






商品销售关联分析
导入相关库
import pandas as pd
from mlxtend.frequent_patterns import apriori,association_rules
from mlxtend.preprocessing import TransactionEncoder
读取数据
#显示所有列
pd.set_option('display.max_columns',None)
#导入数据
f=r'D:\purchase.csv'
df=pd.read_csv(f,encoding='gbk')
print('The data size is ',df.shape)
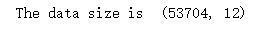
一共53704行数据,12列信息
查看数据
df.head(5)
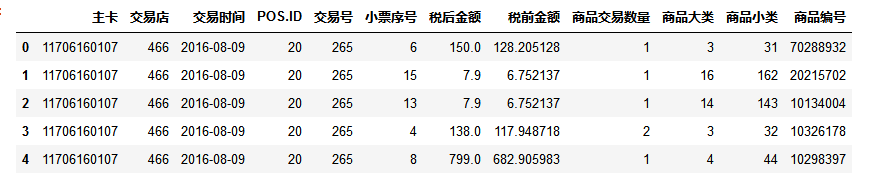
查看数据是否存在缺失
df.info()

无缺失数据
数据编码
按照交易号、商品大类对商品交易数量分组计数;之后使用unstack函数将数据从“花括号结构”变成“表格”结构并用reset_index还原索引重新变为默认索引;最后将空值用0进行填充,设置交易号为索引。
basket = (df
.groupby(['交易号','商品大类'])['商品交易数量'].count()
.unstack().reset_index().fillna(0).set_index('交易号'))
basket.shape
basket.head(5)
结果如下:一共有595次交易,23个商品大类。
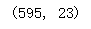
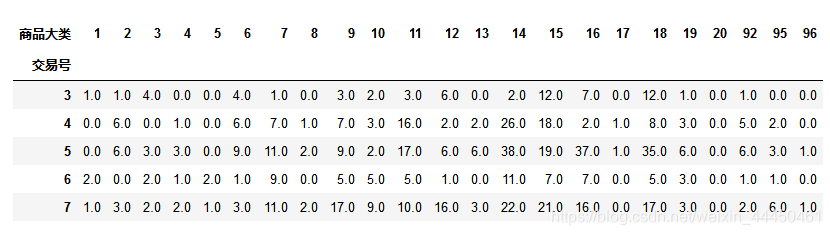
由于关联算法只接受0和1的值,所以我们要对大于等于1 的值转换为1,即购买了该商品;将小于等于0的值转换为0,即未购买该商品。定义好函数之后使用applymap()作用于DataFrame每一个元素。
def encode_units(x):
if x <= 0:
return 0
if x >= 1:
return 1
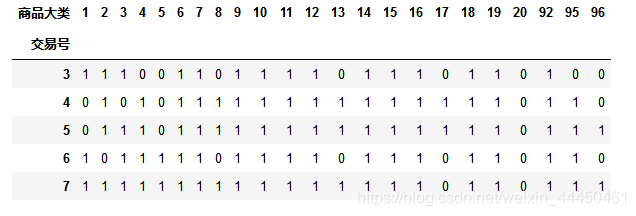
basket_sets = basket.applymap(encode_units)
basket_sets.head()
使用算法进行关联运算
将数据导入频繁项集模型,设置最小支持度为“0.6”并使用原列名,对频繁项集进行支持度排序,并查看数据
frequent_itemsets = apriori(basket_sets,
min_support=0.6,
use_colnames=True,
max_len=None)
print('frequent_itemsets num is:', len(frequent_itemsets))
frequent_itemsets.sort_values(by='support',
ascending=False,
inplace=True)
frequent_itemsets.head(10)

总共有61个频繁项集,排名前10位的类目,有1-2个类目相关联,且两类目相关联的数据的子类目均为支持度前四的类目。可以将这些商品类目的位置摆放在一起,提高转化。
将得到的频繁项集数据导入关联规则模型,设置关联规则为“提升度”,最小值为“1”,对关联规则进行规则置信度排序,并查看数据
rules=association_rules(frequent_itemsets,metric='lift',min_threshold=1)
print('rules num is ',len(rules))
rules.sort_values(by='confidence',ascending=False,inplace=True)
rules.head(10)
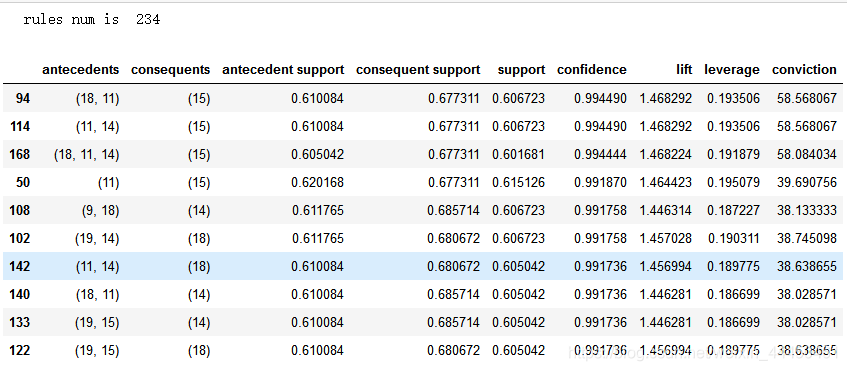
关联规则有234项,前10项关联规则的置信度均达到0.99以上,平均提升度在1.4以上。
筛选出置信度>=0.95的关联规则,最后符合条件的规则有113个。
print('selected rule num is:',len(selected_rules))
selected_rules.head(10)
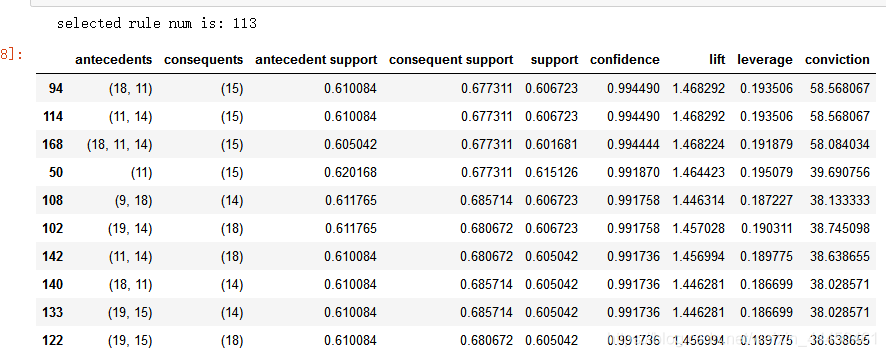
从数据中可以得到,(18,11)或(11,14)或(18,11,14)-> 15的置信度 > 0.99,而它们的提升度达到了1.468。
也就意味着,同时购买(18)、(11)和(14)中的两种或3种商品的人,很有可能再购买1.468份15,所以可以将他们组合一起出售。

















 2184
2184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









