







目录
(1)二维卷积(单通道卷积版本)(2D Convolution: the single channel version)
(2)二维卷积(多通道版本)(2D Convolution: the multi-channel version)
2、反卷积(转置卷积 / 去卷积)(Deconvolution / Transposed / Fractionally Strided Convolution)
3、空洞卷积(膨胀卷积)(Dilated Convolution / Atrous Convolution)
4、可分离卷积(Separable Convolutions)
(1)空间可分离卷积(Spatially Separable Convolutions)
(2)深度可分离卷积(Depthwise Separable Convolutions)
5、扁平卷积(Flattened convolutions)
7、混洗分组卷积(Shuffled Grouped Convolution)
一、卷积的基本属性
- 卷积核(Kernel):卷积操作的感受野,直观理解就是一个滤波矩阵,普遍使用的卷积核大小为3×3、5×5等;
- 步长(Stride):卷积核遍历特征图时每步移动的像素,如步长为1则每次移动1个像素,步长为2则每次移动2个像素(即跳过1个像素),以此类推;
- 填充(Padding):处理特征图边界的方式,一般有两种,一种是对边界外完全不填充,只对输入像素执行卷积操作,这样会使输出特征图的尺寸小于输入特征图尺寸;另一种是对边界外进行填充(一般填充为0),再执行卷积操作,这样可使输出特征图的尺寸与输入特征图的尺寸一致;
- 通道(Channel):卷积层的通道数(层数)。
二、卷积的各种类型
1、标准卷积
(1)二维卷积(单通道卷积版本)(2D Convolution: the single channel version)
只有一个通道的卷积。

(2)二维卷积(多通道版本)(2D Convolution: the multi-channel version)
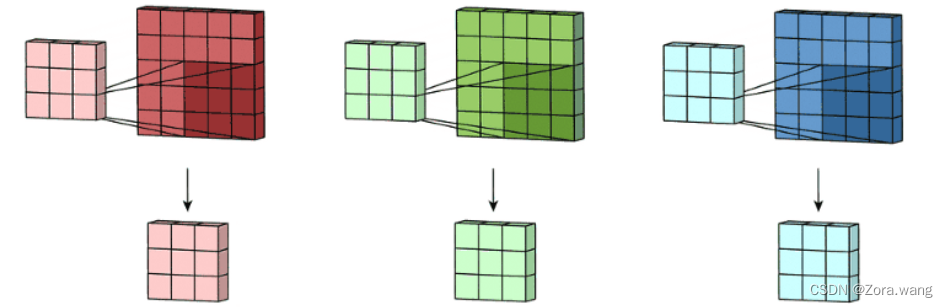
拥有多个通道的卷积,例如处理彩色图像时,分别对R, G, B这3个层处理的3通道卷积。实际我们上是对一个 3D 体积执行卷积。但通常而言,我们仍在深度学习中称之为 2D 卷积。这是在 3D 体积数据上的 2D 卷积。过滤器深度与输入层深度一样。这个 3D 过滤器仅沿两个方向移动(图像的高和宽),再将三个通道的卷积结果进行合并(一般采用元素相加),这种操作的输出是一张 2D 图像(仅有一个通道),如下图:

(3)三维卷积(3D Convolution)
这是 2D 卷积的泛化。3D 卷积的过滤器深度小于输入层深度(核大小<通道大小)。因此,3D 过滤器可以在所有三个方向(图像的高度、宽度、通道)上移动。在每个位置,逐元素的乘法和加法都会提供一个数值。因为过滤器是滑过一个 3D 空间,所以输出数值也按 3D 空间排布。也就是说输出是一个 3D 数据。如下图:

(4)1x1卷积(1 x 1 Convolution)
当卷积核尺寸为1x1时的卷积,也即卷积核变成只有一个数字。如下图:

从上图可以看出,1x1卷积的作用在于能有效地减少维度(channel),降低计算的复杂度。1x1卷积在GoogLeNet网络结构中广泛使用。
2、反卷积(转置卷积 / 去卷积)(Deconvolution / Transposed / Fractionally Strided Convolution)
卷积是对输入图像提取出特征(可能尺寸会变小),而所谓的“反卷积”便是进行相反的操作。但这里说是“反卷积”并不严谨,因为并不会完全还原到跟输入图像一样,一般是还原后的尺寸与输入图像一致,主要用于向上采样。实现上采样的传统方法是应用插值方案或人工创建规则。而神经网络等现代架构则倾向于让网络自己自动学习合适的变换,“反卷积”相当于是将卷积核转换为稀疏矩阵后进行转置计算,因此,也被称为“转置卷积”
如下图,在2x2的输入图像上应用步长为1、边界全0填充的3x3卷积核,进行转置卷积(反卷积)计算,向上采样后输出的图像大小为4x4
3、空洞卷积(膨胀卷积)(Dilated Convolution / Atrous Convolution)
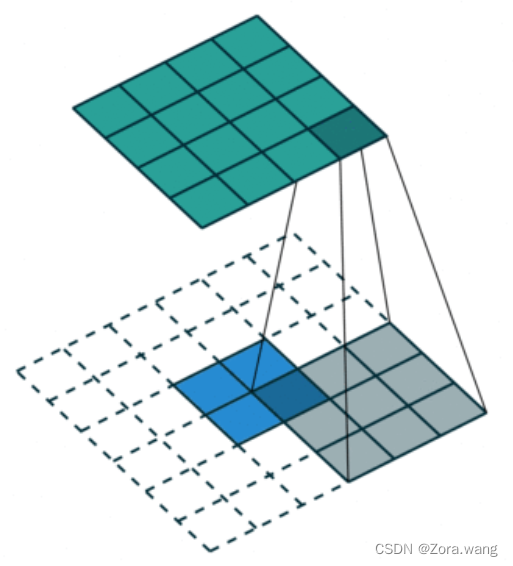
为扩大感受野,在卷积核里面的元素之间插入空格来“膨胀”内核,形成“空洞卷积”(或称膨胀卷积),并用膨胀率参数L表示要扩大内核的范围,即在内核元素之间插入L-1个空格。当L=1时,则内核元素之间没有插入空格,变为标准卷积。
如下图为膨胀率L=2的空洞卷积:

4、可分离卷积(Separable Convolutions)
某些神经网络架构使用了可分卷积,比如 MobileNets。可分卷积有空间可分卷积和深度可分卷积。
(1)空间可分离卷积(Spatially Separable Convolutions)
空间可分卷积操作的是图像的 2D 空间维度,即高和宽。从概念上看,空间可分卷积是将一个卷积分解为两个单独的运算。对于下面的示例,3×3 的 Sobel 核被分成了一个 3×1 核和一个 1×3 核。

在卷积中,3×3 核直接与图像卷积。在空间可分卷积中,3×1 核首先与图像卷积,然后再应用 1×3 核。这样,执行同样的操作时仅需 6 个参数,而不是 9 个。
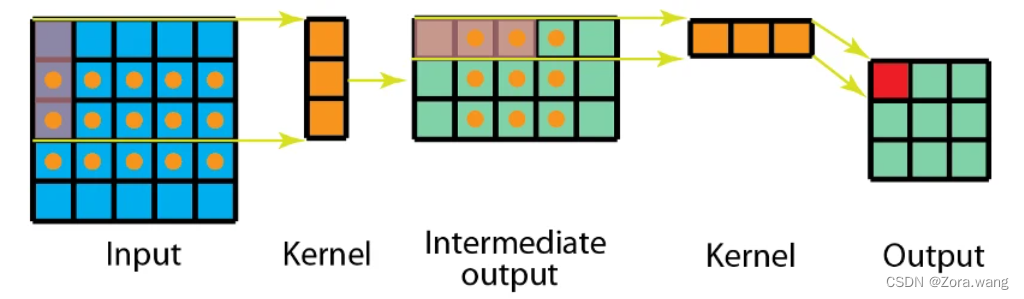
此外,使用空间可分卷积时所需的矩阵乘法也更少。给一个具体的例子,首先在 5×5 的图像上应用一个 3×1 的过滤器。我们可以在水平 5 个位置和垂直 3 个位置扫描这样的核。总共就是 5×3=15 个位置,表示为下图中的点。在每个位置,会应用 3 次逐元素乘法。总共就是 15×3=45 次乘法。现在我们得到了一个 3×5 的矩阵。这个矩阵再与一个 1×3 核卷积,即在水平 3 个位置和垂直 3 个位置扫描这个矩阵。对于这 9 个位置中的每一个,应用 3 次逐元素乘法。这一步需要 9×3=27 次乘法。因此,总体而言,空间可分卷积需要 45+27=72 次乘法,少于普通卷积。
空间可分卷积与标准卷积的计算成本比为:
![]()
因为图像尺寸 N 远大于过滤器大小(N>>m),所以这个比就变成了 2/m。也就是说,在这种渐进情况(N>>m)下,当过滤器大小为 3×3 时,空间可分卷积的计算成本是标准卷积的 2/3。过滤器大小为 5×5 时这一数值是 2/5;过滤器大小为 7×7 时则为 2/7。
尽管空间可分卷积能节省成本,但深度学习却很少使用它。一大主要原因是并非所有的核都能分成两个更小的核。如果我们用空间可分卷积替代所有的传统卷积,那么我们就限制了自己在训练过程中搜索所有可能的核。这样得到的训练结果可能是次优的。
(2)深度可分离卷积(Depthwise Separable Convolutions)
现在来看深度可分卷积,这在深度学习领域要常用得多(比如 MobileNet 和 Xception)。深度可分卷积包含两个步骤:深度卷积核 1×1 卷积。
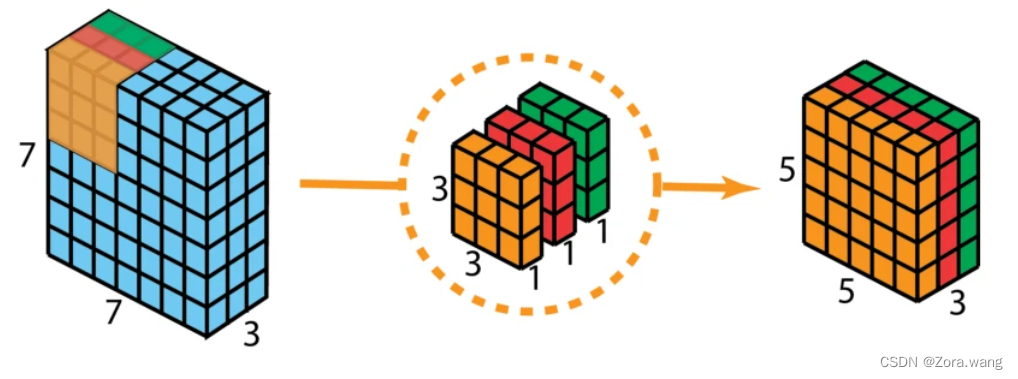
首先,在输入层上应用深度卷积,但我们不使用 2D 卷积中大小为 3×3×3 的单个过滤器,而是分开使用 3 个核。每个过滤器的大小为 3×3×1。每个核与输入层的一个通道卷积(仅一个通道,而非所有通道!)。如下图,使用3个卷积核分别对输入层的3个通道作卷积计算,再堆叠在一起。
再使用1x1的卷积(3个通道)进行计算,得到只有1个通道的结果:

重复多次1x1的卷积操作(如下图为128次),则最后便会得到一个深度的卷积结果。

相比于 2D 卷积,深度可分卷积所需的操作要少得多:
- 使用简单的 2D 卷积例子的计算成本:有 128 个 3×3×3 个核移动了 5×5 次,也就是 128 x 3 x 3 x 3 x 5 x 5 = 86400 次乘法。
- 使用分卷积成本:在第一个深度卷积步骤,有 3 个 3×3×1 核移动 5×5 次,也就是 3x3x3x1x5x5 = 675 次乘法。在 1×1 卷积的第二步,有 128 个 1×1×3 核移动 5×5 次,即 128 x 1 x 1 x 3 x 5 x 5 = 9600 次乘法。因此,深度可分卷积共有 675 + 9600 = 10275 次乘法。这样的成本大概仅有 2D 卷积的 12%!
所以,对于任意尺寸的图像,如果我们应用深度可分卷积,我们可以节省多少时间?让我们泛化以上例子。现在,对于大小为 H×W×D 的输入图像,如果使用 Nc 个大小为 h×h×D 的核执行 2D 卷积(步幅为 1,填充为 0,其中 h 是偶数)。为了将输入层(H×W×D)变换到输出层((H-h+1)x (W-h+1) x Nc),所需的总乘法次数为:
Nc x h x h x D x (H-h+1) x (W-h+1)
另一方面,对于同样的变换,深度可分卷积所需的乘法次数为:
D x h x h x 1 x (H-h+1) x (W-h+1) + Nc x 1 x 1 x D x (H-h+1) x (W-h+1) = (h x h + Nc) x D x (H-h+1) x (W-h+1)
则深度可分卷积与 2D 卷积所需的乘法次数比为:
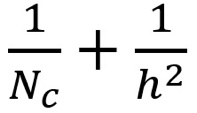
现代大多数架构的输出层通常都有很多通道,可达数百甚至上千。对于这样的层(Nc >> h),则上式可约简为 1 / h。基于此,如果使用 3×3 过滤器,则 2D 卷积所需的乘法次数是深度可分卷积的 9 倍。如果使用 5×5 过滤器,则 2D 卷积所需的乘法次数是深度可分卷积的 25 倍。
使用深度可分卷积有什么坏处吗?当然是有的。深度可分卷积会降低卷积中参数的数量。因此,对于较小的模型而言,如果用深度可分卷积替代 2D 卷积,模型的能力可能会显著下降。因此,得到的模型可能是次优的。但是,如果使用得当,深度可分卷积能在不降低你的模型性能的前提下帮助你实现效率提升。
5、扁平卷积(Flattened convolutions)
扁平卷积是将标准卷积核拆分为3个1x1的卷积核,然后再分别对输入层进行卷积计算。这种方式,跟前面的“空间可分离卷积”类似,如下图:

6、分组卷积(Grouped Convolution)
2012年,AlexNet论文中最先提出来的概念,当时主要为了解决GPU显存不足问题,将卷积分组后放到两个GPU并行执行。

在分组卷积中,卷积核被分成不同的组,每组负责对相应的输入层进行卷积计算,最后再进行合并。如下图,卷积核被分成前后两个组,前半部分的卷积组负责处理前半部分的输入层,后半部分的卷积组负责处理后半部分的输入层,最后将结果合并组合。
7、混洗分组卷积(Shuffled Grouped Convolution)
在分组卷积中,卷积核被分成多个组后,输入层卷积计算的结果仍按照原先的顺序进行合并组合,这就阻碍了模型在训练期间特征信息在通道组之间流动,同时还削弱了特征表示。而混洗分组卷积,便是将分组卷积后的计算结果混合交叉在一起输出。
如下图,在第一层分组卷积(GConv1)计算后,得到的特征图先进行拆组,再混合交叉,形成新的结果输入到第二层分组卷积(GConv2)中:
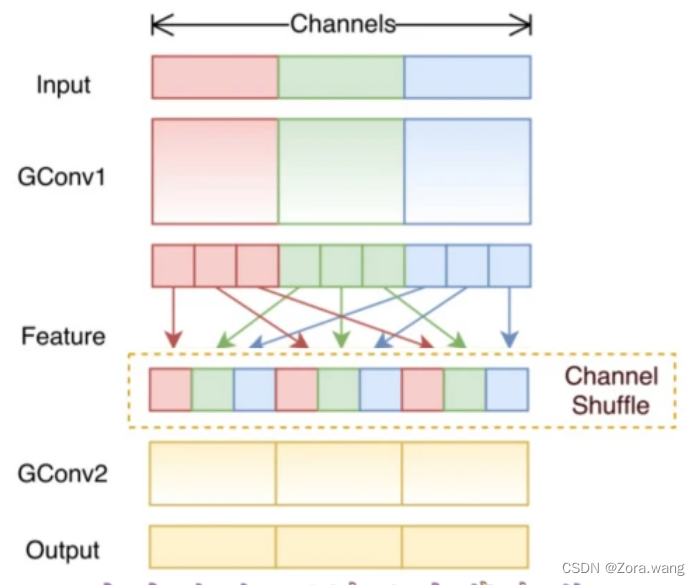
备注:分组卷积与深度卷积
分组卷积与深度可分卷积中使用的深度卷积之间存在一些联系和差异。如果过滤器分组的数量与输入层通道的数量相同,则每个过滤器的深度都为 Din/Din=1。这样的过滤器深度就与深度卷积中的一样了。
另一方面,现在每个过滤器分组都包含 Dout/Din 个过滤器。整体而言,输出层的深度为 Dout。这不同于深度卷积的情况——深度卷积并不会改变层的深度。在深度可分卷积中,层的深度之后通过 1×1 卷积进行扩展。
分组卷积有几个优点:
- 第一个优点是高效训练。因为卷积被分成了多个路径,每个路径都可由不同的 GPU 分开处理,所以模型可以并行方式在多个 GPU 上进行训练。相比于在单个 GPU 上完成所有任务,这样的在多个 GPU 上的模型并行化能让网络在每个步骤处理更多图像。人们一般认为模型并行化比数据并行化更好。后者是将数据集分成多个批次,然后分开训练每一批。但是,当批量大小变得过小时,我们本质上是执行随机梯度下降,而非批梯度下降。这会造成更慢,有时候更差的收敛结果。在训练非常深的神经网络时,分组卷积会非常重要,正如在 ResNeXt 中那样。

图片来自 ResNeXt 论文,https://arxiv.org/abs/1611.05431
- 第二个优点是模型会更高效,即模型参数会随过滤器分组数的增大而减少。在之前的例子中,完整的标准 2D 卷积有 h x w x Din x Dout 个参数。具有 2 个过滤器分组的分组卷积有 (h x w x Din/2 x Dout/2) x 2 个参数。参数数量减少了一半。
- 第三个优点有些让人惊讶。分组卷积也许能提供比标准完整 2D 卷积更好的模型。另一篇出色的博客已经解释了这一点:https://blog.yani.io/filter-group-tutorial。















 8940
8940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









