







函数的调用是在栈上进行的,栈的生长方向是由高地址向低地址,即栈底为高地址,栈顶为低地址。每个函数在被调用时都对应着各自一个栈帧,用来记录函数自身的一些信息(返回地址、局部变量…),因此栈帧也叫“过程活动记录”,为了衡量栈帧的范围,就需要用到两个寄存器:ESP和EBP。ESP就是Extend Stack Pointer,也叫栈指针,ESP中始终存放着指向当前栈帧顶部(并非栈顶,尽管二者无需严格区分但也需要知道)的指针,时刻栈帧顶部,即当压入数据时,ESP-=4;弹出数据时ESP+=4。EBP是Extend Base Pointer,顾名思义,EBP时刻指向当前栈帧的底部(并非栈底)。
在这里举个比较简单的程序来理解:
<span style="color:rgba(0, 0, 0, 0.75)"><span style="background-color:#ffffff"><span style="color:#000000"><code>int Sum(int x, int y)
{
int s;
s = x + y;
return s;
}
int main()
{
int sum;
int a = 2, b = 3;
sum = Sum(a, b);
return 0;
}
</code></span></span></span>程序非常简单,就是实现两数求和。现在对其反汇编代码进行分析来思考函数调用的过程:
反汇编代码如下:
在main函数栈帧中,首先将前一栈帧的ebp地址记录下来压入栈中,以便main函数返回后能顺利回到返回地址,压入ebp的地址后esp自动减4指向栈顶,而此时ebp还停留在上一栈帧底部,因此还需将ebp移到esp所在位置,然后再以当前的ebp为基址开辟main函数的栈帧空间(在这里为0e4h),这一过程如下图所示。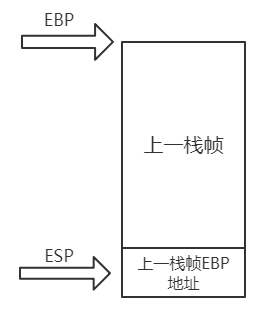
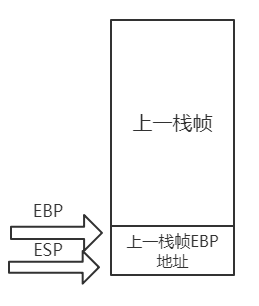
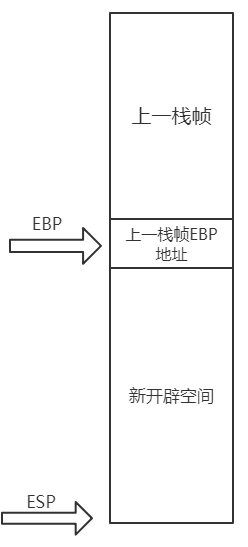
然后再按顺序压入ebx、esi、edi。
接下来的
lea edi,[ebp-0E4h]
mov ecx,39h
mov eax,0CCCCCCCCh
rep stos dword ptr es:[edi]
用于将前面开辟的0e4h大小的空间各个单元值初始化为0cccccccch。
然后再看后面紧接着的两句即是对main函数中的局部变量a,b赋值了,观察红色框突出的部分,可以发现此时a和b的地址已经是确定好的,分别是ebp-14h和ebp-20h,除此之外,再往下的sum也已经有确定的地址ebp-8h,此时就引起了我对两个问题的思考:这些变量是什么时候入栈的呢?为什么局部变量的内存分配不是连续的,三个Int型变量理应间隔4个字节?
实际上,局部变量在程序编译时就已经根据各个变量的大小确定其相对于基址的偏移量,但是并未载入内存中;当局部变量所在函数运行时,程序载入内存,其基址由栈内存分配,此时就根据各局部变量相对于基址的偏移量即可确定各局部变量的地址并将其入栈。根据在VS上调试过程中对局部变量的监视情况也可说明这一点,发现当局部变量所在函数一旦运行,局部变量的地址就已经确定了,即使此时程序还未执行到局部变量定义的语句也不会影响,这是因为:如前所述,函数一旦运行,就会首先保存上一栈帧的基址,然后将EBP移至ESP所在位置作为当前函数的栈帧基址,基址的确定即可根据偏移量确定各个局部变量的地址了,局部变量也于此时入栈。
解决了这个问题,那么再来看看局部变量内存分配的问题。这其实是Debug模式下运行的结果,因为Debug在对变量分配内存时,会分配更多的内存,这些多出来的内存中包含了大量的调试信息,抛开这些调试信息不看,如果将程序放在Release下运行,即可发现它们的内存分配都是连续的了。
经过上述操作后,栈的情况如图所示。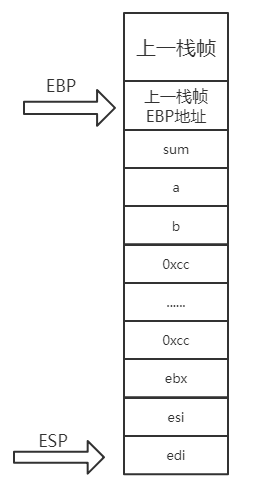
接下来
mov eax,dword ptr [b]
push eax
mov ecx,dword ptr [a]
push ecx
这里是将b和a的值赋值给eax和ecx,实际上这也就是传递参数了,将sum(a,b)的两个参数a和b赋值给eax和ecx,需要注意的是,参数入栈的顺序实际上是从右往左的,即先push参数Pn,最后push参数P1。参数全部入栈后,紧接着就是call Sum (0961393h),这即是开始调用Sum函数了。而call指令在这里有两个作用:第一是把PC指针(即下一条指令的地址,在EIP寄存器中取得)入栈,然后跳转到Sum函数的地址。如图所示。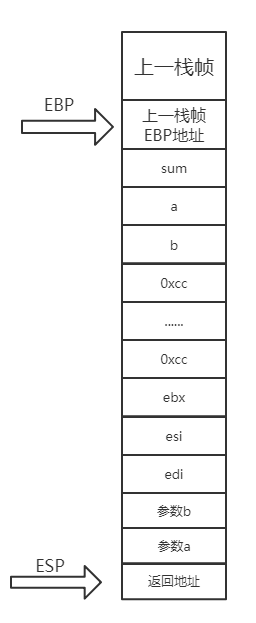
进入到Sum函数后,和进入main函数类似,依旧是先将上一栈帧(在这里即是main函数栈帧)的EBP地址入栈保存,然后移动EBP至ESP的位置后再移动ESP开辟Sum函数的栈帧空间,和前面一样,此时Sum函数的局部变量s已经入栈了。这几步操作在这里不过多赘述。如图所示。
然后接下来会进行s=x+y的操作,如蓝色框突出部分所示,这里的x所在地址实际上是ebp-8h,y所在地址是ebp-ch,显而易见,x即是上图中的参数a,y即是上图中的参数b,将这两个单元中的值求和后赋值给s即实现了s=x+y。从这里我们也能看出main函数中的局部变量a和b与Sum函数中的参数a和b是相互独立的,各自具有各自的地址,这也很直观的说明为什么函数按值传递参数时形参的改变不会影响实参了。最后用eax来保存返回值,返回的是s那么eax则会去变量s对应地址取值。
此时就进入到函数返回阶段了。
Sum函数返回比较好理解,先依次弹出edi,esi和ebx,然后将esp移向ebp位置,弹出所保存的main函数ebp地址,需要注意的是,这里的pop ebp是指将栈顶元素弹出,送给ebp,ebp就重新指向了main函数的ebp所在地址。然后通过ret指令,弹出栈顶指令并跳转到弹出的返回地址,也就是回到了main函数中,如图所示。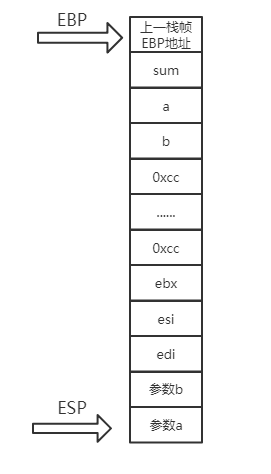
然后add esp 8使得ESP指针指向了edi,然后依次弹出edi、esi和ebx,并将eax中的值赋给了sum变量后清零eax,最终将esp指针移回,再检查栈堆平衡后ebp回到上一栈帧。















 3081
3081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









