







1. 前言
如今一提到服务器首先就想到 apache tomcat nginx等。虽然这些服务器很优秀。但是对于我们平时拿来练手的一些小项目来说却是大材小用,杀鸡用牛刀,而且上述主流服务器配置起来也略嫌麻烦。俗话说自己动手丰衣足食,今天我们就来实现一个简单的静态web服务器。
2. http协议
谈到浏览器,服务器时,作为计算机爱好者,首先想到的就是www、http、https、html等等,那我们就先来了解一下http协议。
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。http协议是一个基于tcp的应用层协议 ,
简单来说当我们在浏览器里输入一个网址访问网页时,就是在使用http协议,比如我们访问 baidu ,当你在浏览器里输入 ‘www.baidu.com’ 后按下回车时,浏览器会自动判断并补全协议 如下图(此处不深究)


那么问题来了,当我们输入www.baidu.com 时浏览器向百度的服务器发送了什么内容呢? 接下来我们借助 “网络调试助手” 来模拟一次浏览器向服务器请求和服务器应答的过程。
网络调试助手基本配置如下图:
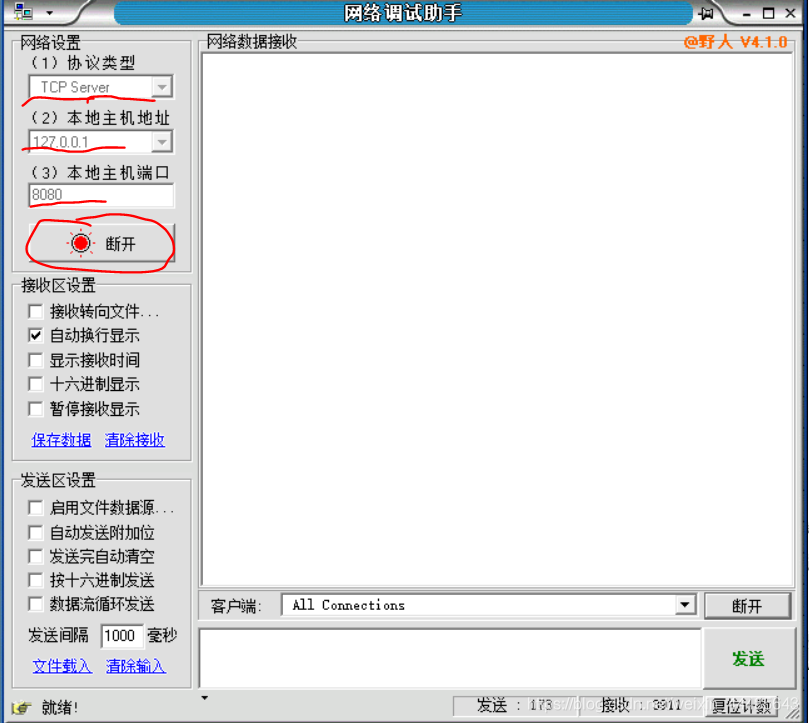
我在这里选择了127.0.0.1本机回环地址,端口8080 为大家演示
-
配置好后点击连接。
-
然后打开浏览器输入 http://127.0.0.1:8080
我们看到小圈圈在转,说明正在请求 -
回到网络调试助手,发现在网络数据接受区出现如下内容
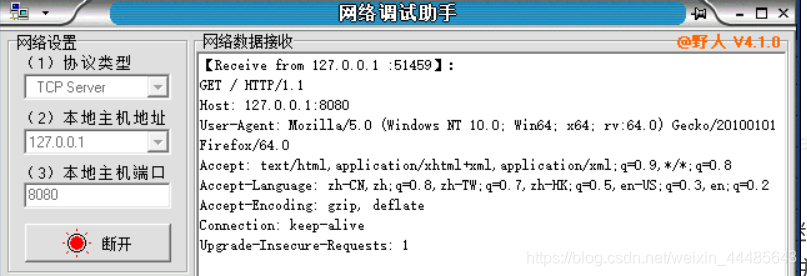
4.紧接着我们在发送区输入 HTTP/1.1 200 OK 回车,空一行后 继续输入HelloWorld 点击发送,点击断开,然后返回浏览器,发现小圈圈停止了转动,并在页面显示出了HelloWorld
在这里插入图片描述
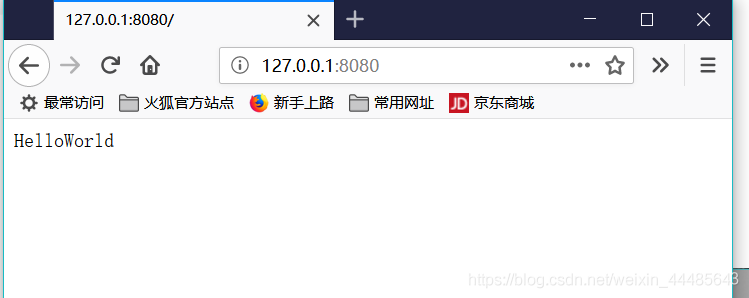
5.这就是浏览器也与服务器之间一次简单的请求,应答
一、 http协议请求部分
我们在浏览器打开调试器,重复上述操作,得到如下结果
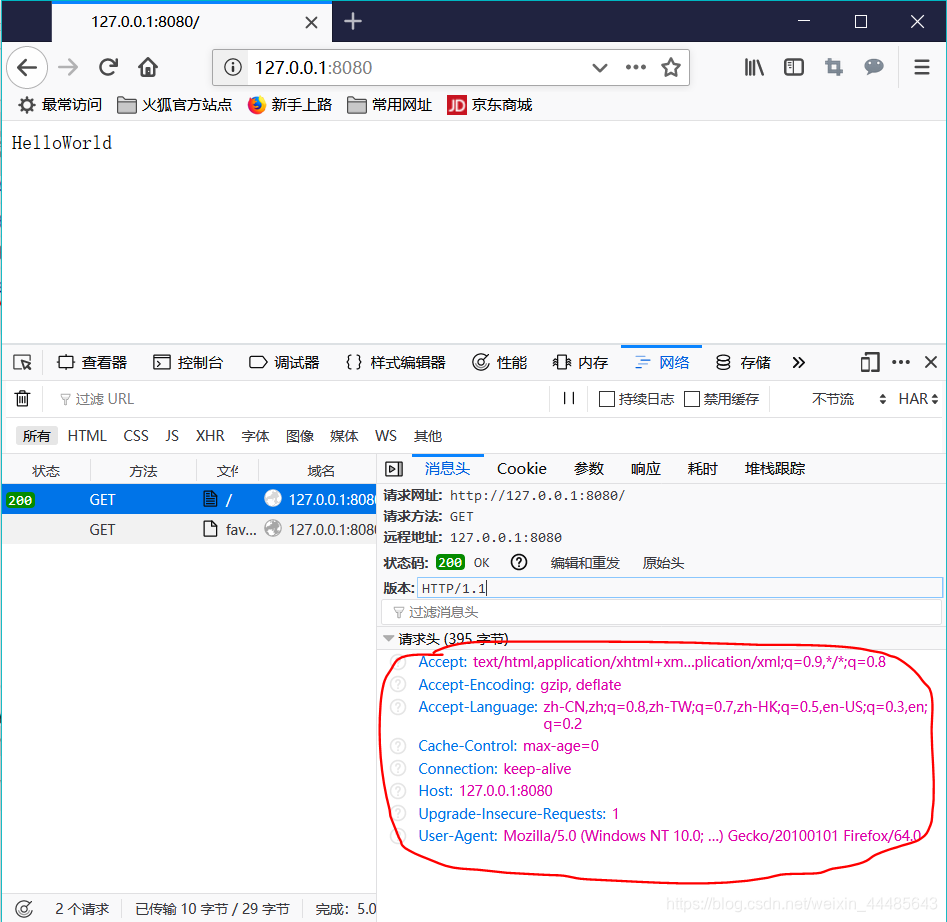
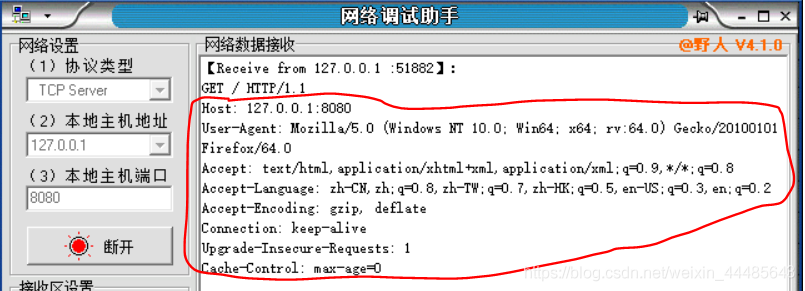
对比上述红色部分不难看出他们是相同的,而在网络调试助手中的第一句 GET / HTTP/1.1在这三部分中 我们也可以在浏览器的调试器中找到类似的。
- 如GET 对应 请求方法:GET,
- ‘/’ 对应状态代码中最后的 ‘/’ ,以及请求url中最后的‘/’。/ 在这里代表的是访问html在服务器中的路径
- 最后的HTTP/1.1则是HTTP的版本号,比如现在我们使用的就是第1.1个版本
在http协议的请求中: 请求方法 路径 版本号 是构成协议的最基本的,最简单的 也是必须要有的三部分
观察网络调试助手中收到的信息,除了 GET / HTTP/1.1 之外还有一堆东西是怎么来的呢有什么用呢?
其实,剩下的这部分是浏览器根据自身的情况自动生成的,如:
- User-Agent:xxxxxxxxxxxx 这代表访问当前页面使用的浏览器是哪个,以及此浏览器的内核信息等。
- Accept-Language:xxxxxxx 请求头允许客户端声明它可以理解的自然语言,简单说就是浏览器可以识别的语言。
其余的这里就不一一介绍了,但我们可以发现一个规律,就是剩下的这部分都是以 “xxx : xxx” 格式存在的。其实这也是http协议所规定的。
现在我们就可以完整的得出http协议在请求时的格式规定:
- 第一行必须是 请求方法 路径 版本号
- 其余信息皆以 xxx : xxx 的格式 各占一行
二、 http协议响应部分
明白了请求我们接着看看服务器是如何响应浏览器的请求,又是发送了哪些数据给浏览器呢?
之前使用网络调试助手模拟应答时,在发送框内输入了 HTTP/1.1 200 OK 回车 空行后 又输入HelloWorld ,但是浏览器却只显示了HelloWorld,那么HTTP/1.1 200 OK 去哪里了呢,参考之前的请求协议不难得出结论,HTTP/1.1 200 OK 是响应头的一部分,而响应头浏览器是不会显示的,浏览器只会显示正文。
那么接下来我们就来看看响应头格式 以及正文格式:
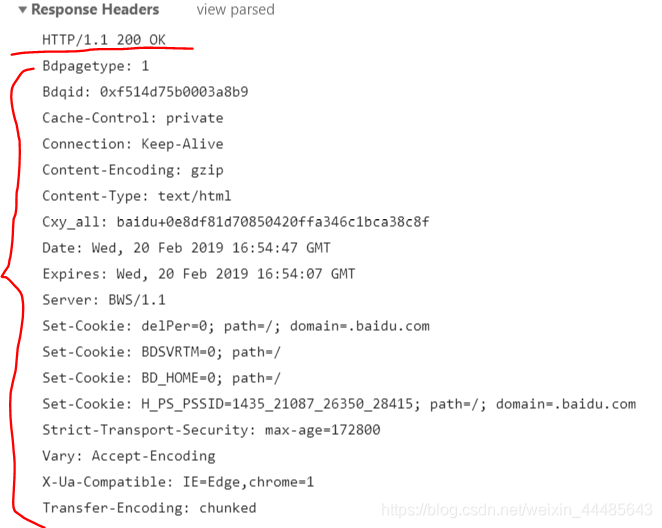
- HTTP/1.1 200 OK 不难看出这也是一个三段式: 这三段分别是 版本号 状态码 状态短语
- 如果还有其余部分控制信息 则以 xxx :xxx 格式各占一行
- 正文与响应头之间要空一行,当浏览器在响应头后发现空行后,则将空行后的内容都当作正文进行显示处理
这里给出访问百度时,百度服务器给我们的响应头部信息
3.用python来实现http协议原理
在python中要想实现网络通讯,都离不开socket(套接字)模块,那么我们就先来认识下socket模块的基本使用 (由于之前也提到过http协议是基于tcp的上层协议,所以此处主要介绍socket的tcp server的使用)
- 导入socket
import socket - 创建socket对象
udp_sock= socket.socket(socket.AF_INET,socket.SOCK_DGRAM) # 创建一个基于udp协议的socket
tcp_sock= socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 创建一个基于tcp协议的socket - 给套接字绑定ip以及端口
localaddr = ('',8080) # ip与端口以元组的形式存在,如果绑定的ip是本地ip则可以用 '' 来代替
tcp_sock.bind(localaddr) # 绑定信息,参数为一个元组 - 设置套接字为监听状态
tcp_sock.listen(128) # 参数128 代表可建立socket连接的最大个数 windows,mac 此连接参数有效 Linux 此连接参数无效,默认最大 所以这就是很多http服务器需用linux系统的原因~ - 设置套接字阻塞,等待客户端连接
new_client,client_addr = tcp_sock.accept() # accept()方法返回值为一个列表,利用python中的拆包机制,我们可以将此列表中的元素取出,第一个为新连接客户端的socet,第二个为此客户端的ip以及端口等信息 - 接收数据
recv_data = new_client.recv(1024) # 从新连接的客户端socket那儿接收客户端(浏览器发送来的数据)
以上就是一些基本使用方法,还有一些我们在代码中在详细介绍
下面来详细介绍下tcp socket为客户端服务的过程,首先我们来看一张图片
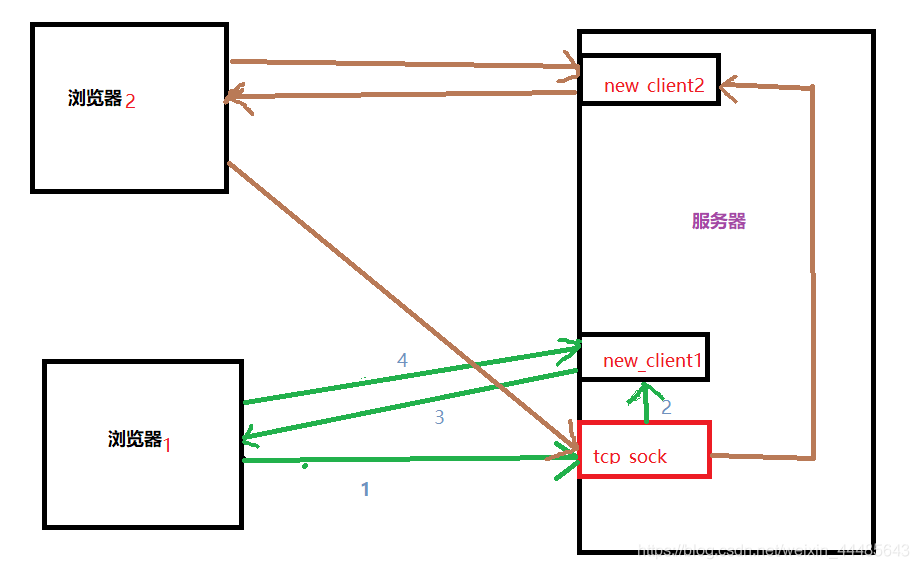
当我们在服务器上创建一个tcp型套接字并且绑定IP及端口等信息并且设置为监听模式,设置阻塞后 ,tcp_sock 就处于等待客户端连接的状态。这时,若有浏览器 向服务器发出请求,这个请求将被tcp_sock 接受到,接受到后,并不是tcp_sock这个端口负责与浏览器通讯,而是操作系统将重新创建一个socket并且分配一个随机的空闲端口负责与浏览器经行数据的收发。例如如图中浏览器1向服务器发送消息,此时tcp_sock接受到后会交给new_client1负责处理,而new_client1则会向浏览器1响应之前浏览器发向tcp_sock的请求,由此,一条新的通讯链路便在服务器与浏览器之间建立起来。
这个过程就向我们平时打电话给10086人工客服一样,首先,你拨通的号码是10086,但10086并不负责与你交流,而是根据你输入的数字随机分配一名客服与你交流一样。
4.代码实现
import socket
import re
def service(new_client):
'''为新连接的客户端提供服务'''
# 1.接受客户端的请求
request = new_client.recv(1024).decode('utf8')
request_lines = request.splitlines()
print()
print('-'*20)
print(request)
print('-'*20)
print()
# 2.判断出客户端访问的页面
pat = '.* (/.*) '
res = re.match(pat,request_lines[0])
if res:
path = res.group(1)
else:
path = 'notfount.html'
# 3.读取客户端请求的数据
if path == '/':
path = '/index.html'
try:
f = open('./staic'+path,'rb')
except Exception:
html_content = 'HTTP/1.1 404 NOT FOUND\r\n'
html_content += '\r\n'
html_body = '404 NOT FOUND'
else:
html_content = 'HTTP/1.1 200 OK\r\n'
html_content += '\r\n'
html_body = f.read()
f.close()
# 4.发送数据给客户端
new_client.send(html_content.encode('utf8'))
new_client.send(html_body)
# 5.关闭t客户端套接字
new_client.close()
def main():
'''http 服务器j控制流程'''
print('————————start working————————')
print()
# 1.创建套接字
tcp_socket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 当服务器先调用close()时,可以保证在 c四次挥手后立刻释放资源,这样就h可以保证下次运行时,端口等资源不会被占用
tcp_socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
# 2.绑定本地信息
localaddr = ('',8080)
tcp_socket.bind(localaddr)
# 3.设置为监听状态
tcp_socket.listen(128)
while True:
# 4.将套接字阻塞,等待链接
new_client,client_addr = tcp_socket.accept()
# 5.为客户端服务
service(new_client)
# 6.关闭套接字
tcp_socket.close()
if __name__ == '__main__':
main()
5.代码运行 及 注意事项
一、 注意事项
1.代码必须和一个名为static的文件夹在同一目录下
2.static文件夹中存放要访问的html css js jpg等静态文件
3.主页index.html必须要存在
(以上要求可以修改代码中的路径而自定义)
一、 运行程序
1.在当前路径下执行程序
2.打开浏览器在地址栏输入127.0.0.1:8080 后回车
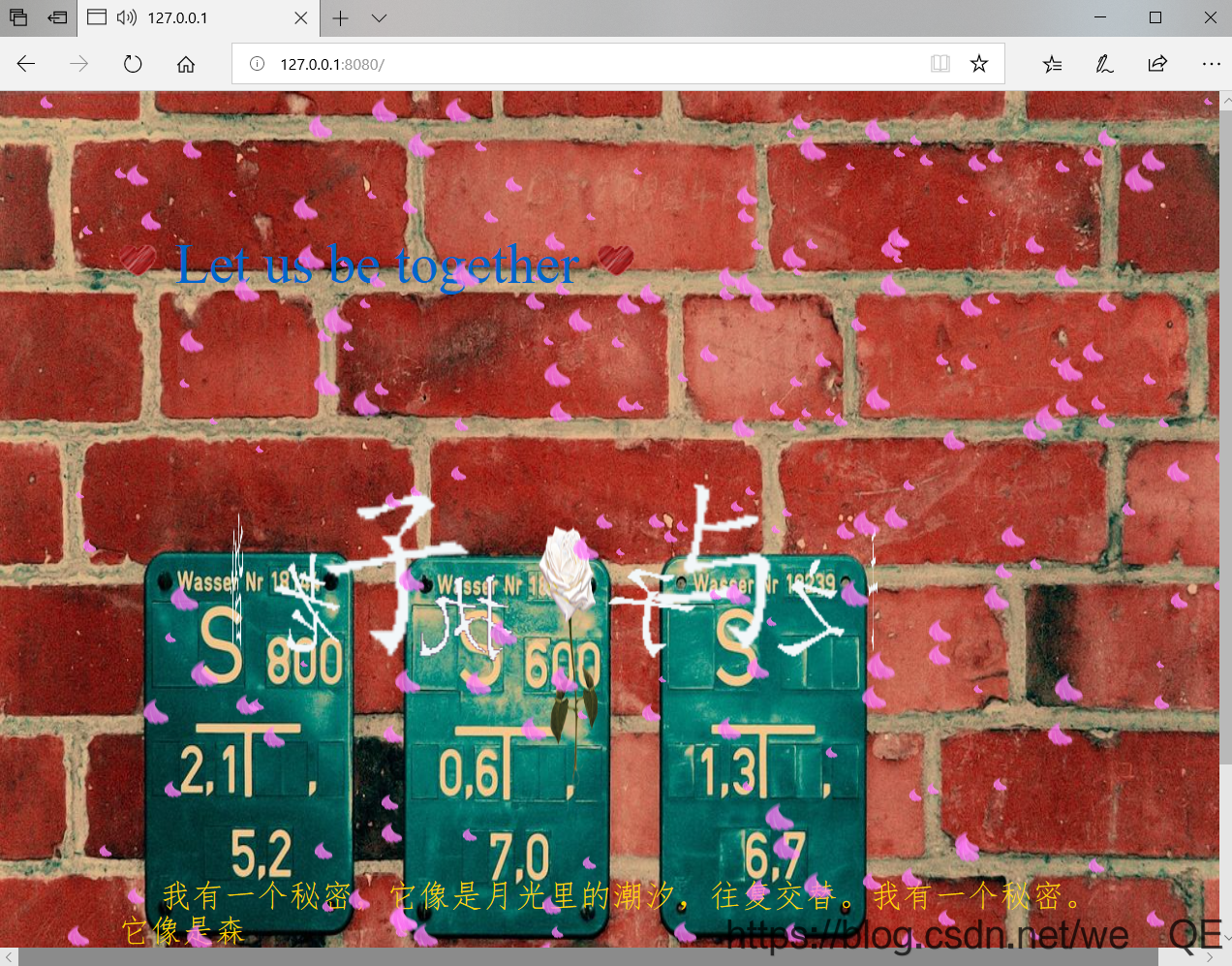
3.观察命令窗口运行的结果
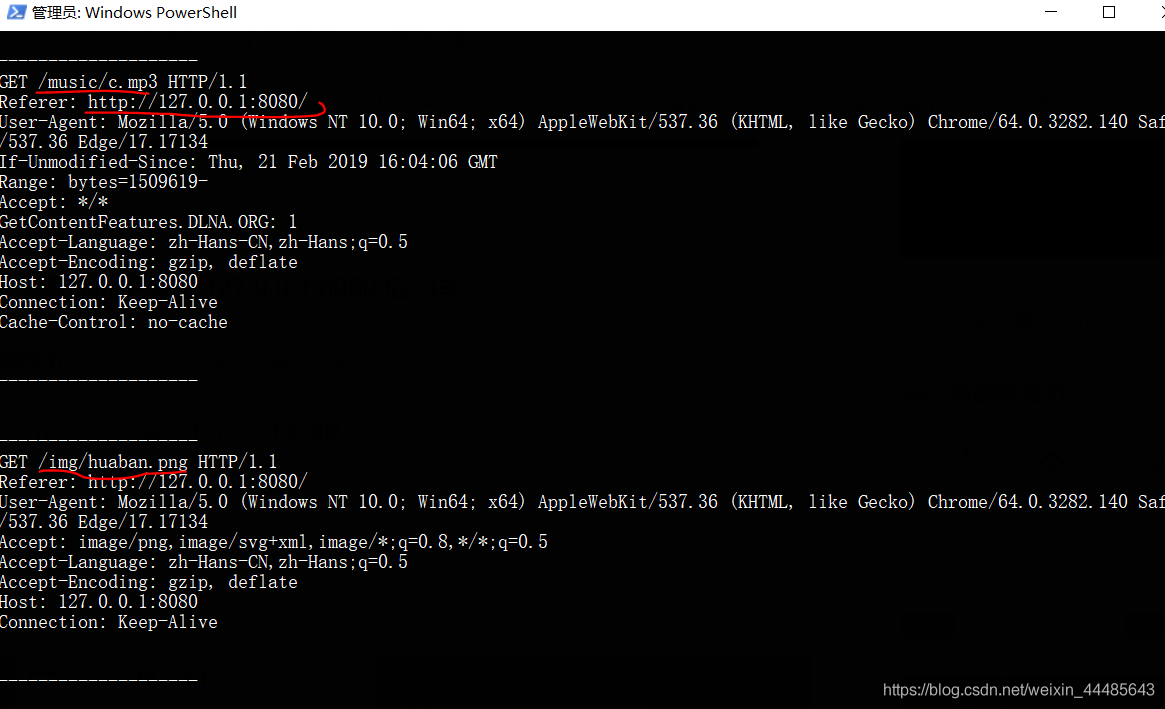
可见浏览器向服务器发送的最后两条请求时音乐和图片
6.结语
至此我们已经实现了一个简单的单任务静态的web服务器,可以用它来运行一些小项目。但是这并不完美,很显然 单任务 时一种效率低下的方式,服务器同一时间只能为一个客户端进行服务。那么如何实现并发,并行执行呢,请期待下篇博客。谢谢浏览,如有不足之处请及时指出。















 4950
4950











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









