







Apache Storm
版本号:2.0.0
官网:http://storm.apache.org/releases/2.0.0/index.html
一、基础篇
(一)什么是Storm
Apache Storm是一个免费的开源分布式实时计算系统。Storm可以轻松可靠地处理无限数据流,实时处理Hadoop为批处理所做的工作。Storm很简单,可以与任何编程语言一起使用,并且使用起来很有趣!
Storm有许多用例:实时分析,在线机器学习,连续计算,分布式RPC,ETL等。Storm很快:一个基准测试表示每个节点每秒处理超过一百万个元组。它具有可扩展性,容错性,可确保您的数据得到处理,并且易于设置和操作。
Storm集成了您已经使用的排队和数据库技术。Storm拓扑消耗数据流并以任意复杂的方式处理这些流,然后在计算的每个阶段之间重新划分流。阅读本教程中的更多内容。(引自官网)
(二)相关概念
Topology(直译为拓扑):在Storm中topology编织数据流计算的流程。Storm拓扑类似于MapReduce作业。一个关键的区别是MapReduce作业最终完成,而拓扑结构永远运行,直到手动kill掉进程。
Streams:流是无限的Tuple序列,以分布式方式并行处理和创建。Streams是使用Schema定义的,该Schema命名流的Tuple中的字段。
Tuple:是Storm中一则记录,该记录存储是一个数组元素,Tuple元素都是只读的,不允许修改。(Tuple等价于Kafka Streaming的Record,可以理解为一条包含多个字段的数据)
Tuple t=new Tuple(new Object[]{1,"zs",true})// readOnly
Spouts(直译为喷嘴):负责产生Tuple,是Streams源头.通常是通过Spout读取外围系统的数据,并且将数据封装成Tuple,并且将封装Tuple发射|emit到Topology中.IRichSpout|BaseRichSpout
Bolts(直译为螺栓):所有的Topology中的Tuple是通过Bolt处理,Bolt作用是用于过滤/聚合/函数处理/join/存储数据到DB中等。
IRichBolt|BaseRichBolt 执行At Most Once机制,IBasicBolt|BaseBasicBolt 执行At Least Once ,IStatefulBolt | BaseStatefulBolt 执行有状态计算。
注:名词图解
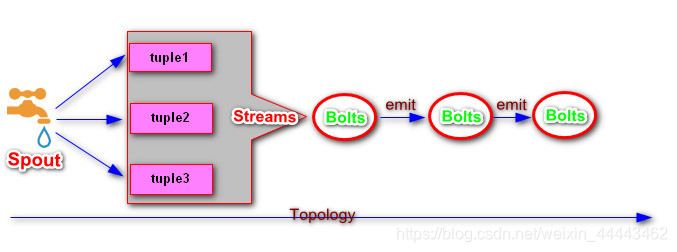
(三)集群搭建
1.集群模型
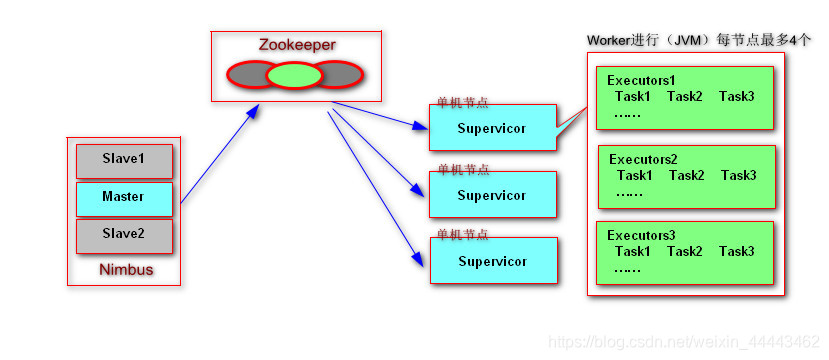
2.模型解释
Nimbus:计算任务的主节点,负责分发代码/分配任务/对Supervisor任务执行进行故障检测。
Supervisor:接受来自Nimbus的任务分配,启动Worker进程执行计算任务。
Zookeeper:负责Nimbus和Supervisor协调,Storm会使用zookeeper存储nimbus和supervisor进程状态信息,这就导致了Nimbus和Supervisor是无状态的可以实现任务快速故障恢复,即而让流计算达到难以置信的稳定。
Worker:是Supervisor专门为某一个Topology任务启动的一个Java 进程,Worker进程通过执行Executors(线程)完成任务的执行,每个任务会被封装成一个个Task。
3.集群搭建(虚拟机)
- 同步时钟
[root@CentOSX ~]# yum install -y ntp
[root@CentOSX ~]# service ntpd start
[root@CentOSX ~]# ntpdate cn.pool.ntp.org - 安装zookeeper集群
[root@CentOSX ~]# tar -zxf zookeeper-3.4.6.tar.gz -C /usr/
[root@CentOSX ~]# mkdir zkdata
[root@CentOSX ~]# cp /usr/zookeeper-3.4.6/conf/zoo_sample.cfg /usr/zookeeper-3.4.6/conf/zoo.cfg
[root@CentOSX ~]# vi /usr/zookeeper-3.4.6/conf/zoo.cfg
tickTime=2000
dataDir=/root/zkdata
clientPort=2181
[root@CentOSX ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh start zoo.cfg
[root@CentOSX ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh status zoo.cfg - 安装JDK8+
[root@CentOSX ~]# rpm -ivh jdk-8u171-linux-x64.rpm
[root@CentOSX ~]# vi .bashrc
JAVA_HOME=/usr/java/latest
CLASSPATH=.
PATH= P A T H : PATH: PATH:JAVA_HOME/bin
export JAVA_HOME
export CLASSPATH
export PATH
[root@CentOSX ~]# source .bashrc - 配置主机名和IP的映射关系
[root@CentOSX ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.111.128 CentOSA
192.168.111.129 CentOSB
192.168.111.130 CentOSC - 关闭防火墙
[root@CentOSX ~]# vi /etc/hosts
[root@CentOSX ~]# service iptables stop
[root@CentOSX ~]# chkconfig iptables off - 安装配置Storm
[root@CentOSX ~]# tar -zxf apache-storm-2.0.0.tar.gz -C /usr/
[root@CentOSX ~]# vi .bashrc
STORM_HOME=/usr/apache-storm-2.0.0
JAVA_HOME=/usr/java/latest
CLASSPATH=.
PATH= P A T H : PATH: PATH:JAVA_HOME/bin:$STORM_HOME/bin
export JAVA_HOME
export CLASSPATH
export PATH
export STORM_HOME
[root@CentOSX ~]# source .bashrc
[root@CentOSX ~]# storm version
如果是Storm-2.0.0需要二外安装yum install -y python-argparse否则 storm指令无法正常使用
Traceback (most recent call last):
File “/usr/apache-storm-2.0.0/bin/storm.py”, line 20, in
import argparse
ImportError: No module named argparse - 修改storm.yaml 配置文件
[root@CentOSX ~]# vi /usr/apache-storm-2.0.0/conf/storm.yaml
########### These MUST be filled in for a storm configuration
storm.zookeeper.servers:
- “CentOSA”
- “CentOSB”
- “CentOSC”
storm.local.dir: “/usr/storm-stage”
nimbus.seeds: [“CentOSA”,“CentOSB”,“CentOSC”]
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
注意 ymal配置格式前面空格 - 启动Storm进程
[root@CentOSX ~]# nohup storm nimbus >/dev/null 2>&1 & – 启动 主节点
[root@CentOSX ~]# nohup storm supervisor >/dev/null 2>&1 & --启动 计算节点
[root@CentOSA ~]# nohup storm ui >/dev/null 2>&1 & --启动web ui界面 - 启动成功后访问访问:http://CentOSA:8080
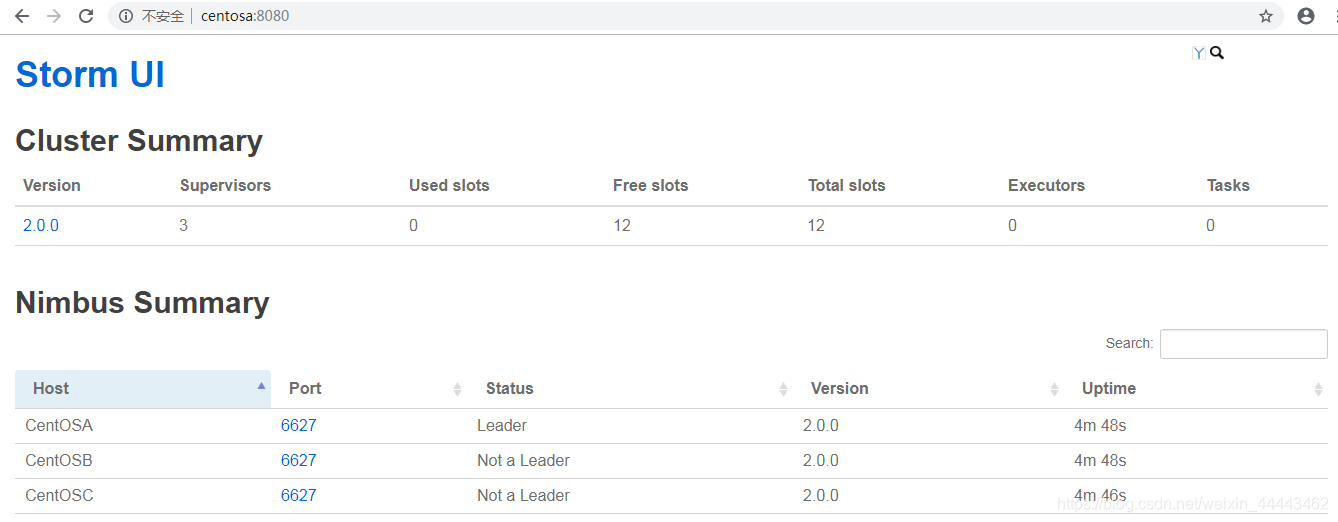
(四)入门案例-LowLevel API
1.案例描述
每秒钟向Topology随机发送"this is a demo",“hello Storm”,"ni hao"三个字符串中的一串,在Topology中分割字符串(分割为单词),统计每个单词出现次数,将最终结果持续输出打印
2.Maven依赖
- pom.xml
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.0.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-client</artifactId>
<version>2.0.0</version>
<scope>provided</scope>
</dependency>
3.Java代码
- 编写 Spout
public class WordCountSpout extends BaseRichSpout {
private String[] lines={"this is a demo","hello Storm","ni hao"};
//该类负责将数据发送给下游
private SpoutOutputCollector collector;
public void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
//向下游发送Tuple ,改Tuple的Schemal在declareOutputFields声明
public void nextTuple() {
Utils.sleep(1000);//休息1s钟,即每隔一秒钟发送
String line=lines[new Random().nextInt(lines.length)];
collector.emit(new Values(line));
}
//对emit中的tuple做字段的描述
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
- 编写 Bolt
LineSplitBolt
public class LineSplitBolt extends BaseRichBolt {
//该类负责将数据发送给下游
private OutputCollector collector;
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] tokens = line.split("\\W+");
for (String token : tokens) {
collector.emit(new Values(token,1));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","count"));
}
}
WordCountBolt
public class WordCountBolt extends BaseRichBolt {
//存储状态
private Map<String,Integer> keyValueState;
//该类负责将数据发送给下游
private OutputCollector collector;
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
keyValueState=new HashMap<String, Integer>();
}
public void execute(Tuple input) {
String key = input.getStringByField("word");
int count=0;
if(keyValueState.containsKey(key)){
count=keyValueState.get(key);
}
//更新状态
int currentCount=count+1;
keyValueState.put(key,currentCount);
//将最后结果输出给下游
collector.emit(new Values(key,currentCount));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("key","result"));
}
}
WordPrintBolt
public class WordPrintBolt extends BaseRichBolt {
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
}
public void execute(Tuple input) {
String word=input.getStringByField("key");
Integer result=input.getIntegerByField("result");
System.out.println(input+"\t"+word+" , "+result);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
- 编写Topology
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class WordCountTopology {
public static void main(String[] args) throws Exception {
//1.创建TopologyBuilder
TopologyBuilder builder = new TopologyBuilder();
//2.编织流处理逻辑- 重点(Spout、Bolt、连接方式)
builder.setSpout("WordCountSpout",new WordCountSpout(),1);
builder.setBolt("LineSplitBolt",new LineSplitBolt(),3)
.shuffleGrouping("WordCountSpout");//设置 LineSplitBolt 接收上游数据通过 随机
builder.setBolt("WordCountBolt",new WordCountBolt(),3)
.fieldsGrouping("LineSplitBolt",new Fields("word"));
builder.setBolt("WordPrintBolt",new WordPrintBolt(),4)
.fieldsGrouping("WordCountBolt",new Fields("key"));
//3.提交流计算
Config conf= new Config();
conf.setNumWorkers(3); //设置Topology运行所需的Worker资源,JVM个数
conf.setNumAckers(0); //关闭Storm应答,可靠性有关
StormSubmitter.submitTopology("worldcount",conf,builder.createTopology());
/*注:使用LocalCluster可以进行本地测试
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("worldcount",conf,builder.createTopology());
*/
}
}
shuffleGrouping:表示下游的LineSplitBolt会随机的接收上游的Spout发出的数据流。
fieldsGrouping: 表示相同的Fields数据总会发送给同一个Task Bolt节点。
- 任务提交
使用mvn package打包应用,然后将打包的jar包上传到 集群中的任意一台机器
[root@CentOSA ~]# storm jar /root/storm-lowlevel-1.0-SNAPSHOT.jar com.baizhi.demo01.WordCountTopology
....
16:27:28.207 [main] INFO o.a.s.StormSubmitter - Finished submitting topology: worldcount
提交成功后,用户可以查看Storm UI界面查看程序的执行效果http://centosa:8080/
- 查看任务列表
[root@CentOSA ~]# storm list
...
Topology_name Status Num_tasks Num_workers Uptime_secs Topology_Id Owner
----------------------------------------------------------------------------------------
worldcount ACTIVE 11 3 66 worldcount-2-1560760048 root
- 杀死Topology
[root@CentOSX ~]# storm kill worldcount
(五)任务并行性
1.代码对实体并行的配置-图解
Worker(进程)、Executors(线程)和Task(任务)

2.并行配置的运行原理-图解
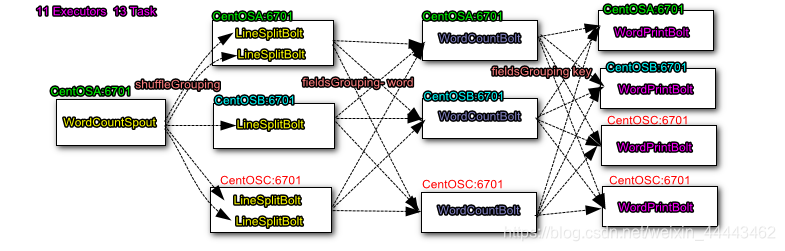
3.并行配置在页面中的表现-图解

4.程序运行过程中并行配置的修改
方法一:使用Storm Web UI重新平衡拓扑。
方法二:使用在Linux中通过shell命令修改
[root@CentOSA ~]# storm rebalance
usage: storm rebalance [-h] [-w WAIT_TIME_SECS] [-n NUM_WORKERS]
[-e EXECUTORS] [-r RESOURCES] [-t TOPOLOGY_CONF]
[--config CONFIG]
[-storm_config_opts STORM_CONFIG_OPTS]
topology-name
修改Worker数目
[root@CentOSX ~]# storm rebalance -w 10 -n 6 wordcount02
修改某个组件的并行度,一般不能超过Task个数
[root@CentOSX ~]# storm rebalance -w 10 -n 3 -e LineSplitBolt=5 wordcount02
(六)Tuple可靠性处理
1.Storm如何保证消息处理
Storm 消息Tuple可以通过一个叫做AckerBolt去监测整个Tuple Tree是否能够被完整消费,如果消费超时或者失败该AckerBolt会调用Spout组件(发送改Tuple的Spout组件)的fail方法,要求Spout重新发送Tuple.默认AckerBolt并行度是和Worker数目一致,用户可以通过config.setNumAckers(0);关闭Storm的Acker机制。
具体操作:
Spout端:- Spout在发射 tuple 的时候必须提供msgID,同时覆盖ack和fail方法
public class WordCountSpout extends BaseRichSpout {
private String[] lines={"this is a demo","hello Storm","ni hao"};
private SpoutOutputCollector collector;
public void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
public void nextTuple() {
Utils.sleep(5000);//休息1s钟
int msgId = new Random().nextInt(lines.length);
String line=lines[msgId];
//发送 Tuple 指定 msgId
collector.emit(new Values(line),msgId);
}
//对emit中的tuple做字段的描述
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
//发送成功回调 AckerBolt
@Override
public void ack(Object msgId) {
System.out.println("发送成功:"+msgId);
}
//发送失败回调 AckerBolt
@Override
public void fail(Object msgId) {
String line = lines[(Integer) msgId];
System.out.println("发送失败:"+msgId+"\t"+line);
}
}
Bolt端:将当前的子Tuple 锚定到父Tuple上; 向上游应答当前父Tuple的状态,应答有两种方式 collector.ack(input);|collector.fail(input)。
public void execute(Tuple 父Tuple) {
try {
//do sth
//锚定当前父Tuple
collector.emit(父Tuple,子Tuple);
//向上游应答当前父Tuple的状态
collector.ack(父Tuple);
} catch (Exception e) {
collector.fail(父Tuple);
}
}
2.可靠性机制检测原理
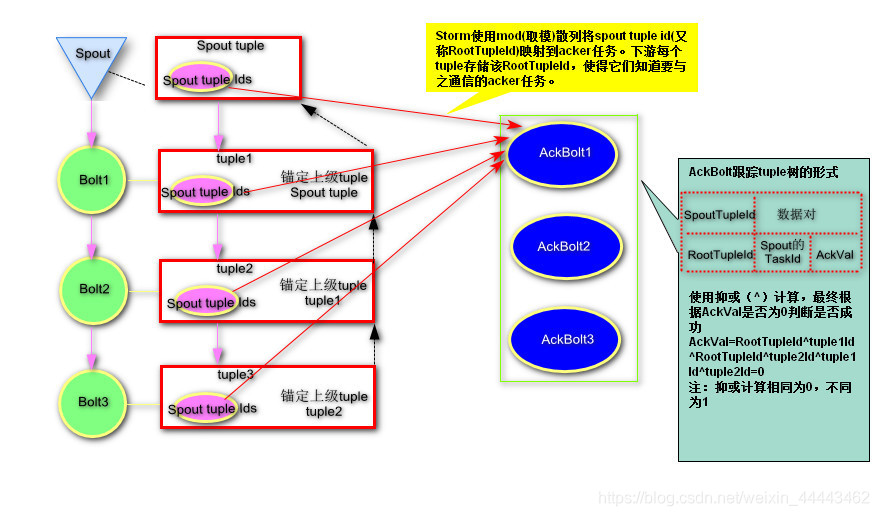
3.IBasicBolt|BaseBasicBolt规范
许多Bolt遵循读取输入元组的共同模式(锚定、ack出错fail),基于它发出元组,然后在执行方法结束时执行元组。因此Storm给我们提供了一套规范,如果用户使用Ack机制,在编写Bolt的时候只需要实现BasicBolt接口或者继承BaseBasicBolt类即可。
public class WordCountBolt extends BaseBasicBolt {
private Map<String,Integer> keyValueState;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context) {
keyValueState=new HashMap<String, Integer>();
}
public void execute(Tuple input, BasicOutputCollector collector) {
String key = input.getStringByField("word");
int count=0;
if(keyValueState.containsKey(key)){
count=keyValueState.get(key);
}
int currentCount=count+1;
keyValueState.put(key,currentCount);
//不在需要手工锚定上级tuple
collector.emit(new Values(key,currentCount));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("key","result"));
}
}
4.关闭Acker机制
- 设置NumAcker数目为0
- 在Spout发送的是不提供MsgID
- 在Bolt 不使用锚定
关闭Acker的好处:可以提示Storm处理性能,减少延迟。
(七)Storm的状态管理
1.检查点机制
检查点由指定topology.state.checkpoint.interval.ms的内部检查点spout触发。如果拓扑中至少有一个IStatefulBolt(有状态的bolt),则拓扑构建器会自动添加检查点spout。对于有状态拓扑,拓扑构建器将IStatefulBolt包装在StatefulBoltExecutor中,该处理器在接收检查点tuple时处理状态提交。非状态Bolt包装在CheckpointTupleForwarder中,它只转发检查点Tuple,以便检查点元组可以流经拓扑DAG。检查点元组流经单独的内部流,即$ checkpoint。拓扑构建器在整个拓扑中连接检查点流,并在根处设置检查点spout。
在检查点间隔,CheckPointSpout发出CheckPointTuple(检查点元组)。在接收到检查点元组时,保存螺栓的状态,然后将检查点元组转发到下一个组件。每个tuple在保存其状态之前等待检查点到达其所有输入流,以便状态表示拓扑中的一致状态。一旦$CheckPointSpout从所有螺栓接收到ACK,状态提交就完成了,并且事务被记录并由CheckPointSpout提交。
状态检查点不检查当前spout的状态。然而,一旦所有tuple的状态都被检查,并且一旦CheckPointTuple被激活,Spout发出的tuple也会被激活。它还意味着topology.state.checkpoint.interval.ms低于topology.message.timeout.secs。 状态提交的工作方式类似于具有准备和提交阶段的三阶段提交协议,以便以一致且原子的方式保存拓扑中的状态。
2.状态持久化-基于Redis存储状态
- 在pom.xml中引入依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-redis</artifactId>
<version>2.0.0</version>
</dependency>
- 官方文档给出的配置模板Map<String,String|Map<String,Object>>
单机模式
{
"keyClass": "Optional fully qualified class name of the Key type.",
"valueClass": "Optional fully qualified class name of the Value type.",
"keySerializerClass": "Optional Key serializer implementation class.",
"valueSerializerClass": "Optional Value Serializer implementation class.",
"jedisPoolConfig": {
"host": "localhost",
"port": 6379,
"timeout": 2000,
"database": 0,
"password": "xyz"
}
}
集群模式
{
"keyClass": "Optional fully qualified class name of the Key type.",
"valueClass": "Optional fully qualified class name of the Value type.",
"keySerializerClass": "Optional Key serializer implementation class.",
"valueSerializerClass": "Optional Value Serializer implementation class.",
"jedisClusterConfig": {
"nodes": ["localhost:7379", "localhost:7380", "localhost:7381"],
"timeout": 2000,
"maxRedirections": 5
}
}
- 配置topology,添加如下配置信息
//配置Redis
conf.put(Config.TOPOLOGY_STATE_PROVIDER,"org.apache.storm.redis.state.RedisKeyValueStateProvider");
Map<String,Object> stateConfig=new HashMap<String,Object>();
Map<String,Object> redisConfig=new HashMap<String,Object>();
redisConfig.put("host","CentOSA");
redisConfig.put("port",6379);
stateConfig.put("jedisPoolConfig",redisConfig);
ObjectMapper objectMapper=new ObjectMapper();
System.out.println(objectMapper.writeValueAsString(stateConfig));
conf.put(Config.TOPOLOGY_STATE_PROVIDER_CONFIG,objectMapper.writeValueAsString(stateConfig));
3.状态持久化-基于HBase存储状态
- 在pom.xml中引入依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-hbase</artifactId>
<version>2.0.0</version>
</dependency>
- 官方文档给出的配置模板Map<String,String>
{
"keyClass": "Optional fully qualified class name of the Key type.",
"valueClass": "Optional fully qualified class name of the Value type.",
"keySerializerClass": "Optional Key serializer implementation class.",
"valueSerializerClass": "Optional Value Serializer implementation class.",
"hbaseConfigKey": "config key to load hbase configuration from storm root configuration. (similar to storm-hbase)",
"tableName": "Pre-created table name for state.",
"columnFamily": "Pre-created column family for state."
}
- 配置topology,添加如下配置信息
config.put(Config.TOPOLOGY_STATE_PROVIDER,"org.apache.storm.hbase.state.HBaseKeyValueStateProvider");
Map<String,Object> hbaseConfig=new HashMap<String,Object>();
hbaseConfig.put("hbase.zookeeper.quorum", "CentOSA");//Hbase zookeeper连接参数
config.put("hbase.conf", hbaseConfig);
ObjectMapper objectMapper=new ObjectMapper();
Map<String,Object> stateConfig=new HashMap<String,Object>();
stateConfig.put("hbaseConfigKey","hbase.conf");
stateConfig.put("tableName","baizhi:wordcountstate");
stateConfig.put("columnFamily","cf1");
config.put(Config.TOPOLOGY_STATE_PROVIDER_CONFIG,objectMapper.writeValueAsString(stateConfig));
(八)Distributed RPC
Storm的DRPC真正的实现了并行计算.Storm Topology接受用户的参数进行计算,然后最终将计算结果以Tuple形式返回给用户.
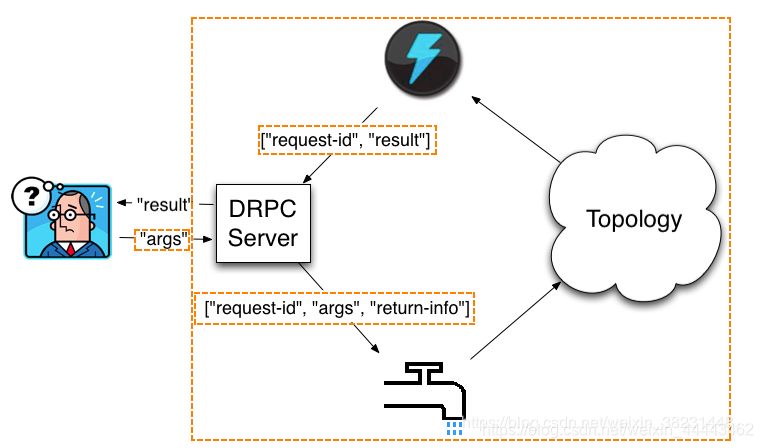
- 修改storm.yaml配置文件
vi /usr/apache-storm-2.0.0/conf/storm.yaml
storm.zookeeper.servers:
- "CentOSA"
- "CentOSB"
- "CentOSC"
storm.local.dir: "/usr/apache-storm-1.2.2/storm-stage"
nimbus.seeds: ["CentOSA","CentOSB","CentOSC"]
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
drpc.servers:
- "CentOSA"
- "CentOSB"
- "CentOSC"
storm.thrift.transport: "org.apache.storm.security.auth.plain.PlainSaslTransportPlugin"
注意格式!
- 重启Storm所有服务
[root@CentOSX ~]# nohup storm drpc >/dev/null 2>&1 &
[root@CentOSX ~]# nohup storm nimbus >/dev/null 2>&1 &
[root@CentOSX ~]# nohup storm supervisor >/dev/null 2>&1 &
[root@CentOSA ~]# nohup storm ui >/dev/null 2>&1 &
DRPC案例剖析
引入依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-redis</artifactId>
<version>2.0.0</version>
</dependency>
WordCountRedisLookupMapper
import com.google.common.collect.Lists;
import org.apache.storm.redis.common.mapper.RedisDataTypeDescription;
import org.apache.storm.redis.common.mapper.RedisLookupMapper;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.ITuple;
import org.apache.storm.tuple.Values;
import java.util.List;
public class WordCountRedisLookupMapper implements RedisLookupMapper {
// iTuple 上游发送的iTuple,目的是为了获取id
public List<Values> toTuple(ITuple iTuple, Object value) {
Object id = iTuple.getValue(0);
List<Values> values = Lists.newArrayList();
if(value == null){
value = 0;
}
values.add(new Values(id, value));
return values;
}
//第一个位置的name必须为id,后续的无所谓了
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("id", "num"));
}
//告知数据类型
public RedisDataTypeDescription getDataTypeDescription() {
return new RedisDataTypeDescription(RedisDataTypeDescription.RedisDataType.HASH,"wordcount");
}
public String getKeyFromTuple(ITuple iTuple) {
return iTuple.getString(1);
}
//该方法无需实现,默认是给RedisStoreBolt使用
public String getValueFromTuple(ITuple iTuple) {
return null;
}
}
TopologyDRPCStreeamTest
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.drpc.LinearDRPCTopologyBuilder;
import org.apache.storm.redis.bolt.RedisLookupBolt;
import org.apache.storm.redis.common.config.JedisPoolConfig;
public class TopologyDRPCStreeamTest {
public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("count");
Config conf = new Config();
conf.setDebug(false);
JedisPoolConfig jedisConfig = new JedisPoolConfig.Builder()
.setHost("CentOSA").setPort(6379).build();
RedisLookupBolt lookupBolt = new RedisLookupBolt(jedisConfig, new WordCountRedisLookupMapper());
builder.addBolt(lookupBolt);
StormSubmitter.submitTopology("drpc-demo", conf, builder.createRemoteTopology());
}
}
- 打包服务
- 提交topology
[root@CentOSA ~]# storm jar storm-lowlevel-1.0-SNAPSHOT.jar com.baizhi.demo07.TopologyDRPCStreeamTest --artifacts 'org.apache.storm:storm-redis:2.0.0'
–artifacts 指定程序运行所需的maven坐标依赖,strom脚本会自动连接网络下载,如果有多个依赖请使用
^隔开。如果依赖实在私服上用户可以使用--artifactRepositories
[root@CentOSA ~]# storm jar storm-lowlevel-1.0-SNAPSHOT.jar com.baizhi.demo07.TopologyDRPCStreeamTest
--artifacts 'org.apache.storm:storm-redis:2.0.0'
--artifactRepositories 'local^http://192.168.111.1:8081/nexus/content/groups/public/'
(九)Kafka充当Spout
1.Storm与Kafka集成-LowLevel API
- 在pom.xml中引入依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
- 构建KafkaSpout
public class KafkaTopologyDemo {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
String boostrapServers="CentOSA:9092,CentOSB:9092,CentOSC:9092";
String topic="topic01";
KafkaSpout<String, String> kafkaSpout = buildKafkaSpout(boostrapServers,topic);
//默认输出的Tuple格式 new Fields(new String[]{"topic", "partition", "offset", "key", "value"});
builder.setSpout("KafkaSpout",kafkaSpout,3);
builder.setBolt("KafkaPrintBlot",new KafkaPrintBlot(),1)
.shuffleGrouping("KafkaSpout");
Config conf = new Config();
conf.setNumWorkers(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("kafkaspout",conf,builder.createTopology());
}
//提供静态方法,用来添加Kafka配置信息构建KafkaSpout
public static KafkaSpout<String, String> buildKafkaSpout(String boostrapServers,String topic){
KafkaSpoutConfig<String,String> kafkaspoutConfig=KafkaSpoutConfig.builder(boostrapServers,topic) .setProp(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer")
.setProp(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer")
.setProp(ConsumerConfig.GROUP_ID_CONFIG,"g1")
.setEmitNullTuples(false)
.setFirstPollOffsetStrategy(FirstPollOffsetStrategy.LATEST)
.setProcessingGuarantee(KafkaSpoutConfig.ProcessingGuarantee.AT_LEAST_ONCE)
.setMaxUncommittedOffsets(10)//一旦分区积压有10个未提交offset,Spout停止poll数据,解决Storm背压问题
//使用自定义转换器-为了得到需要的字段
.setRecordTranslator(new MyRecordTranslator<String, String>())
.build();
return new KafkaSpout<String, String>(kafkaspoutConfig);
}
}
- 自定义装换器,将Kafka的Topic中的Recourd转换成tuple
MyRecordTranslator
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.storm.kafka.spout.DefaultRecordTranslator;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.List;
public class MyRecordTranslator<K, V> extends DefaultRecordTranslator<K, V> {
@Override
public List<Object> apply(ConsumerRecord<K, V> record) {
return new Values(new Object[]{record.topic(),record.partition(),record.offset(),record.key(),record.value(),record.timestamp()});
}
@Override
public Fields getFieldsFor(String stream) {
return new Fields("topic","partition","offset","key","value","timestamp");
}
}
2.Storm与Kafka、Hbase、Redis整合-LowLevel API
- 导入依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.0.0</version>
<scope>provide</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-client</artifactId>
<version>2.0.0</version>
<scope>provide</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-redis</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-hbase</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
- WodCountTopology
public class WodCountTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder=new TopologyBuilder();
Config conf = new Config();
//Redis 状态管理
conf.put(Config.TOPOLOGY_STATE_PROVIDER,"org.apache.storm.redis.state.RedisKeyValueStateProvider");
Map<String,Object> stateConfig=new HashMap<String,Object>();
Map<String,Object> redisConfig=new HashMap<String,Object>();
redisConfig.put("host","CentOSA");
redisConfig.put("port",6379);
stateConfig.put("jedisPoolConfig",redisConfig);
ObjectMapper objectMapper=new ObjectMapper();
System.out.println(objectMapper.writeValueAsString(stateConfig));
conf.put(Config.TOPOLOGY_STATE_PROVIDER_CONFIG,objectMapper.writeValueAsString(stateConfig));
//配置Hbase连接参数
Map<String, Object> hbaseConfig = new HashMap<String, Object>();
hbaseConfig.put("hbase.zookeeper.quorum", "CentOSA");
conf.put("hbase.conf", hbaseConfig);
//构建KafkaSpout
KafkaSpout<String, String> kafkaSpout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092", "topic01");
builder.setSpout("KafkaSpout",kafkaSpout,3);
builder.setBolt("LineSplitBolt",new LineSplitBolt(),3)
.shuffleGrouping("KafkaSpout");
builder.setBolt("WordCountBolt",new WordCountBolt(),3)
.fieldsGrouping("LineSplitBolt",new Fields("word"));
SimpleHBaseMapper mapper = new SimpleHBaseMapper()
.withRowKeyField("key")
.withColumnFields(new Fields("key"))
.withCounterFields(new Fields("result"))//要求改field的值必须是数值类型
.withColumnFamily("cf1");
HBaseBolt haseBolt = new HBaseBolt("baizhi:t_words", mapper)
.withConfigKey("hbase.conf");
builder.setBolt("HBaseBolt",haseBolt,3)
.fieldsGrouping("WordCountBolt",new Fields("key"));
StormSubmitter.submitTopology("wordcount1",conf,builder.createTopology());
}
}
- WordCountBolt
public class WordCountBolt extends BaseStatefulBolt<KeyValueState<String,Integer>> {
private KeyValueState<String,Integer> state;
private OutputCollector collector;
public void initState(KeyValueState<String,Integer> state) {
this.state=state;
}
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
public void execute(Tuple input) {
String key = input.getStringByField("word");
Integer count=input.getIntegerByField("count");
Integer historyCount = state.get(key, 0);
Integer currentCount=historyCount+count;
//更新状态
state.put(key,currentCount);
//必须锚定当前的input
collector.emit(input,new Values(key,currentCount));
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("key","result"));
}
}
- LineSplitBolt
public class LineSplitBolt extends BaseBasicBolt {
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","count"));
}
public void execute(Tuple input, BasicOutputCollector collector) {
String line = input.getStringByField("value");
String[] tokens = line.split("\\W+");
for (String token : tokens) {
//锚定当前Tuple
collector.emit(new Values(token,1));
}
}
}
-
maven远程下载
[root@CentOSC ~]# storm jar storm-lowlevel-1.0-SNAPSHOT.jar com.baizhi.demo09.WodCountTopology --artifacts ‘org.apache.storm:storm-redis:2.0.0,org.apache.storm:storm-hbase:2.0.0,org.apache.storm:storm-kafka-client:2.0.0,org.apache.kafka:kafka-clients:2.2.0’ --artifactRepositories ‘local^http://192.168.111.1:8081/nexus/content/groups/public/’
-
在项目中添加插件-将项目依赖一起打包
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
(十)窗口函数Window
Storm核心支持处理窗口内的一组元组。 Windows使用以下两个参数指定(类似Kafka Streaming):
- 窗口长度- the length or duration of the window
- 滑动间隔- the interval at which the windowing slides
1.Sliding Window(hopping time window)
Tuples以窗口进行分组,窗口每间隔一段滑动间隔滑动出一个新的窗口。例如下面就是一个基于时间滑动的窗口,窗口每间隔10秒钟为一个窗口,每间隔5秒钟滑动一次窗口,从下面的案例中可以看到,滑动窗口是存在一定的重叠,也就是说一个tuple可能属于1~n个窗口 。
........| e1 e2 | e3 e4 e5 e6 | e7 e8 e9 |...
-5 0 5 10 15 -> time
|<------- w1 -->|
|<---------- w2 ----->|
|<-------------- w3 ---->|
2.Tumbling Window
Tuples以窗口分组,窗口滑动的长度恰好等于窗口长度,这就导致和Tumbling Window和Sliding Window最大的区别是Tumbling Window没有重叠,也就是说一个Tuple只属于固定某一个window。
| e1 e2 | e3 e4 e5 e6 | e7 e8 e9 |...
0 5 10 15 -> time
w1 w2 w3
3.代码运用
//构建ClickWindowCountBolt
public class ClickWindowCountBolt extends BaseWindowedBolt {
private OutputCollector collector;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
public void execute(TupleWindow tupleWindow) {
Long startTimestamp = tupleWindow.getStartTimestamp();
Long endTimestamp = tupleWindow.getEndTimestamp();
SimpleDateFormat sdf=new SimpleDateFormat("HH:mm:ss");
System.out.println(sdf.format(startTimestamp)+"\t"+sdf.format(endTimestamp));
HashMap<String,Integer> hashMap=new HashMap<String, Integer>();
List<Tuple> tuples = tupleWindow.get();
for (Tuple tuple : tuples) {
String key = tuple.getStringByField("word");
Integer historyCount = 0;
if (hashMap.containsKey(key)) {
historyCount=hashMap.get(key);
}
int currentCount=historyCount+1;
hashMap.put(key,currentCount);
}
//将数据输出给PrintBolt
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {
collector.emit(tupleWindow.get(),new Values(entry.getKey(),entry.getValue()));
}
for (Tuple tuple : tupleWindow.get()) {
collector.ack(tuple);
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("key","result"));
}
}
//构建拓扑
public class WodCountTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder=new TopologyBuilder();
Config conf = new Config();
//构建KafkaSpout
KafkaSpout<String, String> kafkaSpout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092", "topic01");
builder.setSpout("KafkaSpout",kafkaSpout,3);
builder.setBolt("LineSplitBolt",new LineSplitBolt(),3)
.shuffleGrouping("KafkaSpout");
ClickWindowCountBolt clickWindowCountBolt = new ClickWindowCountBolt();
//设置滑动窗口
//clickWindowCountBolt.withWindow(BaseWindowedBolt.Duration.seconds(5),BaseWindowedBolt.Duration.seconds(2));
//设置滚动窗口
clickWindowCountBolt.withTumblingWindow(BaseWindowedBolt.Duration.seconds(5));
builder.setBolt("ClickWindowCountBolt",clickWindowCountBolt,3)
.fieldsGrouping("LineSplitBolt",new Fields("word"));
builder.setBolt("WordPrintBolt",new WordPrintBolt(),3)
.fieldsGrouping("ClickWindowCountBolt",new Fields("key"));
new LocalCluster().submitTopology("wordcount",conf,builder.createTopology());
}
}
4.Storm窗口的时间采样策略
默认情况下,Storm窗口计算时间是根据Tuple抵达Bolt时当前系统时间。只有当记录产生时间和计算时间差非常小的时候,改计算才有意义,通常把这种计算时间的策略称为Prcessing Time
通常在实际业务场景中,计算节点的时间往往比数据产生的时间较晚,这个时候基于窗口的就失去了原有的意义。Storm支持通过提取Tuple所携带的时间参数,进行窗口计算。通常把这种计算时间的策略称为Event Time.
- Event Time Window(基于事件时间的窗口)
(1)相关概念:
水位线:watermaker,改值的取值是当前接收Tuple的最新的时间戳减去 延迟lag即可以得到水位线。水位线的作用是为了推进触发窗口的。
lag:设置水位线的延迟间隙
(2)原理图解
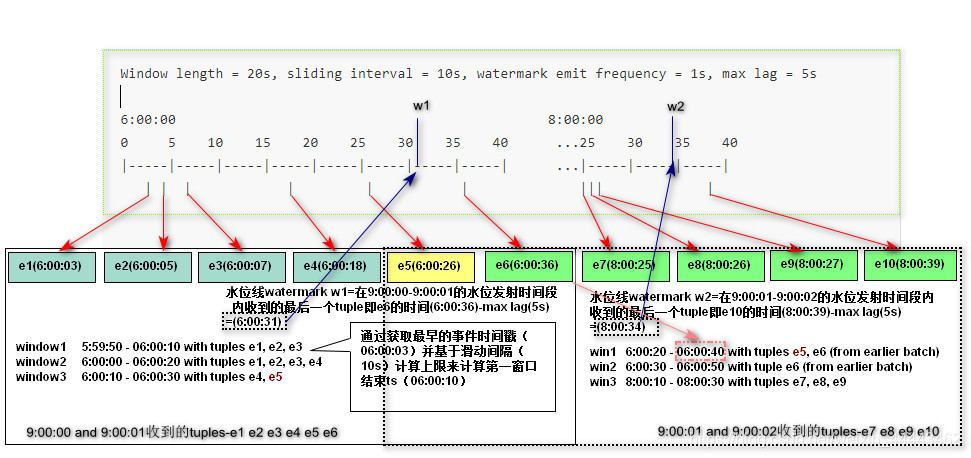
(3)代码实现
构建ClickWindowCountBolt
public class ClickWindowCountBolt extends BaseWindowedBolt {
private OutputCollector collector;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
public void execute(TupleWindow tupleWindow) {
Long startTimestamp = tupleWindow.getStartTimestamp();
Long endTimestamp = tupleWindow.getEndTimestamp();
SimpleDateFormat sdf=new SimpleDateFormat("HH:mm:ss");
System.out.println(sdf.format(startTimestamp)+"\t"+sdf.format(endTimestamp)+" \t"+this);
for (Tuple tuple : tupleWindow.get()) {
collector.ack(tuple);
String key = tuple.getStringByField("word");
System.out.println("\t"+key);
}
}
}
构建ExtractTimeBolt-提取时间的bolt
public class ExtractTimeBolt extends BaseBasicBolt {
public void execute(Tuple input, BasicOutputCollector collector) {
String line = input.getStringByField("value");
String[] tokens = line.split("\\W+");
SimpleDateFormat sdf=new SimpleDateFormat("HH:mm:ss");
Long ts= Long.parseLong(tokens[1]);
System.out.println("收到:"+tokens[0]+"\t"+sdf.format(ts) );
collector.emit(new Values(tokens[0],ts));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","timestamp"));
}
}
构建收集迟到tuple的bolt
public class LateBolt extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
System.out.println("迟到的元素:"+tuple);
}
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
}
构建Topology
public class WodCountTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder=new TopologyBuilder();
Config conf = new Config();
//构建KafkaSpout
KafkaSpout<String, String> kafkaSpout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092", "topic02");
//Kafka发出tuple
builder.setSpout("KafkaSpout",kafkaSpout,3);
//提取时间
builder.setBolt("ExtractTimeBolt",new ExtractTimeBolt(),3)
.shuffleGrouping("KafkaSpout");
//放入窗口
builder.setBolt("ClickWindowCountBolt",new ClickWindowCountBolt()
.withWindow(BaseWindowedBolt.Duration.seconds(10),BaseWindowedBolt.Duration.seconds(5))
.withTimestampField("timestamp")
.withLag(BaseWindowedBolt.Duration.seconds(2))
.withWatermarkInterval(BaseWindowedBolt.Duration.seconds(1))
.withLateTupleStream("latestream")
,1)
.fieldsGrouping("ExtractTimeBolt",new Fields("word"));
//收集迟到tuple
builder.setBolt("lateBolt",new LateBolt(),3)
.shuffleGrouping("ClickWindowCountBolt",
"latestream");
new LocalCluster().submitTopology("wordcount",conf,builder.createTopology());
}
}
二、应用篇
(一)Trident描述
Trident(直译三叉戟)是Storm的高级API,是一个高级抽象,用于在Storm之上进行实时计算。允许无缝混合高吞吐量(每秒数百万条消息),有状态流处理和低延迟分布式查询Trident具有连接,聚合,分组,功能和过滤器。除此之外,Trident还添加了基元,用于在任何数据库或持久性存储之上执行有状态的增量处理。Trident具有一致,完全一次的语义,因此很容易推理Trident拓扑。
特点:宏观流处理,微观批处理。批处理可以分组,联接,聚合,运行函数,运行过滤器等,同时提供了跨批处理进行聚合的功能,并持久存储这些聚合。
(二)常见算子介绍-无状态
1.Map算子
将一个Tuple转换为另外一个Tuple,如果用户修改了Tuple元素的个数,需要指定输出的Fields
tridentTopology.newStream("KafkaSpoutOpaque",KafkaSpoutUtils.buildKafkaSpoutOpaque("CentOSA:9092,CentOSB:9092,CentOSC:9092","topic01"))
.map((tuple)-> new Values("Hello~"+tuple.getStringByField("value")),new Fields("name"))
.peek((tuple) -> System.out.println(tuple));
2.flatMap
将一个Tuple,转换为多个Tuple,如果修改了Tuple的数目,需要指定输出的Fields
.flatMap((tuple)->{
List<Values> list=new ArrayList<>();
String[] tokens = tuple.getStringByField("value").split("\\W+");
for (String token : tokens) {
list.add(new Values(token));
}
return list;
},new Fields("word"))
.peek((tuple) -> System.out.println(tuple));
3.Filter
过滤上游输入的Tuple将满足条件的Tuple向下游输出。
tridentTopology.newStream("KafkaSpoutOpaque",KafkaSpoutUtils.buildKafkaSpoutOpaque("CentOSA:9092,CentOSB:9092,CentOSC:9092","topic01"))
.filter(new Fields("value"), new BaseFilter() {
@Override
public boolean isKeep(TridentTuple tuple) {
return !tuple.getStringByField("value").contains("error");
}
})
.peek((tuple) -> System.out.println(tuple));
4.each
参数传递可以是BaseFunction(需要添加fields)和BaseFilter(等价于Filter)
- basefunction
tridentTopology.newStream("KafkaSpoutOpaque",KafkaSpoutUtils.buildKafkaSpoutOpaque("CentOSA:9092,CentOSB:9092,CentOSC:9092","topic01"))
.each(new Fields("value"), new BaseFunction() {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
collector.emit(new Values(tuple.getStringByField("value")));
}
}, new Fields("other"))
.peek((tuple) -> System.out.println(tuple));
- baseFilter
tridentTopology.newStream("KafkaSpoutOpaque",KafkaSpoutUtils.buildKafkaSpoutOpaque("CentOSA:9092,CentOSB:9092,CentOSC:9092","topic01"))
.each(new Fields("value"), new BaseFilter() {
@Override
public boolean isKeep(TridentTuple tuple) {
return !tuple.getStringByField("value").contains("error");
}
})
.peek((tuple) -> System.out.println(tuple));
5.project
投影/过滤Tuple中无用field
tridentTopology.newStream("KafkaSpoutOpaque",KafkaSpoutUtils.buildKafkaSpoutOpaque("CentOSA:9092,CentOSB:9092,CentOSC:9092","topic01"))
.project(new Fields("value","timestamp"))
.peek((tuple) -> System.out.println(tuple));
6.分区和聚合-无状态
- 定义计数聚合器CountAggregater
public class CountAggregater extends BaseAggregator<Map<String,Integer>> {
@Override
public Map<String, Integer> init(Object batchId, TridentCollector collector) {
return new HashMap<>();
}
//对countle累计求和
@Override
public void aggregate(Map<String, Integer> val, TridentTuple tuple, TridentCollector collector) {
String word = tuple.getStringByField("key");
Integer count=tuple.getIntegerByField("count");
if(val.containsKey(word)){
count= val.get(word)+count;
}
val.put(word,count);
}
//完成后emit
@Override
public void complete(Map<String, Integer> val, TridentCollector collector) {
for (Map.Entry<String, Integer> entry : val.entrySet()) {
collector.emit(new Values(entry.getKey(),entry.getValue()));
}
val.clear();
}
}
- 构建topology
public class KafkaTridentTopology {
public static void main(String[] args) throws Exception {
TridentTopology tridentTopology=new TridentTopology();
tridentTopology.newStream("KafkaSpoutOpaque",KafkaSpoutUtils.buildKafkaSpoutOpaque("CentOSA:9092,CentOSB:9092,CentOSC:9092","topic01"))
.parallelismHint(3)//设置分区,并行度
.project(new Fields("value"))//过滤去除无用的field
.flatMap((tuple)-> {//将一个tuple转化为多个tuple
List<Values> list=new ArrayList<>();
String[] tokens = tuple.getStringByField("value").split("\\W+");
for (String token : tokens) {
list.add(new Values(token));
}
return list;
},new Fields("word"))
.map((tuple)->new Values(tuple.getStringByField("word"),1),new Fields("key","count"))//为每一个word设定count初始值为1
.partition(new PartialKeyGrouping(new Fields("key")))
.parallelismHint(5)
.partitionAggregate(new Fields("key","count"),new CountAggregater(),new Fields("word","total"))//分区统计
.peek((tuple) -> System.out.println(tuple));
new LocalCluster().submitTopology("tridentTopology",new Config(),tridentTopology.build());
}
}
(三)Trident状态管理
1.ProcessingGuarantee(处理保证-容错)的三种策略对比
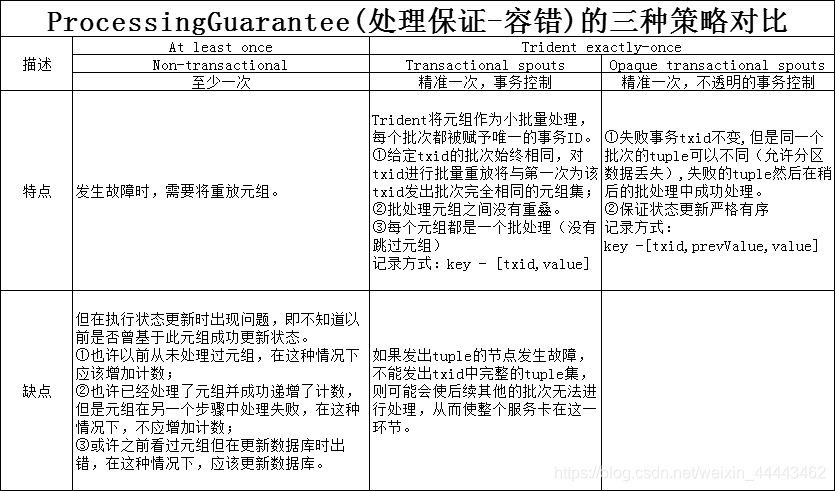
2.统计案例
- 定义KafkaSpoutUtils
public class KafkaSpoutUtils {
public static KafkaSpout<String, String> buildKafkaSpout(String boostrapServers, String topic){
KafkaSpoutConfig<String,String> kafkaspoutConfig=KafkaSpoutConfig.builder(boostrapServers,topic)
.setProp(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer")
.setProp(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer")
.setProp(ConsumerConfig.GROUP_ID_CONFIG,"g1")
.setEmitNullTuples(false)
.setFirstPollOffsetStrategy(FirstPollOffsetStrategy.LATEST)
.setProcessingGuarantee(KafkaSpoutConfig.ProcessingGuarantee.AT_LEAST_ONCE)
.setMaxUncommittedOffsets(10)//一旦分区积压有10个未提交offset,Spout停止poll数据,解决Storm背压问题
.build();
return new KafkaSpout<String, String>(kafkaspoutConfig);
}
//可以保证精准一次更新,推荐使用
public static KafkaTridentSpoutOpaque<String,String> buildKafkaSpoutOpaque(String boostrapServers, String topic){
KafkaTridentSpoutConfig<String, String> kafkaOpaqueSpoutConfig = KafkaTridentSpoutConfig.builder(boostrapServers, topic)
.setProp(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer")
.setProp(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer")
.setProp(ConsumerConfig.GROUP_ID_CONFIG,"g1")
.setFirstPollOffsetStrategy(FirstPollOffsetStrategy.LATEST)
.setRecordTranslator(new Func<ConsumerRecord<String, String>, List<Object>>() {
public List<Object> apply(ConsumerRecord<String, String> record) {
return new Values(record.key(),record.value(),record.timestamp());
}
},new Fields("key","value","timestamp"))
.build();
return new KafkaTridentSpoutOpaque<String, String>(kafkaOpaqueSpoutConfig);
}
}
- 构建Topology
public class KafkaTridentTopology {
public static void main(String[] args) throws Exception {
TridentTopology tridentTopology = new TridentTopology();
//配置JedisPoolConfig参数,用来状态存储
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig.Builder()
.setHost("CentOSA")
.setPort(6379)
.build();
//配置状态存储数据类型参数,“mapstate”为存储在redis中的大key
Options<OpaqueValue> options=new Options<OpaqueValue>();
options.dataTypeDescription=new RedisDataTypeDescription(RedisDataTypeDescription.RedisDataType.HASH,"mapstate");
//数据序列化配置
options.serializer=new JSONOpaqueSerializer();
tridentTopology.newStream("KafkaSpoutOpaque", KafkaSpoutUtils.buildKafkaSpoutOpaque("CentOSA:9092,CentOSB:9092,CentOSC:9092", "topic01"))
.project(new Fields("value"))
.flatMap((tuple) -> {
List<Values> list = new ArrayList<>();
String[] tokens = tuple.getStringByField("value").split("\\W+");
for (String token : tokens) {
list.add(new Values(token));
}
return list;
}, new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(RedisMapState.opaque(jedisPoolConfig,options),new Fields("word"),new Count(),new Fields("count")).newValuesStream()
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input);
}
});
Config config = new Config();
new LocalCluster().submitTopology("tridentTopology", config, tridentTopology.build());
}
}
3.自定义State案例-StateQuery
- 自定义RedisIpState
public class RedisIpState implements State {
private JedisPoolConfig jedisPoolConfig;
public RedisIpState(JedisPoolConfig jedisPoolConfig) {
this.jedisPoolConfig = jedisPoolConfig;
}
@Override
public void beginCommit(Long txid) {
}
@Override
public void commit(Long txid) {
}
public static StateFactory ipSateFactory(JedisPoolConfig jedisPoolConfig){
return new StateFactory(){
@Override
public State makeState(Map<String, Object> conf, IMetricsContext metrics, int partitionIndex, int numPartitions) {
return new RedisIpState(jedisPoolConfig);
}
};
}
public List<String> batchRetrive(List<TridentTuple> tuples) {
Jedis jedis=new Jedis(jedisPoolConfig.getHost(),jedisPoolConfig.getPort());
List<String> lastIps=new ArrayList<>();
for (TridentTuple tuple : tuples) {
String lastIp = jedis.get(tuple.getStringByField("userid"));
if(lastIp!=null){
lastIps.add(lastIp);
}else{
lastIps.add("");
}
}
jedis.close();
return lastIps;
}
}
- 自定义IpQueryFunction
public class IpQueryFunction extends BaseQueryFunction<RedisIpState, String> {
@Override
public List<String> batchRetrieve(RedisIpState state, List<TridentTuple> tuples) {
return state.batchRetrive(tuples);
}
@Override
public void execute(TridentTuple tuple, String lastIp, TridentCollector collector) {
System.out.println(tuple);
collector.emit(new Values(lastIp));
}
}
- 构建Topology
public class KafkaTridentTopology {
public static void main(String[] args) throws Exception {
TridentTopology tridentTopology = new TridentTopology();
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig.Builder().
setHost("CentOSA")
.setPort(6379).build();
TridentState ipstate = tridentTopology.newStaticState(RedisIpState.ipSateFactory(jedisPoolConfig));
//INFO 001 2019:10:10 10:00:00 1.202.251.26
tridentTopology.newStream("KafkaSpoutOpaque", KafkaSpoutUtils.buildKafkaSpoutOpaque("CentOSA:9092,CentOSB:9092,CentOSC:9092", "topic01"))
.project(new Fields("value"))
.map((tuple)-> {
String value = tuple.getStringByField("value");
String[] tokens = value.split("\\s+");
return new Values(tokens[1],tokens[4] );
},new Fields("userid","ip"))
.stateQuery(ipstate,new Fields("userid","ip"),new IpQueryFunction(),new Fields("hip"))
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input);
}
});
Config config = new Config();
new LocalCluster().submitTopology("tridentTopology", config, tridentTopology.build());
}
}
4.自定义State案例-partitionPersist
- 自定义RedisIpState
public class RedisIpState implements State {
private JedisPoolConfig jedisPoolConfig;
public RedisIpState(JedisPoolConfig jedisPoolConfig) {
this.jedisPoolConfig=jedisPoolConfig;
}
@Override
public void beginCommit(Long txid) {
}
@Override
public void commit(Long txid) {
}
public static StateFactory ipUpdateStateFactory(JedisPoolConfig jedisPoolConfig){
return new StateFactory() {
@Override
public State makeState(Map<String, Object> conf, IMetricsContext metrics, int partitionIndex, int numPartitions) {
return new RedisIpState(jedisPoolConfig);
}
};
}
public void batchUpdate(List<TridentTuple> tuples) {
Jedis jedis=new Jedis(jedisPoolConfig.getHost(),jedisPoolConfig.getPort());
Pipeline pipelined = jedis.pipelined();
for (TridentTuple tuple : tuples) {
pipelined.set(tuple.getStringByField("userid"),tuple.getStringByField("ip"));
}
pipelined.sync();
jedis.close();
}
}
- 自定义UserIPSateUpdater
public class UserIPSateUpdater extends BaseStateUpdater<RedisIpState> {
@Override
public void updateState(RedisIpState state, List<TridentTuple> tuples, TridentCollector collector) {
state.batchUpdate(tuples);
}
}
- 构建Topology
public class KafkaTridentTopology {
public static void main(String[] args) throws Exception {
TridentTopology tridentTopology = new TridentTopology();
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig.Builder().
setHost("CentOSA")
.setPort(6379).build();
//INFO 001 2019:10:10 10:00:00 1.202.251.26
tridentTopology.newStream("KafkaSpoutOpaque", KafkaSpoutUtils.buildKafkaSpoutOpaque("CentOSA:9092,CentOSB:9092,CentOSC:9092", "topic01"))
.project(new Fields("value"))
.map((tuple)-> {
String value = tuple.getStringByField("value");
String[] tokens = value.split("\\s+");
return new Values(tokens[1],tokens[4] );
},new Fields("userid","ip"))
.partitionPersist(RedisIpState.ipUpdateStateFactory(jedisPoolConfig),
new Fields("userid","ip"),new UserIPSateUpdater(),new Fields());
Config config = new Config();
new LocalCluster().submitTopology("tridentTopology", config, tridentTopology.build());
}
}
5.自定义State案例-persistentAggregate
- 自定义MyMapState
public class MyMapState implements IBackingMap<OpaqueValue<Integer>> {
private HashMap<String,OpaqueValue<Integer>> db =new HashMap<>();
public static StateFactory opaqueFactory(){
return new StateFactory() {
@Override
public State makeState(Map<String, Object> conf, IMetricsContext metrics, int partitionIndex, int numPartitions) {
CachedMap c = new CachedMap (new MyMapState(), 1024);
MapState mapState = OpaqueMap.build(c);
return new SnapshottableMap(mapState,new Values("gloableKeys"));
}
};
}
@Override
public List<OpaqueValue<Integer>> multiGet(List<List<Object>> keys) {
List<OpaqueValue<Integer>> values=new ArrayList<>(keys.size());
for (List<Object> key : keys) {
System.out.println(key.get(0));
OpaqueValue<Integer> histryValue= db.get(key);
if (histryValue==null){
values.add(new OpaqueValue<Integer>(-1L,null,null));
}else{
values.add(histryValue);
}
}
return values;
}
@Override
public void multiPut(List<List<Object>> keys, List<OpaqueValue<Integer>> vals) {
for (int i = 0; i < keys.size(); i++) {
OpaqueValue<Integer> v=vals.get(i);
db.put(keys.get(i).get(0).toString(),v);
}
}
}
-构建Topology
public class KafkaTridentTopology {
public static void main(String[] args) throws Exception {
TridentTopology tridentTopology = new TridentTopology();
tridentTopology.newStream("KafkaSpoutOpaque", KafkaSpoutUtils.buildKafkaSpoutOpaque("CentOSA:9092,CentOSB:9092,CentOSC:9092", "topic01"))
.project(new Fields("value"))
.flatMap((tuple) -> {
List<Values> list = new ArrayList<>();
String[] tokens = tuple.getStringByField("value").split("\\W+");
for (String token : tokens) {
list.add(new Values(token));
}
return list;
}, new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(MyMapState.opaqueFactory(),new Fields("word"),new Count(),new Fields("count")).newValuesStream()
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input);
}
});
Config config = new Config();
new LocalCluster().submitTopology("tridentTopology", config, tridentTopology.build());
}
}
6.窗口案例-1
public class WordCountAggregator extends BaseAggregator<Map<String,Integer>> {
@Override
public Map<String, Integer> init(Object batchId, TridentCollector collector) {
return new HashMap<>();
}
@Override
public void aggregate(Map<String, Integer> val, TridentTuple tuple, TridentCollector collector) {
String key = tuple.getStringByField("key");
Integer count = tuple.getIntegerByField("count");
Integer historyValue = val.get(key);
if(historyValue==null){
val.put(key,count);
}else{
val.put(key,historyValue+count);
}
}
@Override
public void complete(Map<String, Integer> val, TridentCollector collector) {
for (Map.Entry<String, Integer> entry : val.entrySet()) {
collector.emit(new Values(entry.getKey(),entry.getValue()));
}
}
}
public class TridentWindowDemo {
public static void main(String[] args) throws Exception {
TridentTopology tridentTopology = new TridentTopology();
tridentTopology.newStream("KafkaSpoutOpaque",
KafkaSpoutUtils.buildKafkaSpoutOpaque("CentOSA:9092,CentOSB:9092,CentOSC:9092", "topic01"))
.project(new Fields("value"))
.flatMap((tuple) -> {
List<Values> list = new ArrayList<>();
String[] tokens = tuple.getStringByField("value").split("\\W+");
for (String token : tokens) {
list.add(new Values(token));
}
return list;
}, new Fields("word"))
.map((tuple) -> new Values(tuple.getStringByField("word"), 1), new Fields("key", "count"))
.slidingWindow(
BaseWindowedBolt.Duration.seconds(10),
BaseWindowedBolt.Duration.seconds(5),
new InMemoryWindowsStoreFactory(),
new Fields("key","count"),
new WordCountAggregator(),
new Fields("key","total")
)
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input);
}
});
new LocalCluster().submitTopology("aa",new Config(),tridentTopology.build());
}
}
7.窗口案例-2
public class WordCountAggregator extends BaseAggregator<Map<String,Integer>> {
@Override
public Map<String, Integer> init(Object batchId, TridentCollector collector) {
return new HashMap<>();
}
@Override
public void aggregate(Map<String, Integer> val, TridentTuple tuple, TridentCollector collector) {
String key = tuple.getStringByField("key");
Integer count = tuple.getIntegerByField("count");
Integer historyValue = val.get(key);
if(historyValue==null){
val.put(key,count);
}else{
val.put(key,historyValue+count);
}
}
@Override
public void complete(Map<String, Integer> val, TridentCollector collector) {
for (Map.Entry<String, Integer> entry : val.entrySet()) {
collector.emit(new Values(entry.getKey(),entry.getValue()));
}
}
}
public class TridentWindowDemo {
public static void main(String[] args) throws Exception {
TridentTopology tridentTopology = new TridentTopology();
WindowConfig wc= SlidingDurationWindow.of(BaseWindowedBolt.Duration.seconds(10),
BaseWindowedBolt.Duration.seconds(5));
tridentTopology.newStream("KafkaSpoutOpaque",
KafkaSpoutUtils.buildKafkaSpoutOpaque("CentOSA:9092,CentOSB:9092,CentOSC:9092", "topic01"))
.project(new Fields("value"))
.flatMap((tuple) -> {
List<Values> list = new ArrayList<>();
String[] tokens = tuple.getStringByField("value").split("\\W+");
for (String token : tokens) {
list.add(new Values(token));
}
return list;
}, new Fields("word"))
.map((tuple) -> new Values(tuple.getStringByField("word"), 1), new Fields("key", "count"))
.window(wc,
new InMemoryWindowsStoreFactory(),
new Fields("word","count"),
new WordCountAggregator(),
new Fields("word","total")
)
.peek(new Consumer() {
@Override
public void accept(TridentTuple input) {
System.out.println(input);
}
});
new LocalCluster().submitTopology("aa",new Config(),tridentTopology.build());
}
}
8.Storm对象序列化
- Storm-1.x版本
在storm中流动的数据流格式可以多种多样,数据流可以以各种格式的形式在task之间进行传递。因为storm中可以对数据格式自动进行序列化,但是也只是对于一些常见格式能进行序列化,其中包括int, short, long, float, double, bool, byte, string, byte arrays,也就是说用户可以直接在task之间传递这些类型而不需要做其它的操作,但是对于一些其它类型,或是自己定义的一些类型(比如要在task之间传递一个对象格式),就需要自己进行序列化.
public class UserOrder implements Serializable {
private Integer userid;
private String username;
private String itemname;
private double cost;
...
}
Config conf = new Config();
//如果是Storm-1.x版本,需要在Tuple中传递实体类,需要注册改实体类
//目前测试版本是Storm-2.0.0,不需注册序列化
conf.registerSerialization(UserOrder.class);
StormSubmitter.submitTopology("localDemo",conf,tridentTopology.build());
目前如果使用最新的Storm-2.0 用户只需要自定义实体类型实现序列化接口即可,无需注册序列化。
(四)Trident状态管理
Stream API
Stream API是Storm的另一种替代接口。它提供了一种用于表达流式计算的类型化API,并支持功能样式操作。
快速入门
StreamBuilder builder = new StreamBuilder();
KafkaSpout<String, String> spout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092",
"topic01");
builder.newStream(spout, TupleValueMappers.<Long,String,String>of(1,3,4),3)
.peek(new Consumer<Tuple3<Long, String, String>>() {
@Override
public void accept(Tuple3<Long, String, String> input) {
System.out.println(input._1+" "+input._2+" "+input._3);
}
});
Config conf = new Config();
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("stream",conf,
builder.build());
Stream APIs
基本转换
builder.newStream(spout, TupleValueMappers.<Long,String,String>of(1,3,4),3)
.filter((t)-> t._3.contains("error"))
.peek((t)-> System.out.println(t));
builder.newStream(spout, TupleValueMappers.<Long,String,String>of(1,3,4),3)
.map((t)-> t._3)
.peek((t)-> System.out.println(t));
builder.newStream(spout, TupleValueMappers.<Long,String,String>of(1,3,4),3)
.flatMap(t-> Arrays.asList(t._3.split("\\s")))
.map(t-> Pair.<String,Integer>of(t,1))
.peek(t -> System.out.println(t));
窗口操作
builder.newStream(spout, TupleValueMappers.<Long,String,String>of(1,3,4),3)
.flatMap(t-> Arrays.asList(t._3.split("\\s")))
.map(t-> Pair.<String,Integer>of(t,1))
.window(SlidingWindows.of(BaseWindowedBolt.Duration.seconds(5),BaseWindowedBolt.Duration.seconds(2)))
.peek(input->System.out.println(input));
针对KeyValue pair 转换
- flatMapToPair (等价 flatMap+mapToPair)
builder.newStream(spout, TupleValueMappers.<Long, String, String>of(1, 3, 4), 3)
.flatMapToPair(t -> {
String[] tokens = t._3.split("\\s");
List<Pair<String,Integer>> pairList=new ArrayList<>();
for (String token : tokens) {
pairList.add(Pair.<String, Integer>of(token, 1));
}
return pairList;
}).peek(t -> System.out.println(t));
- mapToPair
builder.newStream(spout, TupleValueMappers.<Long, String, String>of(1, 3, 4), 3)
.flatMap(v->Arrays.asList(v._3.split("\\s+")))
.mapToPair(t -> Pair.<String, Integer>of(t, 1))
.peek(t -> System.out.println(t));
聚合
- 单个值聚合
builder.newStream(spout, TupleValueMappers.<Long, String, String>of(1, 3, 4), 3)
.flatMap(v->Arrays.asList(v._3.split("\\s+")))
.map(t-> Integer.parseInt(t))
.window(SlidingWindows.of(BaseWindowedBolt.Duration.seconds(5),BaseWindowedBolt.Duration.seconds(2)))
//.reduce((v1,v2)->v1+v2)
.aggregate(0,(v1,v2)->v1+v2,(v1,v2)->v1+v2)
.peek(t -> System.out.println(t));
- 聚合key-value
builder.newStream(spout, TupleValueMappers.<Long, String, String>of(1, 3, 4), 3)
.flatMap(v->Arrays.asList(v._3.split("\\s+")))
.mapToPair(t-> Pair.<String,Integer>of(t,1))
.window(SlidingWindows.of(BaseWindowedBolt.Duration.seconds(5),BaseWindowedBolt.Duration.seconds(2)))
.reduceByKey((v1,v2)->v1+v2)
//.aggregateByKey(0,(v1,v2)->v1+v2,(v1,v2)->v1+v2)
.peek(t -> System.out.println(t));
- groupBy
builder.newStream(spout, TupleValueMappers.<Long, String, String>of(1, 3, 4), 3)
.flatMap(v->Arrays.asList(v._3.split("\\s+")))
.mapToPair(t-> Pair.<String,Integer>of(t,1))
.window(SlidingWindows.of(BaseWindowedBolt.Duration.seconds(5),BaseWindowedBolt.Duration.seconds(2)))
.groupByKey()
.map(t-> {
int total=0;
for (Integer integer : t._2) {
total+=integer;
}
return Pair.<String,Integer>of(t._1,total);
}).peek(t-> System.out.println(t));
- countByKey
builder.newStream(spout, TupleValueMappers.<Long, String, String>of(1, 3, 4), 3)
.flatMap(v->Arrays.asList(v._3.split("\\s+")))
.mapToPair(t-> Pair.<String,Integer>of(t,1))
.window(SlidingWindows.of(BaseWindowedBolt.Duration.seconds(5),BaseWindowedBolt.Duration.seconds(2)))
.countByKey().peek(t-> System.out.println(t));
重新分区
重新分区操作会重新分区当前流并返回具有指定分区数的新流。对结果流的进一步操作将在该并行级别上执行。重新分区可用于增加或减少流中操作的并行性。
builder.newStream(spout, TupleValueMappers.<Long, String, String>of(1, 3, 4), 3)
.flatMap(v->Arrays.asList(v._3.split("\\s+")))
.repartition(4)
.mapToPair(t-> Pair.<String,Integer>of(t,1))
.repartition(2)
.window(SlidingWindows.of(BaseWindowedBolt.Duration.seconds(5),BaseWindowedBolt.Duration.seconds(2)))
.countByKey().peek(t-> System.out.println(t));
注意:repartition操作会产生网络操作- shuffle
输出算子-Sinks
print和peek
builder.newStream(spout, TupleValueMappers.<Long, String, String>of(1, 3, 4), 3)
.flatMap(v->Arrays.asList(v._3.split("\\s+")))
.repartition(4)
.mapToPair(t-> Pair.<String,Integer>of(t,1))
.repartition(2)
.window(SlidingWindows.of(BaseWindowedBolt.Duration.seconds(5),BaseWindowedBolt.Duration.seconds(2)))
.countByKey().print();
print 返回值是void表示流的终止,后续无法追加算子。而Peek作为程序执行探针,用于debug调试,并不影响程序正常执行的流程。
forEach
builder.newStream(spout, TupleValueMappers.<Long, String, String>of(1, 3, 4), 3)
.flatMap(v->Arrays.asList(v._3.split("\\s+")))
.repartition(4)
.mapToPair(t-> Pair.<String,Integer>of(t,1))
.repartition(2)
.window(SlidingWindows.of(BaseWindowedBolt.Duration.seconds(5),BaseWindowedBolt.Duration.seconds(2)))
.countByKey()
.forEach(t-> System.out.println(t));
to
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig.Builder().setHost("CentOSA").setPort(6379).build();
KafkaSpout<String, String> spout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092",
"topic01");
builder.newStream(spout, TupleValueMappers.<Long, String, String>of(1, 3, 4), 3)
.flatMap(v->Arrays.asList(v._3.split("\\s+")))
.repartition(4)
.mapToPair(t-> Pair.<String,Integer>of(t,1))
.repartition(2)
.window(SlidingWindows.of(BaseWindowedBolt.Duration.seconds(5),BaseWindowedBolt.Duration.seconds(2)))
.countByKey()
.to(new RedisStoreBolt(jedisPoolConfig,new WordCountRedisStoreMapper()));
WordCountRedisStoreMapper
public class WordCountRedisStoreMapper implements RedisStoreMapper {
@Override
public RedisDataTypeDescription getDataTypeDescription() {
return new RedisDataTypeDescription(RedisDataTypeDescription.RedisDataType.HASH,"swc");
}
@Override
public String getKeyFromTuple(ITuple tuple) {
System.out.println(tuple.getFields());//默认field key,value
return tuple.getString(0);
}
@Override
public String getValueFromTuple(ITuple tuple) {
return tuple.getLong(1)+"";
}
}
分支算子
branch
KafkaSpout<String, String> spout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092",
"topic01");
Stream<Tuple3<Long, String, String>>[] streams = builder.newStream(spout, TupleValueMappers.<Long, String, String>of(1, 3, 4), 3)
.branch(
t-> t._3.contains("info"),
t->t._3.contains("error"),
t-> true
);
Stream<Tuple3<Long, String, String>> infoStream = streams[0];
Stream<Tuple3<Long, String, String>> errorStream = streams[1];
Stream<Tuple3<Long, String, String>> otherStream = streams[2];
infoStream.peek(t -> System.out.println("info:"+t));
errorStream.peek(t -> System.out.println("error:"+t));
otherStream.peek(t -> System.out.println("other:"+t));
Join
join操作将一个流的值与来自另一个流的具有相同键的值连接起来。
KafkaSpout<String, String> userSpout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092",
"usertopic");
KafkaSpout<String, String> orderSpout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092",
"ordertopic");
//001 zhangsan
PairStream<String, String> userPair = builder.newStream(userSpout, TupleValueMappers.<Long, String, String>of(1, 3, 4))
.mapToPair(t -> {
String[] tokens = t._3.split("\\s");
return Pair.<String, String>of(tokens[0], tokens[1]);
});
//001 apple 100
PairStream<String, String> orderPair = builder.newStream(orderSpout, TupleValueMappers.<Long, String, String>of(1, 3, 4))
.mapToPair(t -> {
String[] tokens = t._3.split("\\s");
return Pair.<String, String>of(tokens[0], tokens[1]+":"+tokens[2]);
});
userPair.window(TumblingWindows.of(BaseWindowedBolt.Duration.seconds(5)))
.leftOuterJoin(orderPair).peek(t -> System.out.println(t));
CoGroupByKey
coGroupByKey使用其他流中具有相同键的值对此流的值进行分组。
KafkaSpout<String, String> userSpout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092",
"usertopic");
KafkaSpout<String, String> orderSpout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092",
"ordertopic");
//001 zhangsan
PairStream<String, String> userPair = builder.newStream(userSpout, TupleValueMappers.<Long, String, String>of(1, 3, 4))
.mapToPair(t -> {
String[] tokens = t._3.split("\\s");
return Pair.<String, String>of(tokens[0], tokens[1]);
});
//001 apple 100
PairStream<String, String> orderPair = builder.newStream(orderSpout, TupleValueMappers.<Long, String, String>of(1, 3, 4))
.mapToPair(t -> {
String[] tokens = t._3.split("\\s");
return Pair.<String, String>of(tokens[0], tokens[1]+":"+tokens[2]);
});
userPair.coGroupByKey(orderPair).peek(t-> System.out.println(t));
State
updateStateByKey
builder.newStream(userSpout, TupleValueMappers.<Long, String, String>of(1, 3, 4))
.map(t->t._3)
.flatMap(line-> Arrays.asList(line.split("\\s+")))
.mapToPair(word-> Pair.<String,Integer>of(word,1))
.updateStateByKey(0,(v1,v2)->v1+v2)
.toPairStream()
.peek( t -> System.out.println(t));
Config conf = new Config();
conf.put(Config.TOPOLOGY_STATE_PROVIDER,"org.apache.storm.redis.state.RedisKeyValueStateProvider");
Map<String,Object> stateConfig=new HashMap<String,Object>();
Map<String,Object> redisConfig=new HashMap<String,Object>();
redisConfig.put("host","CentOSA");
redisConfig.put("port",6379);
stateConfig.put("jedisPoolConfig",redisConfig);
ObjectMapper objectMapper=new ObjectMapper();
conf.put(Config.TOPOLOGY_STATE_PROVIDER_CONFIG,objectMapper.writeValueAsString(stateConfig));
stateQuery
KafkaSpout<String, String> userSpout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092",
"topic01");
StreamState<String, Integer> streamState = builder.newStream(userSpout, TupleValueMappers.<Long, String, String>of(1, 3, 4))
.map(t -> t._3)
.flatMap(line -> Arrays.asList(line.split("\\s+")))
.mapToPair(word -> Pair.<String, Integer>of(word, 1))
.updateStateByKey(0, (v1, v2) -> v1 + v2);
KafkaSpout<String, String> querySpout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092",
"topic02");
builder.newStream(querySpout, TupleValueMappers.<Long, String, String>of(1, 3, 4))
.map(t -> t._3)
.stateQuery(streamState).peek(t-> System.out.println(t));














 663
663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









