
共线性分析
将前后保存的excel 数据表的表头如下:

以下代码用的皮尔逊相关性分析、和VIF进行评价,一般来说VIF>10的值就要剔除,本文这里给定的阈值是5,请注意修改,这里实现了VIF值大于5则打印应删除的因子
import numpy as np
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.stats.outliers_influence import variance_inflation_factor
from statsmodels.tools.tools import add_constant
import re
# 计算VIF的函数
def calculate_vifs(dataframe):
X = add_constant(dataframe)
return pd.Series([variance_inflation_factor(X.values, i)
for i in range(X.shape[1])], index=X.columns)
# 移除高VIF值的变量的函数
def remove_high_vif_factors(dataframe, vif_threshold=5.0):
removed_factors = [] # 用于记录被移除的变量
while True:
VIFs = calculate_vifs(dataframe).drop('const')
max_vif = VIFs.max()
if max_vif <= vif_threshold:
break
factor_to_drop = VIFs.idxmax()
removed_factors.append(factor_to_drop) # 添加被移除的变量到列表
dataframe = dataframe.drop(columns=[factor_to_drop])
print(f"Removed {factor_to_drop} with VIF={max_vif:.2f}") # 打印被移除的变量
return dataframe, removed_factors
# 读取数据
df = pd.read_csv(r"./Landslide-susceptibility-mapping/数据集16个因子.csv")
factors = df[list(df.columns)[:-1]] # 选择您的自变量列
print(factors.columns)
# 移除高VIF值的变量,并获取被移除变量的列表
factors_with_low_vif, removed_factors_list = remove_high_vif_factors(factors, vif_threshold=7.0)
# 打印被移除的变量的列表
print("\n打印被移除的变量列表:")
print(removed_factors_list)
# 计算最终的VIF和TOL值
final_vifs = calculate_vifs(factors_with_low_vif).drop('const')
final_tols = 1 / final_vifs
# 创建结果表
results = pd.DataFrame({
'Factor': final_vifs.index,
'VIF': final_vifs.values,
'TOL': final_tols.values
})
# 打印结果表
print("VIF和TOL结果表:")
print(results)
results.to_excel('.\结果分析存储\VIF和TOL结果表.xlsx')
# 计算皮尔逊相关性矩阵
pearson_correlation_matrix = factors_with_low_vif.corr()
print("\n皮尔逊相关性矩阵:")
print(pearson_correlation_matrix)
# 如果需要将皮尔逊相关性矩阵保存到Excel文件
pearson_correlation_matrix.to_excel('.\结果分析存储\pearson_correlation_matrix.xlsx')
4 机器学习
就是将前期的excel,进行训练,预测
def parse_args():
parser = argparse.ArgumentParser(description="Train ML models Processes on data")
parser.add_argument("--feature_path", default='origin_data2/feature/', type=str)
parser.add_argument("--label_path", default='origin_data2/label/label1.tif', type=str)
parser.add_argument("--model", default='ModelRF', type=str)
args = parser.parse_args()
return args
def main():
data = pd.read_csv("数据集14个因子.csv")
X, y = data.iloc[:, :-1], data.iloc[:, -1]
y = np.array(y).ravel()
y = pd.DataFrame(y, columns=['label'])
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 70%训练,30%测试
print("x_train,y_train,x_test,y_test:", x_train.shape, y_train.shape, x_test.shape, y_test.shape)
#创建模型
models = {
'LR': LogisticRegression(),
"RF": RandomForestClassifier(),
"ET": ExtraTreesClassifier(),
"KNN": KNeighborsClassifier(n_neighbors=2),
"SVM": SVC(probability=True),
"DC": DecisionTreeClassifier(),
"CatBoost": CatBoostClassifier(verbose=0),
"LGBM": lgb.LGBMClassifier(verbose=-1),
}
# 格式化表头
print(
"{:<20} | {:<9} | {:<9} | {:<9} | {:<9} | {:<9}".format("Model", "Accuracy", "Precision", "Recall", "F1 Score",
"AUC"))
results_df = pd.DataFrame(columns=["Model", "Accuracy", "Precision", "Recall", "F1 Score", "AUC"])
for name, model in models.items():
model.fit(x_train, y_train) # 模型训练
y_pred = model.predict(x_test)
y_pred_prob = model.predict_proba(x_test)[:, 1] # 一列是类别为 0 的概率,另一列是类别为 1 的概率
# print('Model Name: ', name)
# tp, fn, fp, tn = confusion_matrix(y_test,y_pred,labels=[1,0]).reshape(-1)
# # accuracy = (tp + tn) / (tp + tn + fp + fn)
# # precision = tp / (tp + fp)
# # recall = tp / (tp + fn)
# # f1 = 2 * (precision * recall) / (precision + recall)
#
# accuracy = round((tp+tn)/(tp+fp+tn+fn), 3)
# print('Accuracy :', round(accuracy*100, 2),'%')
accuracy = accuracy_score(y_test, y_pred)
precision, recall, f1_score, _ = precision_recall_fscore_support(y_test, y_pred, average='binary')
auc1 = roc_auc_score(y_test, y_pred)
fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)
auc2 = auc(fpr, tpr)
print("{:<20} | {:<9.2%} | {:<9.2%} | {:<9.2%} | {:<9.2%} | {:<9.2%}".format(name, accuracy, precision, recall,
f1_score, auc2))
# # 将结果添加到DataFrame
# results_df = results_df.append(
# {"Model": name, "Accuracy": accuracy, "Precision": precision, "Recall": recall, "F1 Score": f1_score},
# ignore_index=True)
drawAUC_TwoClass2(models, x_test, y_test)
# predict_tif3(models, X.columns) # 预测并保存tif文件
# 用窗口预测
def predict_tif3(models, feature_names):
args = parse_args()
# os.listdir(args.feature_path)[0]
# 假设config['data_path']包含所有tif文件的路径
# 预先定义一个变量来存储nodata值
nodata_value = None
# 以第一个tif文件为基准,获取元数据和窗口大小
with rasterio.open(os.path.join(args.feature_path, os.listdir(args.feature_path)[0])) as src:
meta = src.meta
if nodata_value is None:
nodata_value = src.nodatavals[0]
# 窗口大小,这里可以根据您的内存大小进行调整
width, height = src.width // 2, src.height // 2
# 更新元数据
meta.update(count=1, dtype=rasterio.float32, nodata=nodata_value)
# 循环执行预测并保存tif文件
for name, model in models.items():
start_time = time.time() # Start timing
# 定义结果数组,用nodata值初始化
prediction_image = np.full((meta['height'], meta['width']), nodata_value, dtype=rasterio.float32)
# 按窗口读取和预测
for row_off in range(0, meta['height'], height):
for col_off in range(0, meta['width'], width):
window = Window(col_off, row_off, width, height)
arrays = []
nodata_mask = None
for path in os.listdir(args.feature_path):
# num_class = float(re.search(r'_(\d+)\.', path).group(1)) # 断层_5.tif --> 5
path = os.path.join(args.feature_path, path)
with rasterio.open(path) as src:
band = src.read(1, window=window).astype('float32') # / num_class
# 初始化nodata掩膜
if nodata_mask is None:
nodata_mask = band == nodata_value
# 掩膜无效数据
band[nodata_mask] = np.nan
arrays.append(band)
# 将窗口内的所有数组合并成一个3D数组
stacked_arrays = np.dstack(arrays)
# 提取有效像素
valid_mask = ~np.isnan(stacked_arrays).all(axis=2)
valid_pixels_features = stacked_arrays[valid_mask]
# 如果窗口内没有有效像素,则跳过
if valid_pixels_features.size == 0:
continue
# 使用特征名称创建DataFrame
valid_pixels_features_df = pd.DataFrame(valid_pixels_features, columns=feature_names)
# print(valid_pixels_features_df.min())
# 对有效像素特征进行预测
predictions = model.predict_proba(valid_pixels_features_df)[:, 1]
# 将预测填充到相应位置
prediction_image[row_off:row_off + height, col_off:col_off + width][valid_mask] = predictions
# 保存预测图像为新的tif文件
save_path = f'./易发性图/{name}_predict.tif'
with rasterio.open(save_path, 'w', **meta) as dst:
dst.write(prediction_image, 1)
print(name, "保存成功! ", save_path)
# Calculate and print the total time spent
end_time = time.time()
print(f"time for {name}: {end_time - start_time:.2f} seconds")
# 清理变量
prediction_image = None
if __name__ == '__main__':
main()5 深度学习
代码的话参考如下:
https://github.com/scar-on/Landslide-susceptibility-mapping
此项目已经把深度学习写得比较完善了,有能力的人,还可在模型上修改。
另:Landslide-susceptibility-mapping/train_CNN.py文件中 第103行 scheduler.step(),应该再往里缩进一下
三、结语
到这里大概就结束了
后续分享一些小工具,感谢他们无私分享,向他们致敬!!!
SVM-LSM-Toolbox 这个确实方便了我很多,可以做了很多的预处理工作,DEM生成其它相关因子(坡度、坡向、地形起伏度等,一键生成),还有就是非灾害点生成那里其实蛮麻烦的,先要弄缓冲区,然后再裁剪缓冲区,最后生成随机点,这个工具一下就使用好了,当然你也可以使用他这个工具去进行SVM预测。
注:我记得这个工具好像是要用UTM投影,记得处理一下。
中文简介:
2022(一等奖)B360基于Arcpy与SVM的滑坡易发性评价_svm-lsm工具箱-CSDN博客
详细操作视频:
2022(一等奖)B360基于Arcpy与SVM的滑坡易发性评价_哔哩哔哩_bilibili
工具样式如下:
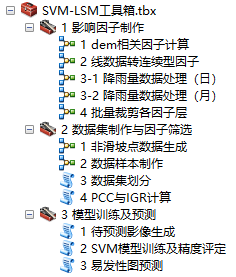
另外就是B站上由很多关于易发性评价的视频,有用信息量、频率比的,等等等等
如
建议阅读论文:
[1]孔嘉旭,庄建琦,彭建兵,等.基于信息量和卷积神经网络的黄土高原滑坡易发性评价[J].地球科学,2023,48(05):1711-1729.

















 285
285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









