






XTuner 微调 LLM
1.Xtuner的优势
XTuner 一个大语言模型&多模态模型微调工具箱。主要具有如下两点优势:
- 便捷化: 以 配置文件 的形式封装了大部分微调场景,0基础的非专业人员也能一键开始微调。
- 轻量级: 对于 7B 参数量的LLM,微调所需的最小显存仅为 8G,可以再消费级显卡以及colab上部署。

2.两种微调方式
微调主要有两种方式,一种是增量训练微调可以增加大模型的新知识,另一种是指令跟随微调可以更好的让大模型和人类交互。

3.微调实战
1.基座模型
基座模型是模型微调的基础,微调后的模型可以作为基座模型继续微调,需要大量数据训练。
基座模型壳从HuggingFace下载。
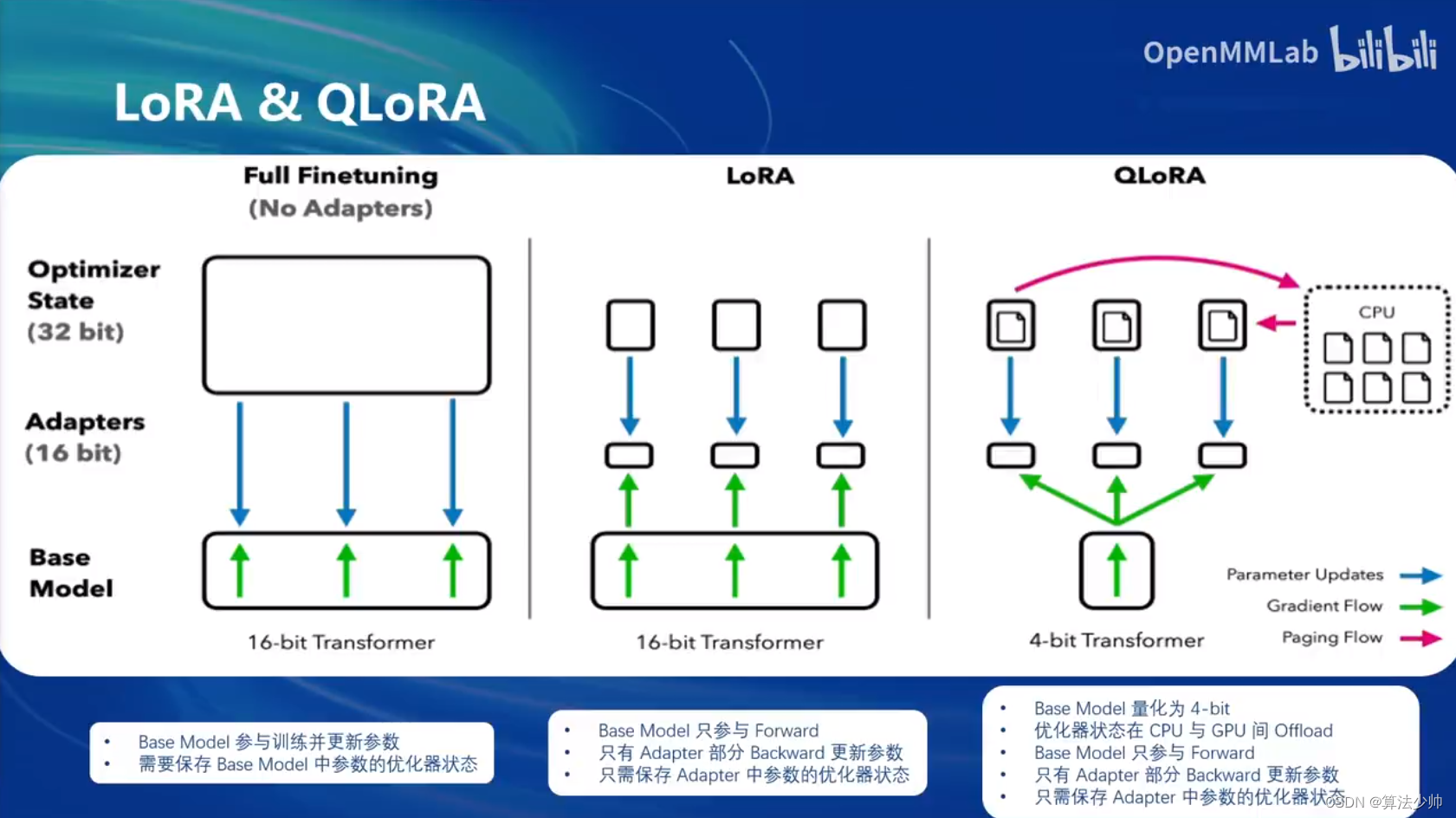
2.LoRA
LoRA 是一种轻量级的微调技术,可以显著降低微调所需显存占用。Xtuner 通过简单命令实现LoRA。
xtuner train ${CONFIG_NAME_OR_PATH}
也可以增加 deepspeed 进行训练加速:
xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2
生成Adaptor文件
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf
2.LoRA与基座模型合并使用
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
# xtuner convert merge \
# ${NAME_OR_PATH_TO_LLM} \
# ${NAME_OR_PATH_TO_ADAPTER} \
# ${SAVE_PATH} \
# --max-shard-size 2GB















 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









