






文章目录
前言
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,一个能够对大量数据进行分布式处理的软件框架。Hadoop主要分为三大模块,分别是分布式存储的HDFS、分布式计算的MapReduce以及用于作业调度和集群资源管理的Yarn。
一、HDFS
1.HDFS是什么
分布式的文件系统
2.为什么这么设计HDFS
- 避免硬件错误
- 每个机器只存储文件的部分数据,blocksize=128M
- block存放在不同的机器上的,由于容错,HDFS默认采用3副本机制
- 流式数据处理
- 来了一点数据,就立马处理掉,立马分发到各个存储节点
- 大规模数据集
- 移动计算比移动数据更划算
3.HDFS架构

- HDFS架构采用NameNode(master)/DataNodes(slave)架构
- NameNode相当于元数据记录,相当于文件目录,记录文件存放的位置,状态,包括几个块,存放在哪些DataNodes中
4.HDFS副本相关

如图,part-0副本系数为2,分别是1和3,他们分别在两个节点里面
- 副本存放
- 通过一个机架感知的过程,Namenode可以确定每个Datanode所属的机架id。
- 存放情况
-
在大多数情况下,副本系数是3,HDFS的存放策略是将一个副本存放在本地机架的节点上,一个副本放在同一机架的另一个节点上,最后一个副本放在不同机架的节点上。
-
副本摆放策略
- 1-本rack的一个节点上
- 2-另外一个rack的节点上
- 3-与2相同的rack的另外一个节点上
-
其他策略(版本不同,策略可能也不相同):
- 1-本rack的一个节点上
- 2-本rack的另外一个节点上
- 3-不同rack的一个节点上
-
5.HDFS读写数据流程
- 读数据过程

- 写数据过程

6.HDFS-checkpoint

- NN中的元数据定期写入到fsimage中
- 每当元数据有更新或者添加元数据时,修改内存中的元数据操作并追加到edits.log中。这样,一旦namenode节点断电,可以通过fsImage和edits.log的合并,合成元数据
- 如果长时间添加数据到edit.log中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行fsImage和edits.log的合并。
如果这个操作有namenode节点完成,又会效率过低。因此,引入一个新的节点secondaryNamenode,专门用于fsImage和edits.log的合并
7.HDFS-SaveMode
- Namenode启动后会进入一个称为安全模式的特殊状态。
- 处于安全模式的Namenode是不会进行数据块的复制的。
- Namenode从所有的 Datanode接收心跳信号和块状态报告。
- 块状态报告包括了某个Datanode所有的数据块列表。每个数据块都有一个指定的最小副本数。当Namenode检测确认某个数据块的副本数目达到这个最小值,那么该数据块就会被认为是副本安全(safely replicated)的;在一定百分比(这个参数可配置)的数据块被Namenode检测确认是安全之后(加上一个额外的30秒等待时间),Namenode将退出安全模式状态。接下来它会确定还有哪些数据块的副本没有达到指定数目,并将这些数据块复制到其他Datanode上。
8.HDFS-HA
-
在典型的HA集群中,两台独立机器被配置为NameNode。一个处于Active状态一个处于Standby状态。
 HA没有了secondaryNameNode,使用了备master替代了它的工作,合并成新的fsimage会直接给到主master让其更新
HA没有了secondaryNameNode,使用了备master替代了它的工作,合并成新的fsimage会直接给到主master让其更新 -
组件介绍
ZKFC[进程]包括以下线程
| 名称 | 功能 |
|---|---|
| ZKFailoverController | 基于Zookeeper的故障转移控制器,负责NameNode的主备切换,监控NameNode的健康状态,当发现Active NameNode出现异常会通过Zookeeper进行一次新的选举,完成主备切换 |
| HealthMonitor | 周期性调用NameNode的HAServiceProtocol RPC接口(monitorHealth和getServiceStatus),监控NameNode的健康状态并向ZKFailoverController反馈 |
| ActiveStandbyElector | 接收ZKFC的选举请求,通过Zookeeper自动完成主备选举,选举完成后回调ZKFailoverController的主备切换方法对NameNode进行Active和Standby状态的切换 |
- HA节点配置
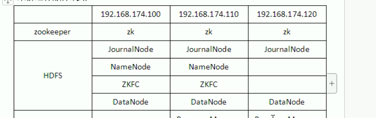
ZKFC一定是和NN绑定在一起的
二、MapReduce
1.MapReduce是什么
- 分布式计算。假设有300M统计文件中的单词出现次数,正常程序就可以;但是有T级别的统计文件则不能这样处理,所以使用分布式计算方式。
- 我们要数图书馆的书,你数1号书架,我数2号书架。这就是"Map"。我们人越多,数书就越快。
现在我们到一起,把所有人的统计数加在一起。这就是"Reduce"。
2.MapReduce编程模型
1.简单理解

- 图中,Input的每行数据在生产当中对应一个文件
- shuffle是将map中相同规则的数据放在一起
- reduce整合数据
2.两个节点进行分布式计算的过程

- InputFormat读取数据
- Split数据切片
- 通过RR[RecordReader]将数据读取进来
- 读进来的数据交给Mapper处理,输出临时结果
- 临时结果交给Partioner进行Shuffle
- Reduce处理
- 通过OutputFormat结果输出
3.设计构思

3.MapReduce代码过程
MapReduce的开发一共有八个步骤,其中Map阶段分为2个步骤,Shuffle4个,Reduce2个。
- ===== Map阶段
- 设置InputFormat类,将数据切分为Key-Value(K1和V1)对,输入到第二步
- 自定义Map逻辑,将第一步的结果转换成另外的Key-Value(K2和V2)对输出结果
- ===== Shuffle阶段
- 对输出的K-V对进行分区
- 对不同分区的数据按照相同的Key排序
- (可选)对分组过的数据初步规约,降低数据的网络拷贝
- 对数据进行分组,相同Key的Value放入一个集合中
- ===== Reduce阶段
- 对多个Map任务的结果进行排序以及合并,编写Reduce函数实现自己的逻辑,对输入的K-V进行处理,转为新的K-V输出
- 设置OutputFormat处理并保存Reduce输出的K-V数据
三、Yarn
1.Yarn是什么
通用的资源管理系统
2.三个主要组件
master -> ResourceManager(RM)
slave -> NodeManager(NM)s
job scheduling/monitoring -> per-application ApplicationMaster (AM)
3.执行流程

- client提交一个应用程序给RM
- RM与NM通信,要求在此NM处启动一个container来运行我们作业的AM
- 启动AM
- AM启动之后要注册到RM上面来申请资源,可以实现client查询AM的情况,如果申请成功,那么返回给AM,此时的RM会告知AM有足够空间使用的NM列表
- AM去NM启动container
- container里面启动task[比如说对于MapReduce来说会产生一个MapTask和ReduceTask两个Container]
4.高可用

- 对于Yarn-HA来说,ZKFC是线程,只作为RM进程的一个线程而非独立的进程存在。
- RMStateStore(共享存储)
- 存储在zk的/rmstore目录下,相当于一个文件夹
- activeRM会向这个目录写job的信息
- 当activeRM挂了,另外一个standby RM通过ZKFC选举成功为active,会从/rmstore读取相应的作业job的信息,去保证高可靠。重新构建作业的内存信息,启动内部的服务,开始接收NM的心跳,构建集群的资源信息,并且接收客户端的作业提交请求。
- RM
- 当RM进程启动的时候会向ZK的/rmstore目录写lock文件,写成功就为active,否则standby。rm节点zkfc会一直监控这个lock文件是否存在,假如不存在,就为active,否则为standby.
- RM接收client的请求,接收和监控NM的资源状况的汇报,负责资源的分配和调度。(client通过namespace找rm,如果发现它是standby状态,那么就去用另一个rm)。NM会向active的RM汇报,但是不会向standby的RM汇报。
- 启动和监控ApplicationMaster (它是跑在NM节点的container上面,是作业job的主程序)。
- NM
- 节点资源的管理、启动容器运行task计算 、上报资源、汇报进度。















 1981
1981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









