







1.批量梯度下降(BGD)
我们所说的梯度下降算法一般都默认是批量梯度下降。我们用每个样本去计算每个参数的梯度后,要将这个梯度进行累加求和
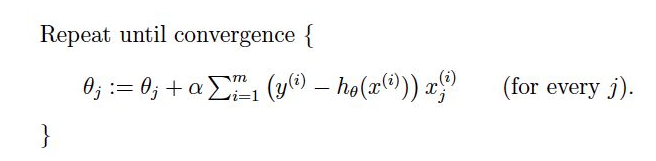
注意这里有一个求和符号,意思就是我们每次计算参数都是用全部的样本来计算这个参数的变化。
优点:
1.每次都使用全部全部数据,能更好的代表样本总体,从而更好的指示了正确的梯度下降的方向。
2.对于凸最优化问题,一定能够收敛的全局最优
3 可以并行化
缺点:
每次都使用全部样本进行计算,会导致计算量很大,对于样本数量很大的情况,这种计算会很耗费时间。
2.随机梯度下降(SGD)
与批量梯度下降不同,随机梯度下降每次迭代只使用一个样本来更新参数,使得训练速度更快。

注意这里是没有求和符号的,因为只用第i个样本来进行这次更新的计算。
优点:
每次迭代只用一个样本来更新参数,这就使得每次迭代的速度会大大加快,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的。
缺点:
很大可能会收敛于局部最优
3.小批量梯度下降(MBGD)
小批量梯度下降实际上是在批量梯度下降和随机梯度下降之间做了个中和。
下面我们假设一共1000个样本,每次迭代用10个样本进行参数更新,那么参数的更新如下。
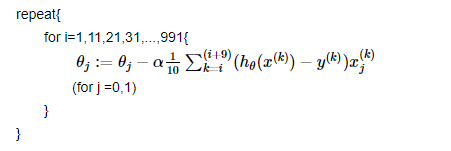
对于小批量梯度下降需要注意的就是这个批量batch大小的选择:
如果选择过大:
1.如果batch过大的话,那么我们每个batch就变化很小,就有点接进去批量梯度下降算法
2.内存可能会撑不住
如果选择过小:
会导致其接近于随机梯度下降算法,它的梯度方向可能没那么准确















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









