







前言
不管是何种情况,对于数据的去从而言,无非就是获取数据、分析处理数据、存储数据三部分。
Flink作为数据的分析处理引擎应运而生。
一、Flink是什么?
Apache Flink 是一个在无界和有界数据流上进行状态计算的框架和分布式处理引擎。1
关键词:数据流、状态、分布式
二、Flink的优势是什么?
1.高吞吐、低延迟、高性能
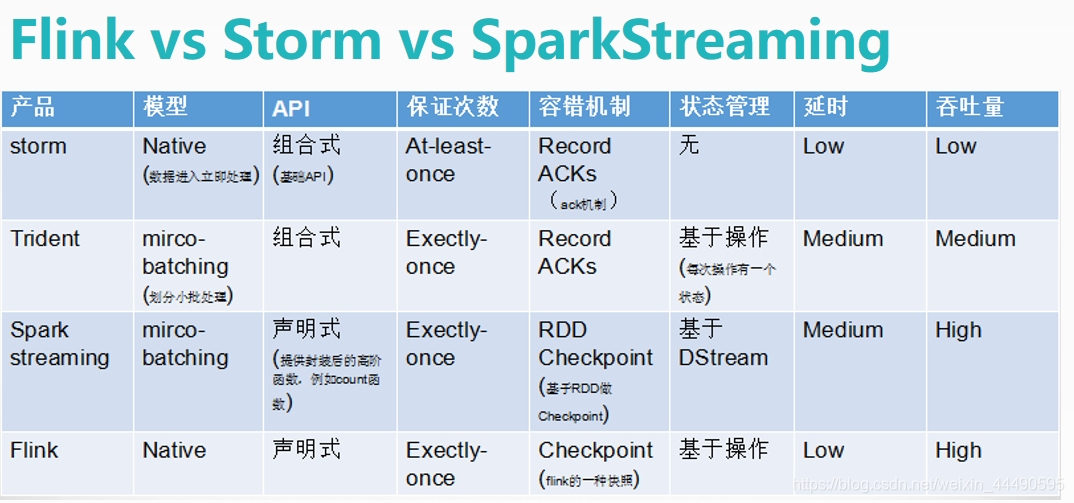
2.支持事件时间概念
Flink能够支持基于数据产生的时间进行窗口计算。
3.支持有状态计算
所谓的状态就是流式计算过程中将算子的中间结果数据保存在内存或者是文件系统中,等新数据到来之后可以和之前保存的状态中的数据做进一步处理。
4.支持高度灵活的窗口(Window)操作
在流处理应用中,数据是连续不断的,需要通过窗口的方式对数据进行一定范围的聚合计算,例如统计在过去一分钟内多少用户点击某一网页,在这种情况下,我们必须定义一个窗口,用来收集最近一分钟的数据,并对窗口内的数据进行统计计算。
5.基于轻量级分布式快照(CheckPoint)实现的容错
Flink能够分布式运行在上千个节点上,在执行任务过程中,一但任务出现异常停止,Flink就能够从Checkpoint中进行任务的自动恢复,以确保数据在处理过程中的一致性。
6.基于JVM实现独立的内存管理
针对内存管理,Flink实现了自身管理内存机制,尽可能减少JVM GC对系统的影响,另外,Flink通过序列化/反序列化方法将所有的数据对象转化为二进制在内存中存储,降低GC带来的性能下降或任务异常的风险。
7.Save Point(保存点)
对于7*24小时运行,数据源源不断地接入,在一段时间内应用的终止有可能导致数据丢失或者计算结果不准确,例如进行集群版本的升级、停机运维操作等。Flink通过Save Points技术将任务执行的快照保存在存储介质上,当任务重启的时候可以直接从事先保存的Save Points恢复原有的计算状态,使得任务继续按照停机之前的状态运行,Sava Point技术可以让用户更好的管理和运维。
三、Flink的应用场景
1.事件驱动
采集的数据Events可以不断的放入消息队列,Flink应用会不断ingest(消费)消息队列中的数据,Flink应用内部维护着一段时间的数据(state),隔一段时间会将数据持久化存储(Persistent sstorage),防止Flink应用死掉。Flink应用每接受一条数据,就会处理一条数据,处理之后就会触发(trigger)一个动作(Action),同时也可以将处理结果写入外部消息队列中,其他Flink应用再消费。
典型的事件驱动类应用
异常检测、基于规则的告警
2.数据分析
比如实时展示双十一天猫销售GMV,用户下单数据需要实时写入消息队列,Flink应用源源不断读取数据做实时计算,然后不断的将数据更新至Database或者K-VStore,最后做大屏实时展示。
3.管道式ETL
比如每天凌晨周期性的启动一个Flink ETL Job,读取传统数据库中的数据,然后做ETL,最后写入数据库和文件系统。
四、Flink的内部分析
1.Flink架构
Flink集群剖析
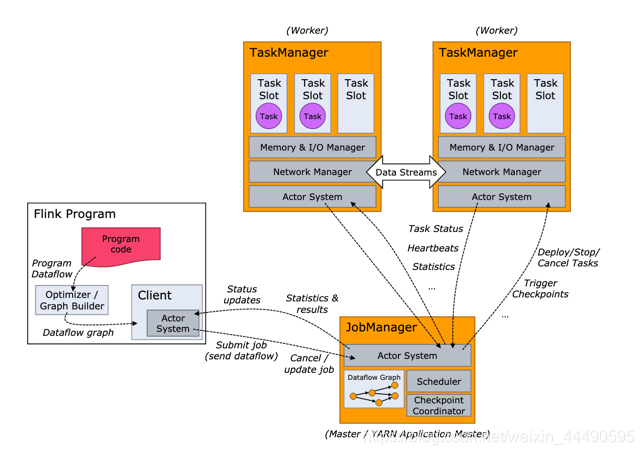
- Flink集群始终由JobManager和一个或多个Flink TaskManager组成。
- JobManager负责处理作业提交,作业的监督以及资源管理。 在HA模式下可以有多个。
- Flink TaskManager运行工作进程,负责执行构成Flink作业的实际任务,这些任务共同组成了一个Flink Job。
- Client 不是运行时和程序执行的一部分,而是用于准备数据流并将其发送给 JobManager。
JobManager三个组件
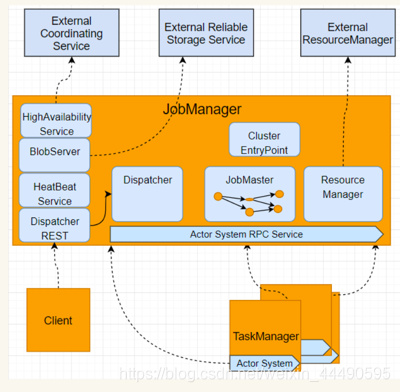
- ResourceManager
负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的单位 - Dispatcher
提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。 - JobMaster
JobMaster 负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
Tasks和算子链

Flink会在生成JobGraph阶段,将代码中可以优化的算子优化成一个算子链(Operator Chains)以放到一个task(一个线程)中执行。
Task(任务):Task 是一个阶段多个功能相同 subTask 的集合
subTask(子任务):subTask 是 Flink 中任务最小执行单元,是一个 Java 类的实例,这个 Java 类中有属性和方法,完成具体的计算逻辑
图中,source、map、[keyBy|window|apply]、sink算子的并行度分别是2、2、2、2、1,经过Flink优化后,source和map算子组成一个算子链,作为一个task运行在一个线程上,其简图如图中condensed view所示,并行图如parallelized view所示。图中一共有 3个 Task,5个 subTask。(红框代表Task,黑框代表subTask)。
Task Slots 和资源
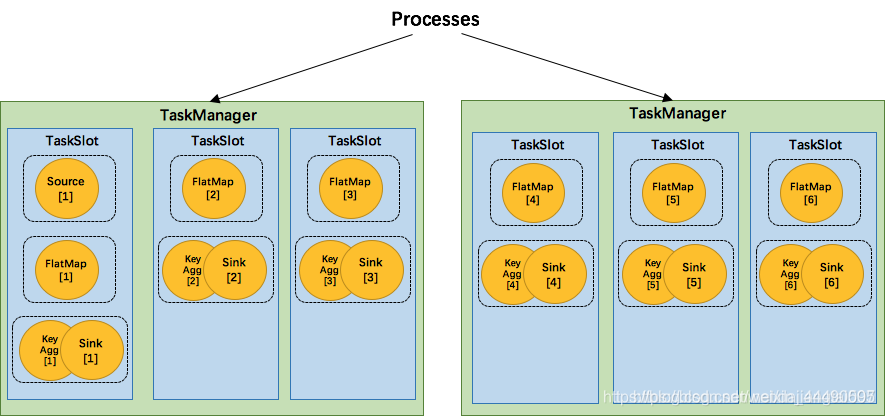
- Flink 中每一个 TaskManager 都是一个JVM进程,它可能会在独立的线程上执行一个或多个 subtask;
- 每个task slot表示TaskManager拥有资源的一个固定大小的子集。假如一个TaskManager有三个slot,那么它会将其管理的内存分成三份给各个slot(注:这里不会涉及CPU的隔离,slot仅仅用来隔离task的受管理内存);
- 默认情况下,Flink 允许subtasks共享slot,条件是它们都来自同一个Job的不同task的subtask。结果可能一个slot持有该job的整个pipeline。[相同的task分开];
- 每个slot里面可以有多个线程。
总结
通俗理解一下:
| Key | Value |
|---|---|
| JobManager | 承包商 |
| TaskManager | 包工头 |
| TaskManager Slots | 包工头能接多少活[可以分配多少工人工作] |
| Job | 一个工程项目 |
| Task&SubTask | 这个工程项目会有多少活 |
| Operator | 工人具体做的事情,也就是完成工程的活[Task&SubTask],比如搬砖/霍水泥/刮大白 |
| Parallelism | 许多工人做同一个活[Task&SubTask/Operator] |
| Chain | 包工头不想让一个工人先搬砖,搬到指定地点,然后从指定地点拿砖砌墙;他希望这个工人可以一气呵成,于是就是工人直接搬砖去砌墙 |
| SlotSharingGroup | 有一个operator任务比较重,所以包工头想把这个operator给一个工人来做,于是就给他分组,其他人的是一个组,都叫"default",这个工人只负责这件事情,其他工人不插手这件事情;也可以给多个工人分成一个组让他们做许多operator,组外成员不插手他们的事情 |
| CoLocationGroup | 包工头强制让一个工人负责多个工作,除了搬砖,霍水泥,刮大白,又给他加了一个砌墙的活 |
还是这张图:
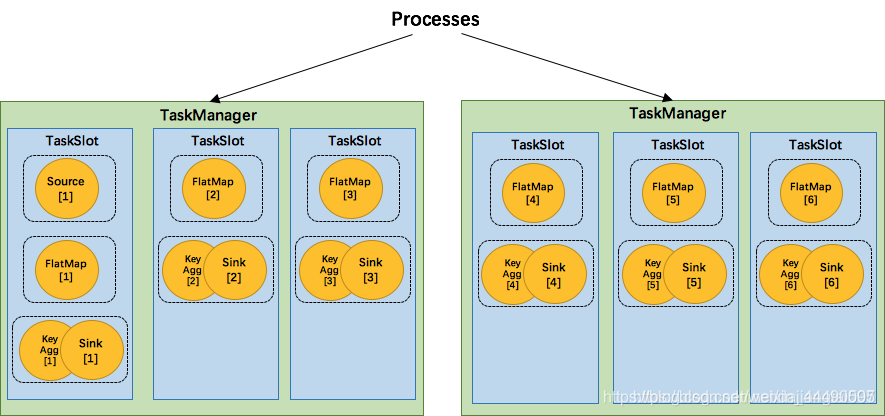
一个项目[job]给了csdn[JobManager],csdn先整理这个项目都有什么活[task&subtask],告诉马小疼、雷小君[TaskManager/进程],这俩人商量了一下开始同时做这个项目并且安排人,他们需要先确定自己手头有几个人[TaskManager Slots],比如马小疼手下有张三、李四、王五,雷小君手下有甲、乙、丙,一共6个人,张三根据任务安排,他要搬砖,霍水泥,砌墙,李四根据任务安排有霍水泥和砌墙[Task&Subtask],由图可以看到,大家在霍水泥这个事情上都在做[6个Paralism],他们还做了一件事情,砌墙这个事情原本是分两个步骤的[1.拿水泥2.在砖上涂抹],每个步骤都是一个operator,他们被马小疼他们chain了这个行为,要求一气呵成。对于张三[slot]自己来说,这些活是衔接的[数据共享,内存共享],所以他做这三件事情很有效率,其他人也在自己的工作范围也很有效率;只是张三有一个搬砖的活,大家都没有,他就需要协调其他人了,他要搬砖给李四,因为他们是一个组的,但是属于两个人,所以相比较自己来说数据有所减缓;他还要搬砖给甲,由于他们不是一个组的,所以数据会更有所减缓。
2.水印
watermark的概念
- 是一种衡量Event time进展的机制
- Watermark(t) 表示事件流的时间已经到达了 t,表示该流中不会再包含时间<t的元素
watermark作用
用于处理乱序事件
生成watermark的方式
- With Punctuated Watermarks
特定事件由用户指定,当在流处理中遇到一条特殊标记则产生watermark - With Periodic Watermarks[常用]
- 自定义周期性 Watermark 生成器。
- 源码
class BoundedOutOfOrdernessGenerator extends AssignerWithPeriodicWatermarks[MyEvent] {
val maxOutOfOrderness = 5000L // 3.5 seconds
var currentMaxTimestamp: Long = _
override def extractTimestamp(element: MyEvent, previousElementTimestamp: Long): Long = {
val timestamp = element.getCreationTime()
currentMaxTimestamp = max(timestamp, currentMaxTimestamp)
timestamp
}
override def getCurrentWatermark(): Watermark = {
// return the watermark as current highest timestamp minus the out-of-orderness bound
new Watermark(currentMaxTimestamp - maxOutOfOrderness)
}
}
/**
* This generator generates watermarks that are lagging behind processing time by a fixed amount.
* It assumes that elements arrive in Flink after a bounded delay.
*/
class TimeLagWatermarkGenerator extends AssignerWithPeriodicWatermarks[MyEvent] {
val maxTimeLag = 5000L // 5 seconds
override def extractTimestamp(element: MyEvent, previousElementTimestamp: Long): Long = {
element.getCreationTime
}
override def getCurrentWatermark(): Watermark = {
// return the watermark as current time minus the maximum time lag
new Watermark(System.currentTimeMillis() - maxTimeLag)
}
}
代码段中两个类是水印使用的两种方式,一般使用BoundedOutOfOrdernessGenerator,依托于事件的属性,也就是从事件中提取得到数据时间,但是由于数据乱序,需要设置允许延迟时间,例如事件时间是10,允许延迟时间是2,那么此时得到的watermark值就是8,如图:
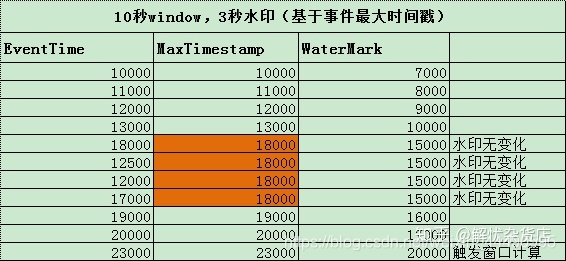
- 案例代码片段
package imooc.course11;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import org.omg.CORBA.Any;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.annotation.Nullable;
import java.text.SimpleDateFormat;
import java.util.*;
public class LogAnalysis {
//Logger logAnalysis = LoggerFactory.getLogger("LogAnalysis");
public static void main(String[] args) throws Exception {
Logger logAnalysis = LoggerFactory.getLogger("LogAnalysis");
// 获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
String topic = "pktest";
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","guanyudeMBP:9092");
properties.setProperty("group.id", "test-pk-group");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>(topic,new SimpleStringSchema(),properties);
//接收kafka数据
DataStreamSource<String> data = env.addSource(consumer);
// transformation
SingleOutputStreamOperator<Tuple4<String, Long, String, String>> logData = data.map(new MapFunction<String, Tuple4<String, Long, String, String>>() {
@Override
public Tuple4<String, Long, String, String> map(String value) throws Exception {
String[] splits = value.split("\t");
String level = splits[2];
String timeStr = splits[3];
Long time = 0L;
try{
SimpleDateFormat sourceFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
time = sourceFormat.parse(timeStr).getTime();
}catch (Exception e){
logAnalysis.error("time parse error: " + timeStr + e.getMessage());
}
String domain = splits[5];
String traffic = splits[6];
return new Tuple4<String, Long, String, String>(level, time, domain, traffic);
}
}).filter(value -> value.f1 != 0).filter(value -> value.f0.equals("E"));
// 1 level(抛弃) 2 time 3 domain 4 traffic
SingleOutputStreamOperator<Tuple3<Long, String, Long>> outputStreamOperator = logData.map(new MapFunction<Tuple4<String, Long, String, String>, Tuple3<Long, String, Long>>() {
@Override
public Tuple3<Long, String, Long> map(Tuple4<String, Long, String, String> value) throws Exception {
return new Tuple3<>(value.f1, value.f2, Long.parseLong(value.f3));
}
});
//水印设置!!!重点在这里,简单的使用方法
SingleOutputStreamOperator<Tuple3<String, String, Long>> tuple3SingleOutputStreamOperator
= outputStreamOperator.assignTimestampsAndWatermarks
(new AssignerWithPeriodicWatermarks<Tuple3<Long, String, Long>>() {
private final long maxOutOfOrderness = 10000; // 3.5 seconds
private long currentMaxTimestamp;
@Override
public Watermark getCurrentWatermark() {
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
@Override
public long extractTimestamp(Tuple3<Long, String, Long> element, long recordTimestamp) {
long timestamp = element.f0;
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);
return timestamp;
}
}).keyBy(1) // 此处是按照域名keyby的
.window(TumblingEventTimeWindows.of(Time.seconds(60)))
.apply(new WindowFunction<Tuple3<Long, String, Long>, Tuple3<String, String, Long>, Tuple, TimeWindow>() {
@Override
public void apply(Tuple key, TimeWindow window, Iterable<Tuple3<Long, String, Long>> input, Collector<Tuple3<String, String, Long>> out) throws Exception {
String domain = key.getField(0).toString();
Long sum = 0L;
Iterator<Tuple3<Long, String, Long>> iterator = input.iterator();
String time = null;
SimpleDateFormat sourceFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
while (iterator.hasNext()) {
Tuple3<Long, String, Long> next = iterator.next();
if (time == null) {
time = sourceFormat.format(next.f0);
}
sum += next.f2; //traffic求和
}
/*
* 第一个参数:这一分钟的时间
第二个参数:域名
第三个参数:traffic的和
*/
out.collect(new Tuple3<>(time, domain, sum));
}
}).setParallelism(1);
// sink-ES
List<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("guanyudeMBP", 9200, "http"));
// use a ElasticsearchSink.Builder to create an ElasticsearchSink
ElasticsearchSink.Builder<Tuple3<String,String,Long>> esSinkBuilder = new ElasticsearchSink.Builder<>(
httpHosts,
new ElasticsearchSinkFunction<Tuple3<String,String,Long>>() {
@Override
public void process(Tuple3<String, String, Long> longStringLongTuple3, RuntimeContext runtimeContext, RequestIndexer requestIndexer) {
requestIndexer.add(createIndexRequest(longStringLongTuple3));
}
public IndexRequest createIndexRequest(Tuple3<String,String,Long> element) {
Map<String, Object> json = new HashMap<>();
json.put("time", element.f0);
json.put("domain", element.f1);
json.put("traffic", element.f2);
String id = element.f0 + "-" + element.f1;
return Requests.indexRequest()
.index("cdn")
.type("traffic")
.id(id)
.source(json);
}
}
);
// configuration for the bulk requests; this instructs the sink to emit after every element, otherwise they would be buffered
esSinkBuilder.setBulkFlushMaxActions(1);
// finally, build and add the sink to the job's pipeline
tuple3SingleOutputStreamOperator.addSink(esSinkBuilder.build());
env.execute("LogAnalysis");
}
}
并行流中的Watermark
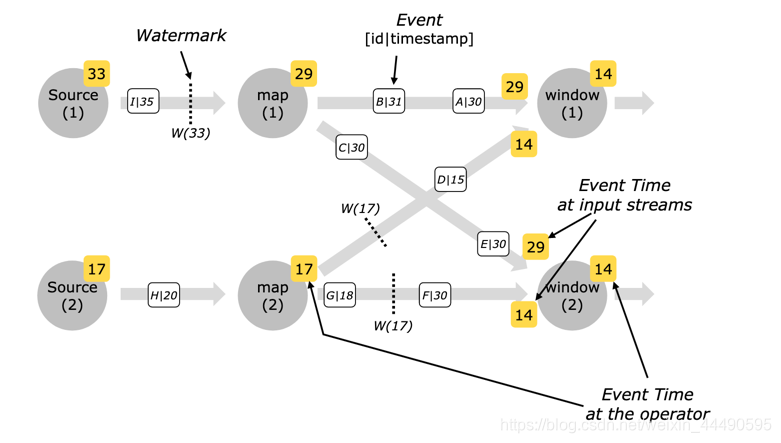 对于并行流中的watermarks,进入窗口的时间也是按照EventTime最小值计算的
对于并行流中的watermarks,进入窗口的时间也是按照EventTime最小值计算的
总结
一家煎饼店很火爆,大家都去吃,但是人太多,厨师顾不过来,所以大家需要排号,过去的人都需要拿到一个号,这个号就是watermark,一个人拿了3号过来,说明前两个人已经吃过走了。
增加延迟:但是为了防止被叫到号的人没有听到,容忍度增加了2,即如果这人是3号,叫到这个人了没来,那么4号过来,4号结束继续叫3号,还没有人,就叫5号,5号结束之后叫3号还没人来,到6号结束之后就不会在叫3号了,3号你再来也没得吃了。
3.状态
什么是状态
一种为了满足算子计算时需要历史数据需求的,使用 checkpoint 机制进行容错,存储在 state backend 的数据结构。
state分类
- 最常见的是 Keyed State,应用于 keyedStream 上,必须在 KeyBy 操作之后使用,特点是同一个 sub task 上的同一个 key 共享一个 state。
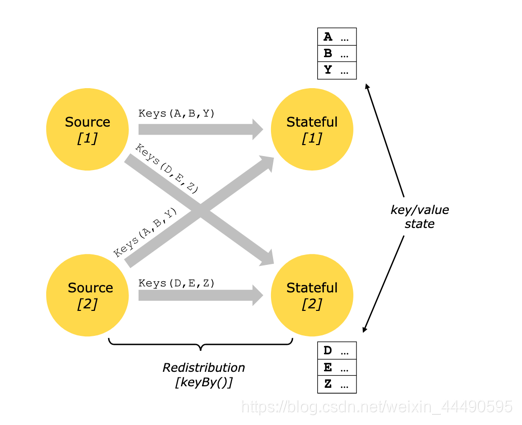
- operator state,顾名思义每一个 operator state 都只与一个 operator 的实例绑定。常见的 operator state 是 source state,例如记录当前 source 的 offset。还有比如window里面存有了一部分数据,程序突然挂了,还原回来能够找到之前的状态,特点是同一个 subtask 共享一个 state。
- 还有一种特殊的 operator state 称为 broadcast state,特点是同一个算子的多个 sub task 共享一个 state。
状态保存在哪里
| Backend | state存储方式 | checkpoint存储方式 | 使用场景 |
|---|---|---|---|
| MemoryStateBackend | TaskManager 内存 | Jobmanager 内存 | 本地测试用,不推荐生产场景使用 |
| FsStatebackend | TaskManager 内存 | 外部文件系统( 本地或 HDFS ) | 常规使用 State 的作业,可以在生产中使用 |
| RocksDBStateBackend | TaskManager 上的 KV 数据库(实际使用内存 + 磁盘) | 外部文件系统(本地或 HDFS ) | 超大状态作业,对性能要求不高的生产场景 |
checkpint负责保存状态
当集群出现故障时进行恢复时,State 的值肯定不会从头开始计算,这就需要进行容错。State 使用 Checkpoint 机制进行容错。简单来说就是定时制作分布式快照,当出现故障需要进行恢复时,将所有 Task 恢复到最近一次成功的 Checkpoint 状态中,然后从那个点开始继续处理。
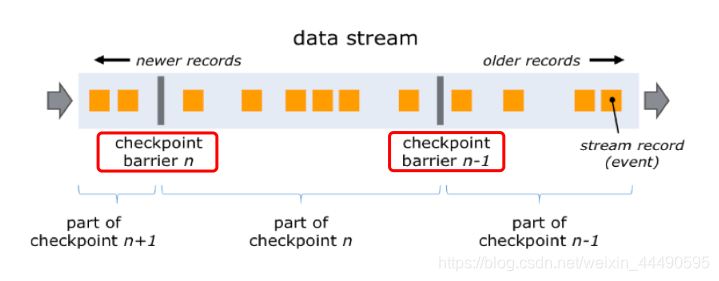
- barrier 从 Source Task 处生成,一直流到 Sink Task,期间所有的 Task 只要碰到barrier,就会触发自身进行快照
- CheckPoint barrier n-1 处做的快照就是指 Job 从开始处理到 barrier n-1所有的状态数据
- 具体细节参见 链接: checkpoint状态存储机制
总结
阅读一本100页的书,checkpoint相当于书签,当你脑袋发懵不想看了,然后下次去看书的时候可以直接通过该书签找到自己看书的页码;
状态则表示你对于前面看到的章节有印象,继续往下看书的时候能够根据前面的内容可以联系到书本内容的后续线索。
五、应用场景实例
1.针对每一个key进行的状态处理
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
/**
* The ValueState handle. The first field is the count, the second field a running sum.
*/
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
// access the state value
Tuple2<Long, Long> currentSum = sum.value();
// update the count
currentSum.f0 += 1;
// add the second field of the input value
currentSum.f1 += input.f1;
// update the state
sum.update(currentSum);
// if the count reaches 2, emit the average and clear the state
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // the state name
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}), // type information
Tuple2.of(0L, 0L)); // default value of the state, if nothing was set
sum = getRuntimeContext().getState(descriptor);
}
}
// this can be used in a streaming program like this (assuming we have a StreamExecutionEnvironment env)
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(value -> value.f0)
.flatMap(new CountWindowAverage())
.print();
// the printed output will be (1,4) and (1,5)
2.POJO作为数据源
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction;
public class Example {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Person> flintstones = env.fromElements(
new Person("Fred", 35),
new Person("Wilma", 35),
new Person("Pebbles", 2));
DataStream<Person> adults = flintstones.filter(new FilterFunction<Person>() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
});
adults.print();
env.execute();
}
public static class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
this.name = name;
this.age = age;
};
public String toString() {
return this.name.toString() + ": age " + this.age.toString();
};
}
}
3.一个流在另一个流中的过滤
package official;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class DoubleStream {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> control = env.fromElements("DROP","IGNORE").keyBy(x->x);
DataStream<String> streamOfWords = env.fromElements("Apache", "DROP", "Flink", "IGNORE").keyBy(x -> x);
control.connect(streamOfWords)
.flatMap(new ControlFunction())
.print();
env.execute();
}
}
4.窗口应用
5.延迟数据处理/旁路输出
6.迭代
package official;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.IterativeStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class IterationStream {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Long> someIntegers = environment.generateSequence(0, 1000);
// 创建迭代流
IterativeStream<Long> iterationStream = someIntegers.iterate();
// 增加处理逻辑,对元素执行减一操作
SingleOutputStreamOperator<Long> minusOne = iterationStream.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
return value - 1;
}
});
// 获取要进行迭代的流
SingleOutputStreamOperator<Long> stillGreaterThanZero = minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return value > 0;
}
});
// 对需要迭代的流形成一个闭环
iterationStream.closeWith(stillGreaterThanZero);
// 小于等于0的数据继续向前传输
SingleOutputStreamOperator<Long> lessThanZero = minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return value <= 0;
}
});
lessThanZero.print();
environment.execute("as");
}
}
7.窗口范围相同的两个窗口根据key进行数据聚合
8.一个数据流需要读取配置流的规则并且下发
package bilibili.userPurchaseBehaviorTracker;
import bilibili.userPurchaseBehaviorTracker.function.ConnectedBroadcastProcessFuntion;
import bilibili.userPurchaseBehaviorTracker.model.Config;
import bilibili.userPurchaseBehaviorTracker.model.EvaluatedResult;
import bilibili.userPurchaseBehaviorTracker.model.UserEvent;
import bilibili.userPurchaseBehaviorTracker.schema.ConfigDeserializationSchema;
import bilibili.userPurchaseBehaviorTracker.schema.EvaluatedResultSerializationSchema;
import bilibili.userPurchaseBehaviorTracker.schema.UserEventDeserializationSchema;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
/**
* @Author: 🐟lifei🐟
* @Date: 2019/1/27 下午8:25
*/
@Slf4j
public class Launcher {
public static final String BOOTSTRAP_SERVERS = "bootstrap.servers";
public static final String GROUP_ID = "group.id";
public static final String RETRIES = "retries";
public static final String INPUT_EVENT_TOPIC = "input-event-topic";
public static final String INPUT_CONFIG_TOPIC = "input-config-topic";
public static final String OUTPUT_TOPIC = "output-topic";
public static final MapStateDescriptor<String, Config> configStateDescriptor =
new MapStateDescriptor<>(
"configBroadcastState",
BasicTypeInfo.STRING_TYPE_INFO,
TypeInformation.of(new TypeHint<Config>() {}));
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Checking input parameters
final ParameterTool params = parameterCheck(args);
env.getConfig().setGlobalJobParameters(params);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
/**
* checkpoint
*/
env.enableCheckpointing(60000L);
CheckpointConfig checkpointConf=env.getCheckpointConfig();
checkpointConf.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
checkpointConf.setMinPauseBetweenCheckpoints(30000L);
checkpointConf.setCheckpointTimeout(10000L);
checkpointConf.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
/**
* StateBackend
*/
// env.setStateBackend(new FsStateBackend(
// "hdfs://namenode01.td.com/flink-checkpoints/customer-purchase-behavior-tracker"));
/**
* restart策略
*/
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
10, // number of restart attempts
org.apache.flink.api.common.time.Time.of(30, TimeUnit.SECONDS) // delay
));
/* Kafka consumer */
Properties consumerProps=new Properties();
consumerProps.setProperty(BOOTSTRAP_SERVERS, params.get(BOOTSTRAP_SERVERS));
consumerProps.setProperty(GROUP_ID, params.get(GROUP_ID));
//事件流
final FlinkKafkaConsumer010 kafkaUserEventSource = new FlinkKafkaConsumer010<UserEvent>(
params.get(INPUT_EVENT_TOPIC),
new UserEventDeserializationSchema(),consumerProps);
// (userEvent, userId)
KeyedStream<UserEvent, String> customerUserEventStream = env
.addSource(kafkaUserEventSource)
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor(Time.hours(24)))
.keyBy(new KeySelector<UserEvent, String>() {
@Override
public String getKey(UserEvent userEvent) throws Exception {
return userEvent.getUserId();
}
});
//customerUserEventStream.print();
//配置流
final FlinkKafkaConsumer010 kafkaConfigEventSource = new FlinkKafkaConsumer010<Config>(
params.get(INPUT_CONFIG_TOPIC),
new ConfigDeserializationSchema(), consumerProps);
final BroadcastStream<Config> configBroadcastStream = env
.addSource(kafkaConfigEventSource)
.broadcast(configStateDescriptor);
//连接两个流
/* Kafka consumer */
Properties producerProps=new Properties();
producerProps.setProperty(BOOTSTRAP_SERVERS, params.get(BOOTSTRAP_SERVERS));
producerProps.setProperty(RETRIES, "3");
final FlinkKafkaProducer010 kafkaProducer = new FlinkKafkaProducer010<EvaluatedResult>(
params.get(OUTPUT_TOPIC),
new EvaluatedResultSerializationSchema(),
producerProps);
/* at_ least_once 设置 */
kafkaProducer.setLogFailuresOnly(false);
kafkaProducer.setFlushOnCheckpoint(true);
DataStream<EvaluatedResult> connectedStream = customerUserEventStream
.connect(configBroadcastStream)
.process(new ConnectedBroadcastProcessFuntion());
connectedStream.addSink(kafkaProducer);
env.execute("UserPurchaseBehaviorTracker");
}
/**
* 参数校验
* @param args
* @return
*/
public static ParameterTool parameterCheck(String[] args){
//--bootstrap.servers slave03:9092 --group.id test --input-event-topic purchasePathAnalysisInPut --input-config-topic purchasePathAnalysisConf --output-topic purchasePathAnalysisOutPut
ParameterTool params=ParameterTool.fromArgs(args);
params.getProperties().list(System.out);
if(!params.has(BOOTSTRAP_SERVERS)){
System.err.println("----------------parameter[bootstrap.servers] is required----------------");
System.exit(-1);
}
if(!params.has(GROUP_ID)){
System.err.println("----------------parameter[group.id] is required----------------");
System.exit(-1);
}
if(!params.has(INPUT_EVENT_TOPIC)){
System.err.println("----------------parameter[input-event-topic] is required----------------");
System.exit(-1);
}
if(!params.has(INPUT_CONFIG_TOPIC)){
System.err.println("----------------parameter[input-config-topic] is required----------------");
System.exit(-1);
}
if(!params.has(OUTPUT_TOPIC)){
System.err.println("----------------parameter[output-topic] is required----------------");
System.exit(-1);
}
return params;
}
private static class CustomWatermarkExtractor extends BoundedOutOfOrdernessTimestampExtractor<UserEvent> {
public CustomWatermarkExtractor(Time maxOutOfOrderness) {
super(maxOutOfOrderness);
}
@Override
public long extractTimestamp(UserEvent element) {
return element.getEventTime();
}
}
}
六、配置
1.设置缓存
默认情况下,元素不会在网络上一对一传输(这会导致不必要的网络通信),但是会进行缓冲。缓冲区的大小(实际上是在计算机之间传输的)可以在Flink配置文件中设置。尽管此方法可以优化吞吐量,但是当传入流不够快时,它可能会导致延迟问题。要控制吞吐量和延迟,可以在执行环境(或各个运算符)上使用env.setBufferTimeout(timeoutMillis)来设置缓冲区填充的最大等待时间。在此时间之后,即使缓冲区未满,也会自动发送缓冲区。此超时的默认值为100毫秒。
LocalStreamEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
env.setBufferTimeout(timeoutMillis);
env.generateSequence(1,10).map(new MyMapper()).setBufferTimeout(timeoutMillis);
- 为了最大化吞吐量,请设置setBufferTimeout(-1),该设置将删除超时,并且仅在缓冲区已满时才刷新缓冲区。
- 为了使延迟最小化,请将超时设置为接近0的值(例如5或10 ms)。应避免将缓冲区超时设置为0,因为它可能导致严重的性能下降。
2.设置数据时间方式
// EventTime/ProcessTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
3.checkpoint配置
- 开启
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(1000);
- 方式
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
- 超时设置
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(60000);
checkpoint 超时,如果 checkpoint 执行的时间超过了该配置的阈值,还在进行中的 checkpoint 操作就会被抛弃
- 并发数目设置
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
并发 checkpoint 的数目,该选项不能和 “checkpoints 间的最小时间”同时使用
- 最小时间
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
checkpoints 之间的最小时间,注意这个值也意味着并发 checkpoint 的数目是一
- externalized checkpoints
你可以配置周期存储 checkpoint 到外部系统中。Externalized checkpoints 将他们的元数据写到持久化存储上并且在 job 失败的时候不会被自动删除。
// 开启在 job 中止后仍然保留的 externalized checkpoints
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
- ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:当作业取消时,保留作业的 checkpoint。注意,这种情况下,需要手动清除该作业保留的 checkpoint。
- ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:当作业取消时,删除作业的 checkpoint。仅当作业失败时,作业的 checkpoint 才会被保留。
4.参数配置/ParameterTool
- From .properties files
String propertiesFilePath = "/home/sam/flink/myjob.properties";
ParameterTool parameter = ParameterTool.fromPropertiesFile(propertiesFilePath);
File propertiesFile = new File(propertiesFilePath);
ParameterTool parameter = ParameterTool.fromPropertiesFile(propertiesFile);
InputStream propertiesFileInputStream = new FileInputStream(file);
ParameterTool parameter = ParameterTool.fromPropertiesFile(propertiesFileInputStream);
- From the command line arguments
public static void main(String[] args) {
ParameterTool parameter = ParameterTool.fromArgs(args);
// .. regular code ..
//This allows getting arguments like --input hdfs:///mydata --elements 42 from the command line
//这样parameter就存储了{"input":"hdfs:///...","elements":"42"}
- Flink程序中使用参数
ParameterTool parameters = // ...
parameter.getRequired("input");
parameter.get("output", "myDefaultValue");
parameter.getLong("expectedCount", -1L);
parameter.getNumberOfParameters()
// .. there are more methods available.
- 全局注册参数
// 设置
ParameterTool parameters = ParameterTool.fromArgs(args);
// set up the execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(parameters);
//使用
public static final class Tokenizer extends RichFlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
ParameterTool parameters = (ParameterTool)
getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
parameters.getRequired("input");
// .. do more ..
5.故障恢复重启
- none
如果禁用checkpoint,则默认值为none。如果启用了检查点,则默认值为fixed-delay,延迟为“ 1 s”。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
- fixeddelay
固定延时重启策略按照给定的次数尝试重启作业。 如果尝试超过了给定的最大次数,作业将最终失败。 在连续的两次重启尝试之间,重启策略等待一段固定长度的时间。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启的次数
Time.of(10, TimeUnit.SECONDS) // 延时
));
- failurerate
故障率重启策略在故障发生之后重启作业,但是当故障率(每个时间间隔发生故障的次数)超过设定的限制时,作业会最终失败。 在连续的两次重启尝试之间,重启策略等待一段固定长度的时间。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个时间间隔的最大故障次数
Time.of(5, TimeUnit.MINUTES), // 测量故障率的时间间隔
Time.of(10, TimeUnit.SECONDS) // 延时
));
总结
如果不出意外,窗口没有写哎,其实官网还是很香的。















 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









