









1. 概念:
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
-
Example
你母亲要给你介绍男朋友,对话是这样的:
女儿:多大年纪了?
母亲:26
女儿:长得帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员?
母亲:是,在税务局上班。
女儿:那好,我去见见。 -
question
女儿为什么先问年龄?根据女儿询问的顺序我们可以对女儿的择偶要求做出大致判断,如下所示:

1.由上图可以看出,女儿对年龄看的最重,其次是长相,收入等因素。
2.如果女儿先问对方收入情况,后问年龄。就存在,对方是个有钱的老男人这种情况。
3.这种情况下,女儿肯定不会去见这个男人,而且女儿是问了两个问题后才做出这种决定,相比与首先问对方年龄,这种判断策略明显更加低效。
4.把自认为重要的因素摆在前面,就可以高效的做出判断,是否要去见母亲介绍的男朋友。这就是决策树,其思想来源非常朴素,就是要找到一种数学的方法,快速的判断,应该先看哪个特征,后看哪个特征才能快速得出结论。这也是程序设计中的条件分支结构,最早的决策树就是利用这类结构分隔数据的一种分类学习方法。
2. 决策数分类原理详解
1)信息论基础
-
信息:消除随机不定性的东西。 ----香农
example : 我现在不知道小明的年龄,于是我就问小明 小明回答:我今年18岁。 -----18岁是信息(消除了不确定性) 此时,我已经知道小明的年龄。 这时,小华说到,小明 明年19岁 ------不是信息(此时不存在不确定性,故不是信息) -
question
如何衡量消除不确定性的大小?
信息是个很抽象的概念。人们常常说信息很多,或者信息较少,但却很难说清楚信息到底有多少。比如一本五十万字的中文书到底有多少信息量。
直到1948年,香农提出了“信息熵”的概念,才解决了对信息的量化度量问题。信息熵这个词是C.E.香农从热力学中借用过来的。热力学中的热熵是表示分子状态混乱程度的物理量。香农用信息熵的概念来描述信源的不确定度。
-
信息熵:不确定性的大小,单位 是比特。
公式:
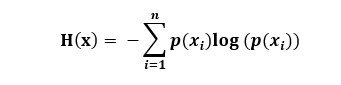
x表示随机变量,n是随机变量x取值的种类数,p(x)表示随机变量x的概率
信息熵 H(x)的取值范围:0 <= H(x)<= logn
变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大
-
条件熵:有两个随机变量D和A,在已知A的情况下,求D的信息熵称之为条件熵。
公式:
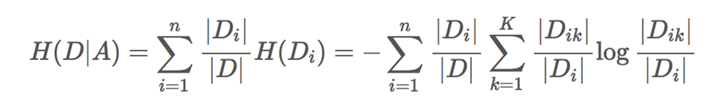
2)原理详解
以下是银行贷款数据:
有四个特征:年龄,工作,房子,信贷情况,来判断是否给此人贷款。

新来一个人,如何调控观看他的特征的顺序,来高效的判断是否贷款给此人?
是否给此人贷款,是一个不确定性的问题,可以根据根据信息熵公式,来求出其不确定性的大小。
H(X) = = -∑P(xi)log(2,P(xi))
令X = {是,否},则
p(是) = 9/15 # 15人中,9个获得贷款
p(否) = 6/15 # 15人中,6个未获贷款故 H(X) = - [(p(是) * logp(是) )+(p(否) * log p(否))]
= - [(9/15 * log9/15 )+(6/15 * log 6/15)]
= 0.971
故,在不知道任何信息的情况下,给这个人贷款的不确定性为0.971。
但是,如果我们能知道此人的一些特征,那么给其贷款的不确定性就可以减小了
如果能够求出,在知道某特征后,不确定性减小的程度,然后进行比较哪个特征使得不确定性减小的最多,那么我们就可以在判断时优先看这个特征。
决策树的划分依据之一:
-
信息增益:信息增益表示得知特征A的信息而使得类D的信息的不确定性减少的程度。
定义:特征A对训练数据集D的 信息增益g(D,A) ,定义为集合D的信息熵H(D)与特征A给定条件下D的 条件熵H(D|A) 之差。
公式:
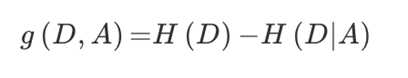
有了信息增益的概念,我们就可以去计算出给定的四个特征值 对于是否给此人贷款所产生的不确定性减小的程度。
这里以年龄为例:
求g(D,年龄),已知 H(D) = 0.971 ,只需求出 H(D|年龄) 即可求出年龄的信息增益。H(D|年龄) 即 求 条件熵
代入公式得:
H(D|年龄) = 1/3 H(青年) + 1/3 H(中年) + 1/3 H(老年) # 青,中,老年 各占样本人数得1/3
H(青年) = -[(2/5 * log 2/5) + (3/5 * log 3/5)]
H(中年) = -[(2/5 * log 2/5) + (3/5 * log 3/5)]
H(老年) = -[(1/5 * log 1/5) + (4/5 * log 4/5)]
故 g(D|年龄) = H(D)- H(D|年龄) = 0.313
所以知道了年龄后对于是否贷款得不确定性减少了0.313
同理,我们可以求出所有四个特征值信息增益:
g(D|年龄) = 0.313
g(D|工作) = 0.363
g(D|房子) = 0.420
g(D|信贷) = 0.324
比较可得 房子 增益最大,不确定性的减少程度是最多的,故选择房子为我们的第一个的判断特征。
故在决定是否给此人贷款前,首先考虑这人是否有房子,如果有房子,则贷款;没有房子,在考虑其他因素。
这也与图中所给得数据相吻合,有房子得人都得到了贷款,没有房子得人中,有工作得都得到了贷款。由此可以得出这棵决策树的样子:

这就是划分决策树的流程。其实处理信息增益外,还可以使用基尼系数,信息增益比来划分决策树,比如,sklearn中,划分决策树的默认依据就是基尼系数,可选信息增益,与信息增益比 ,有兴趣的朋友可以研究一下。
3. 影响参数
是一棵树就有树的高(深)度,决策树也不例外,树高对于判断的准确与效率有着重要影响,如上例,特征 有四个,但是最终在形成决策树时,只是选取了其中的两个特征 来构造这棵树,就可以很好的进行判断了。在多一个特征都会降低判定的效率。
在sklearn中,内置的决策树有这样一个参数 max_depth 即树的深度大小,如果不去设置,决策树会尽最大可能去拟合你的训练集,会使得生成的树特别深,划分的比较细。
对训练集拟合的过好,树分的过细,会使得树的泛化能力比较差,造成在训练集上表现的好,而在测试集中表现一般。
此时,设置树的深度大小,使得这棵树不要过分的延展,是有可能提高准确率的。
4. 总结
- 优点:
简单,易于理解,树木可视化。
需要很少的数据准备,其他技术通常需要数据归一化。 - 缺点:
容易产生过拟合。
决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









