






仅以此来记录自己学习大模型(Large Model) 的过程
什么是大模型
大模型是指具有大规模参数和复杂计算结构的机器学习模型。设计之初是为了能够提高模型的表达能力和预测性能,处理更加复杂的任务和数据。通过对大模型的训练使其能够学习复杂的模式和特征,具有更强的泛化能力,可以对未见过的数据做出准确的预测。
大模型的特点
- 大规模参数:大模型之所以有很强的表达能力和预测性能,主要还是因为其有着规模庞大的参数
- 自监督学习:大模型能够通过自监督学习在大规模未标记数据上进行训练。
- 迁移学习:大模型可以将某一领域的思考模式,快速迁移到其他领域,提高自主学习的能力。
- 强大的计算资源
大模型发展成发展通用人工智能的途径
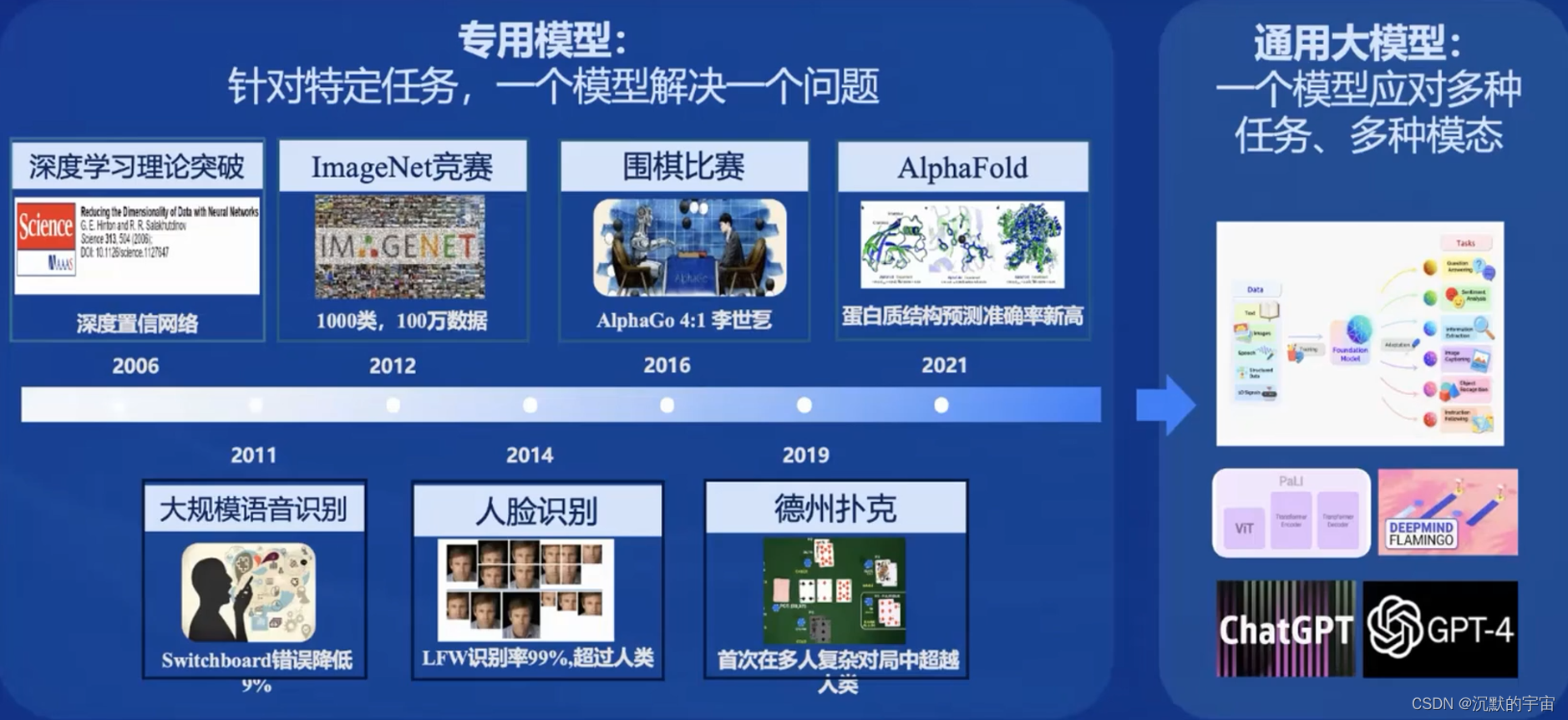
书生·浦语大模型介绍
书生·浦语官网: 书生·浦语官网
书生·浦语是由上海AI实验室、商汤科技联合香港中文大学、复旦大学及上海交通大学发布的千亿级参数大语言模型(InternLM)
开源历程
- 2023.6.7 InternLM 千亿参数语言大模型发布
- 2023.7.6 InternLM 千亿参数语言大模型全面开源,免费商用:InternLM-7B 模型、全链条开源工具体系
- 2023.8.14 书生·万卷 1.0 多模态预训练语料库开源发布
- 2023.8.21 InternLM-Chat-7B v1.1 发布 开源智能体框架 Lagent
- 2023.8.28 InternLM 参数升级至123B
- 2023.9.20 InternLM-20B 开源工具链全线升级
- 2024.1.17 InternLM 2 开源
InternLM2 体系
-
规格
- 7B:为轻量级的研究和应用提供轻便但性能不俗的模型
- 20B:综合性能强劲,有效支撑更加复杂的使用场景
-
模型版本
- InternLM2-Base: 高质量和具有很强可塑性的模型基座,是模型进行深度领域适配的高质量起点
- InternLM2:在Base基础上,多个能力方向进行强化。
- InternLM2-Chat:具有很好的指令遵循,共情聊天和调用工具等能力
InternLM2 亮点

性能方面:

从模型->应用的流程
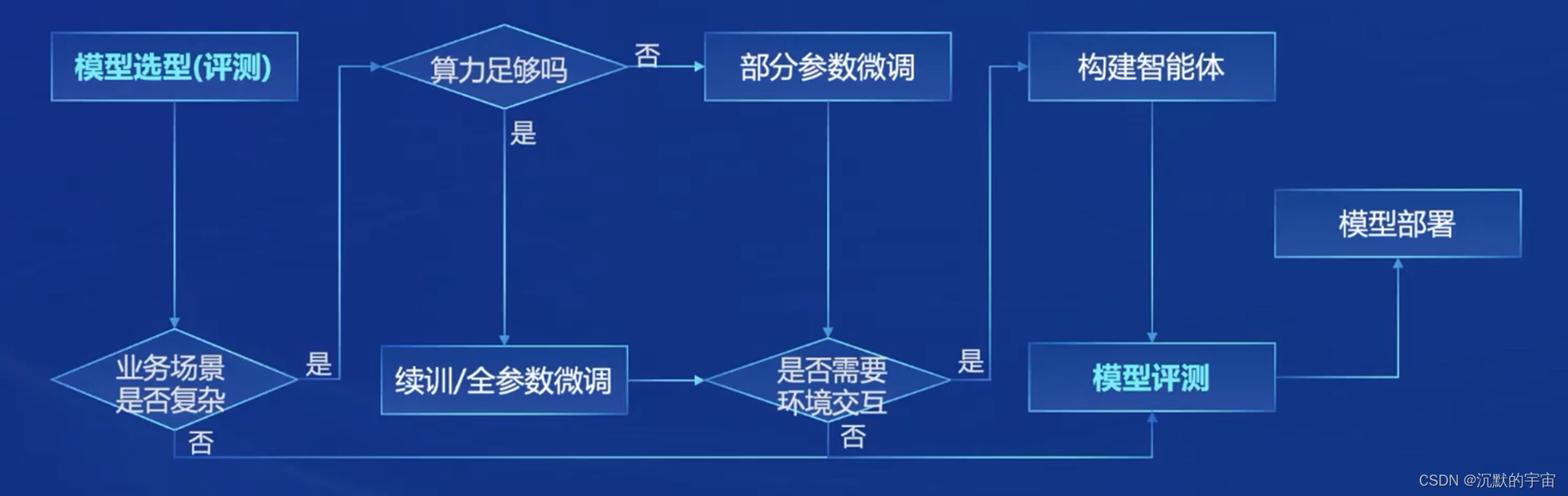
全链条开源开放体系
数据
开源数据集:openDataLab

预训练

微调

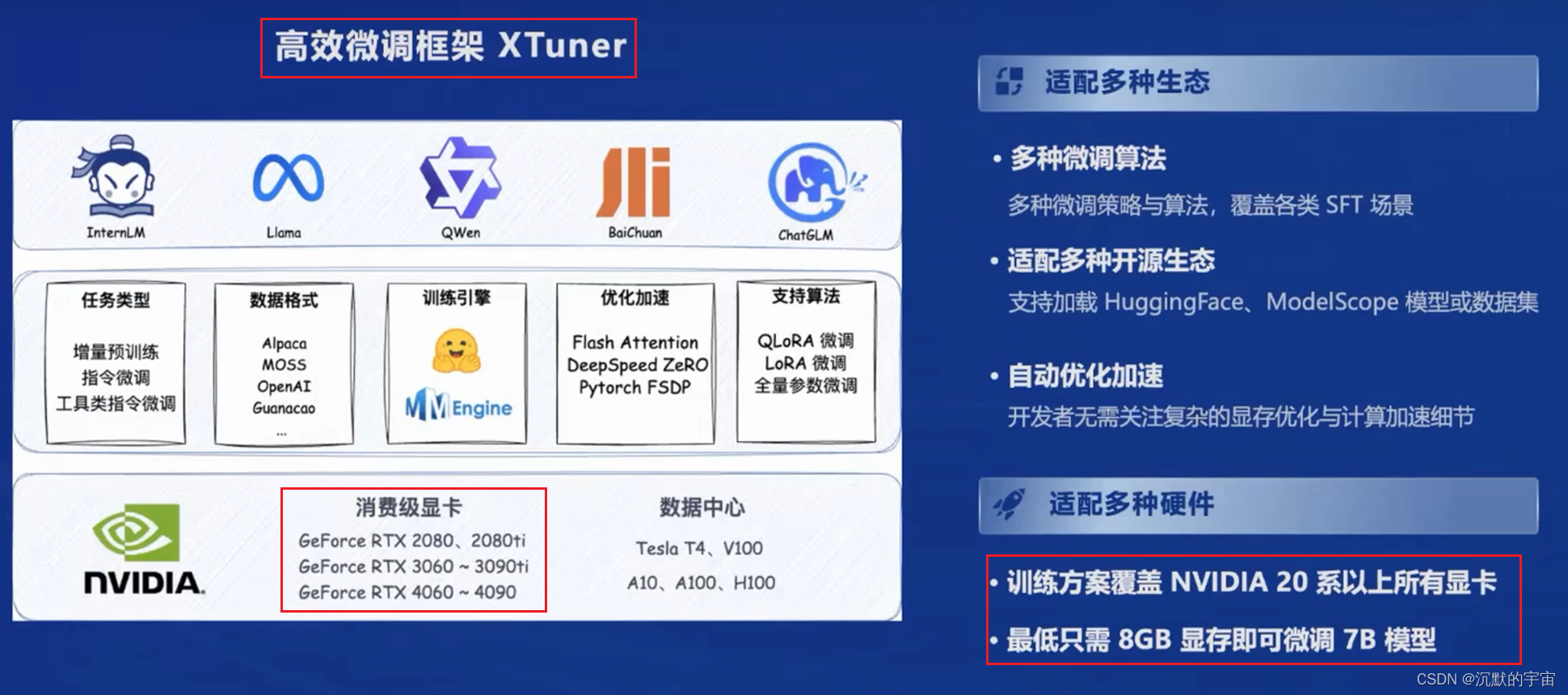
部署
部署工具: LMDeploy

评测
评测工具:openCompas


应用
















 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









