







文章目录
一、下载YOLOv5官方代码
下载网站:https://github.com/ultralytics/yolov5/tree/v5.0
注意:这里最好下载对应的v5.0版本,别的版本可能会出现奇奇怪怪的错误。
下载之后,解压,最终得到的文件夹内容应该是这样的:
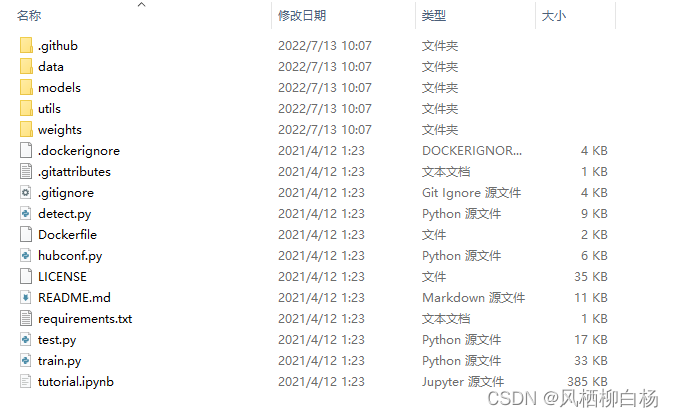
二、准备数据集
1、下载VOC2007数据集
数据集百度网盘地址:
链接:https://pan.baidu.com/s/1JaorrGVczVFdHSmpuHml0A
提取码:lhpl
2、准备数据
(1)挑选数据
你可以从VOC2007中挑选出若干张图片(我选择10张),从Annotations和JPEGImages中分别挑选10个文件。
(2)在训练文件夹下创建数据集格式
在刚才下载的YOLOv5文件夹下新建文件夹如下格式:
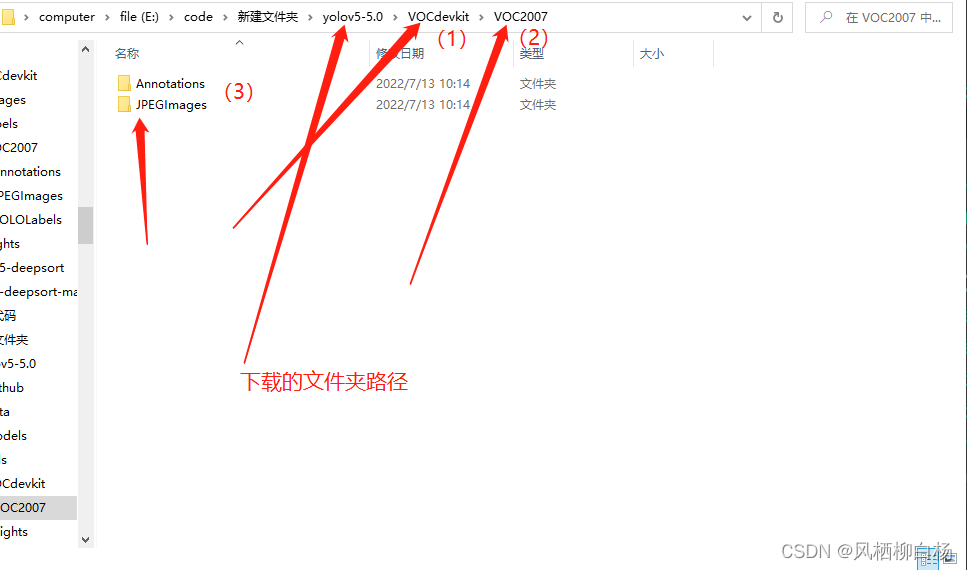
将挑选的数据按照格式放入文件夹,图片放入JPEGImages,Xml文件就放入Annotations中。
3、制作数据集
运行voc_to_yolo.py文件,这里的文件链接:
链接:https://pan.baidu.com/s/1tHb6wrSFudDxWJ-T-RppfA
提取码:lhpl
这里需要更改的地方:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
'''classes = ["aeroplane", "bicycle", "bird", "boat", "bottle","bus","car","cat",
"chair", "cow", "diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"]'''
classes = ["head"] # 表示类别,如果是VOC数据集的话,就使用上边的classes
# classes=["ball"]
TRAIN_RATIO = 70 # 表示训练集和测试集的比例,可以自行更改
更改之后,运行,最终得到的数据集格式如图所示:
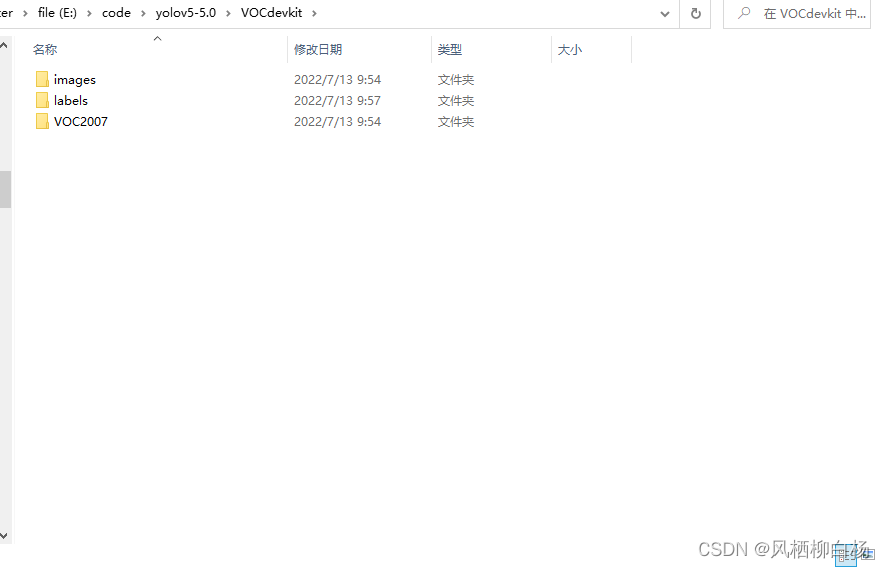
这里的images是训练所用的图片数据集,labels就是训练所用的标签数据集,在这里可以把labels中的文件打开看一下,是否正常,一般不为空。
三、训练
1、更改voc.yaml
data/voc.yaml要更改为和数据集一样的格式,其中的要更改的地方如下所示:
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC/
# Train command: python train.py --data voc.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /VOC
# /yolov5
# download command/URL (optional)
download: bash data/scripts/get_voc.sh
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: VOCdevkit/images/train/ # 16551 images
val: VOCdevkit/images/val/ # 4952 images
# number of classes
nc: 20
# class names
#names: [ 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
# 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor' ]
names: [ 'head' ]
需要更改的一般是路径(train / val)、类别数(nc)、以及names.
2、更改train.py中的参数
在这里插入代码片
parser.add_argument('--weights', type=str, default='weights/yolov5m.pt', help='initial weights path') # 预训练权重,需要从官网下载一个,这里我使用的是YOLOv5m.pt
parser.add_argument('--cfg', type=str, default='models/yolov5m.yaml', help='model.yaml path') # 这里最好设置和预训练权重一致,但也可以不设置
parser.add_argument('--data', type=str, default='data/voc.yaml', help='data.yaml path') # voc数据集的超参数,把路径放入
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300) # 迭代次数,一般大于100
parser.add_argument('--batch-size', type=int, default=1, help='total batch size for all GPUs') # batch_size,根据电脑性能设置
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
opt = parser.parse_args()
需要更改的地方已经全部设置完毕,没有标出的,就是不需要设置的地方,到这里可以运行一下试试。
3、运行
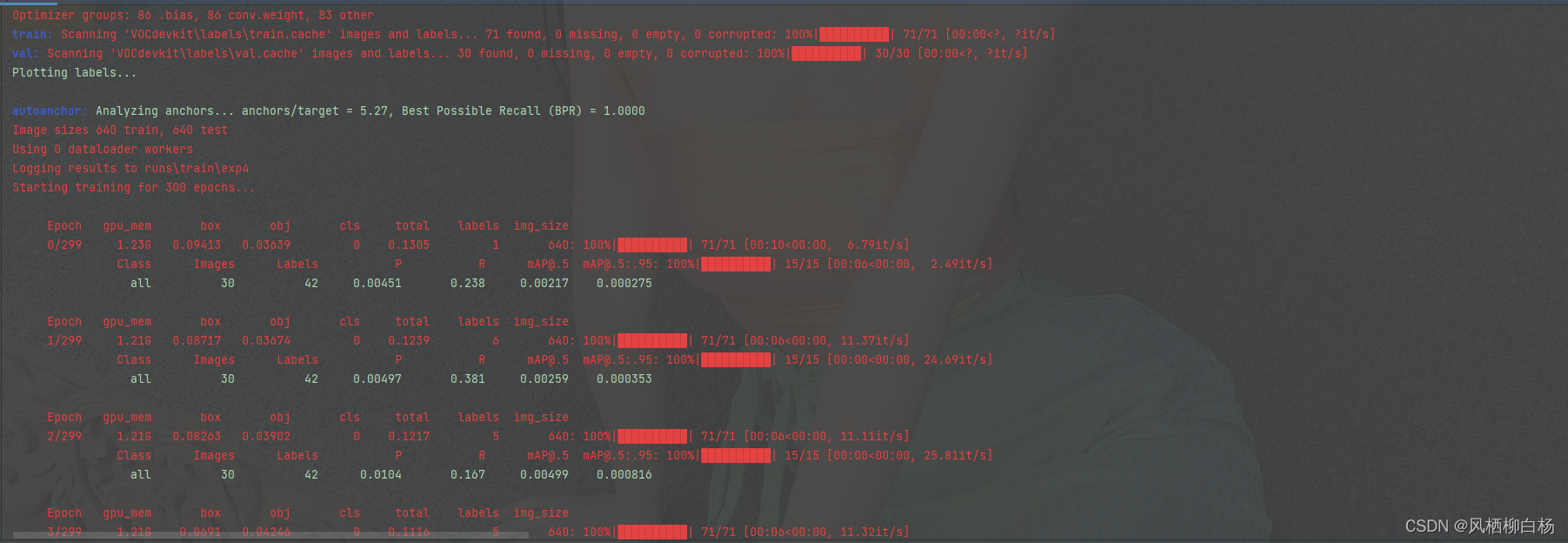
如图所示,出现进度条才表示训练成功,如果没有的话,就说明训练出错。















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











