







Pytorch随记
前序知识的讲解
监督学习的应用主要在三个方面:回归问题、标注问题和分类问题
- 分类问题是指 当输出变量Y取值有限个离散值时,预测问题便成了分类问题。
- 标注也是一个监督学习的问题,可以认为标注问题是分类问题的推广,标注问题又是更复杂的解耦预测问题的简单形式。标注问题的输入是一个观测序列,输出的是一个标记序列或者状态序列
- 回归用于预测输入变量(自变量)和输出变量(因变量)之间的关系,特别别是输入变量的值发生变化的时候,输出变量的值随之发生的变化。
可以这样理解这问题,回归问题就是用来预测一个值,比如房价、天气等;分类问题是用于给事物打标签,看看这个输入值是什么东西,比如看看图片上的数字是什么;
处理多维特征的输入
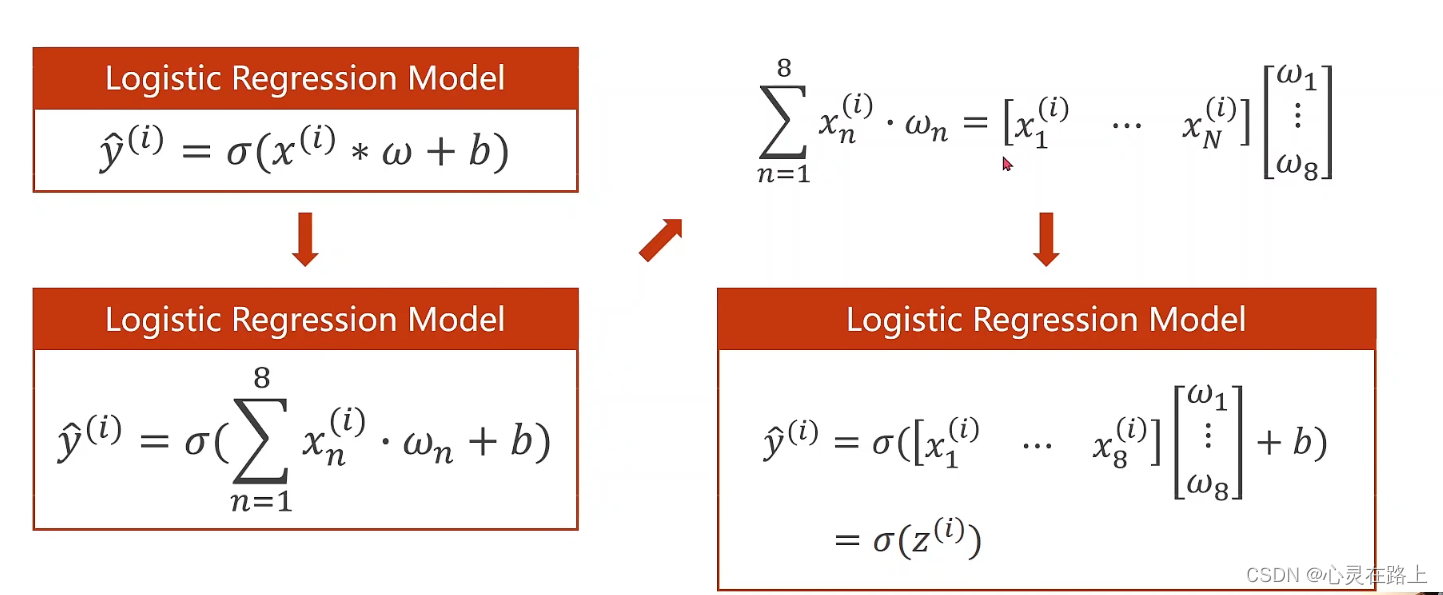
- 因为输入的X已经不是单纯的一维的了,所以在计算的时候就要用到了内积和矩阵转换方面的知识。这里要注意求的是内积,我们要计算所有的
y
^
\hat{y}
y^的值。其中
σ
\sigma
σ是指sigmod激活函数
s i g m o d = 1 1 + e − x sigmod = \frac{1}{1+e^{-x}} sigmod=1+e−x1

这里刘老师说明了,其实所有的X可以放到一个矩阵里面进行计算,这里也讲解了矩阵之间的转换,讲了N×8的矩阵是如何降为N×1的。这里不懂的话建议去翻翻书。
import numpy as np
import torch
import matplotlib.pyplot as plt
# 准备数据
xy = np.loadtxt('diabetes.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, [-1]]) # [-1] 最后得到的是个矩阵
# 创建模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
#降维的过程
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 2)
self.linear4 = torch.nn.Linear(2, 1)
self.sigmoid = torch.nn.Sigmoid() # 给模型添加一个非线性的变换。求Y_hat
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x)) # y hat
x = self.sigmoid(self.linear4(x)) # y hat
return x
model = Model()
#创建损失函数和优化器
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
#训练
for epoch in range(1000000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
# print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
#这里使用acc为评价指标进行预测
if epoch%100000 == 99999:
y_pred_label = torch.where(y_pred>=0.5,torch.tensor([1.0]),torch.tensor([0.0]))
acc = torch.eq(y_pred_label, y_data).sum().item()/y_data.size(0)
print("loss = ",loss.item(), "acc = ",acc)
会使用到的一些概念
Mini-Batch
mini_batch 就是用随机梯度下降进行训练,综合了随机梯度下降随机性和batch的向量计算速度的优势。
for epoch in range(training_epochs):
for i in range(totle_batch):
- 第一个循环中epoch 指的是全部样本进行一次训练,也就是说所有样本都进行了前向和反向。
- 第二个循环就是执行一次Mini—Batch
Batch-Size
指的是所有进行前向和反向训练的样本数量
iterations
指的是第二层for循环迭代的次数
DataLoader
文档中的介绍
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False)
数据加载器。 结合数据集和采样器,并提供给定数据集的可迭代对象。
DataLoader 支持具有单进程或多进程加载、自定义加载顺序以及可选的自动批处理(整理)和内存固定的地图样式和可迭代样式数据集。
Parameters
-
dataset (Dataset) – 从中加载数据的数据集。
-
batch_size (int, optional) – 每批加载多少样本(默认值:1)。
-
shuffle (bool, optional) –设置为 True 以在每个 epoch 重新排列数据(默认值:False)。(实现随机梯度下降)
-
sampler (Sampler or Iterable, optional) –定义从数据集中抽取样本的策略。 可以是任何实现了 len 的 Iterable。 如果指定,则不得指定 shuffle。
-
batch_sampler (Sampler or Iterable, optional) – 像采样器,但一次返回一批索引。 与 batch_size、shuffle、sampler 和 drop_last 互斥。
-
num_workers (int, optional) – 用于数据加载的子进程数。 0 表示数据将在主进程中加载。 (默认值:0)
-
collate_fn (callable, optional) – 合并样本列表以形成小批量张量。 从地图样式数据集中使用批量加载时使用。
-
pin_memory (bool, optional) – 如果为 True,数据加载器将在返回之前将张量复制到 CUDA 固定内存中。 如果您的数据元素是自定义类型,或者您的 collate_fn 返回一个自定义类型的批次,请参见下面的示例。
-
drop_last (bool, optional) – 如果数据集大小不能被批次大小整除,则设置为 True 以删除最后一个不完整的批次。 如果 False 并且数据集的大小不能被批大小整除,则最后一批将更小。 (默认:False )
-
timeout (numeric, optional) – 如果为正,则从工人那里收集批次的超时值。 应始终为非负数。 (默认值:0)
-
worker_init_fn (callable, optional) – 如果不是 None,这将在播种之后和数据加载之前在每个工作子进程上调用,并使用工作 id([0,num_workers - 1] 中的一个 int)作为输入。 (默认:无)
-
generator (torch.Generator, optional) –如果不是 None,则 RandomSampler 将使用此 RNG 生成随机索引和多处理以生成工作人员的 base_seed。 (默认:无)
-
prefetch_factor (int, optional, keyword-only arg) – 每个工作人员预先加载的样本数。 2 表示将在所有工作人员中预取总共 2 * num_workers 个样本。 (默认值:2)
-
persistent_workers (bool, optional) – 如果为 True,数据加载器将不会在数据集被使用一次后关闭工作进程。 这允许保持工作人员数据集实例处于活动状态。 (默认:假)
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
其中dataset 是一个抽象类,只能继承,不能直接使用;DataLoader是用来帮我们加载数据的。
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset (Dataset) :
def __init__(self):
pass
def __getitem__(self, index) :
pass
def __len__(self):
pass
dataset = DiabetesDataset ()
train_loader=DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
这里我们定义的时候需要定义两个函数,一个是getitem函数,用来根据索引拿出数据,len函数用来返回条数。

在进行训练的时候,如果直接使用循环进行的话,会报错,这是因为底层接口的问题,我们可以定义成一个函数封装起来,或者使用if__name__ == “main”: 也就是写代码常用的调试。
import numpy as np
import torch
import matplotlib.pyplot as plt
# prepare dataset
xy = np.loadtxt('diabetes.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1]) # 第一个‘:’是指读取所有行,第二个‘:’是指从第一列开始,最后一列不要
# print("input data.shape", x_data.shape)
y_data = torch.from_numpy(xy[:, [-1]]) # [-1] 最后得到的是个矩阵
#print(x_data.shape)
#design model using class
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 2)
self.linear4 = torch.nn.Linear(2, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x)) # y hat
x = self.sigmoid(self.linear4(x)) # y hat
return x
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
#training cycle forward, backward, update
for epoch in range(200):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
# print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
y_pred_label = torch.where(y_pred>=0.5,torch.tensor([1.0]),torch.tensor([0.0]))
acc = torch.eq(y_pred_label, y_data).sum().item()/y_data.size(0)
print("loss = ",loss.item(), "acc = ",acc)
torch.datasets
在torch.datasets中还有很多数据集,参考文档https://pytorch.org/vision/stable/datasets.html
以下是使用格式
import torch
from torch. utils. data import DataLoader
from torchvision import transforms
from torchvision import datasets
train_dataset=datasets.MNIST(root='./datasets/mnist',
train=True,
transform= transforms.ToTensor(),#转换到张量
download=True)
test_dataset=datasets.MNIST(root='./datasets/mnist',
train=False,
transform= transforms.ToTensor(),
download=True)
train_loader=DataLoader(dataset=train_dataset,
batch_size=32,
shuffle=True)
# 测试的时候不需要随机
test_loader = DataLoader(dataset=test_dataset,
batch_size=32,
shuffle=False)
for batch_idx,(inputs,target) in enumerate(train_loader):
多分类问题
softmax Classifier
在计算
o
1
o_{1}
o1,
o
2
o_{2}
o2等的概率的时候会遇见一个问题,P(y=0)=0.9,
P(y=1)=0.8,P(y=2)=0.7,这样三个概率相加的结果超过了1,而且你不能简单的选择概率最大的作为分类结果,这样不合适。所以我们要归一化,将输出的结果的和相加等于1。
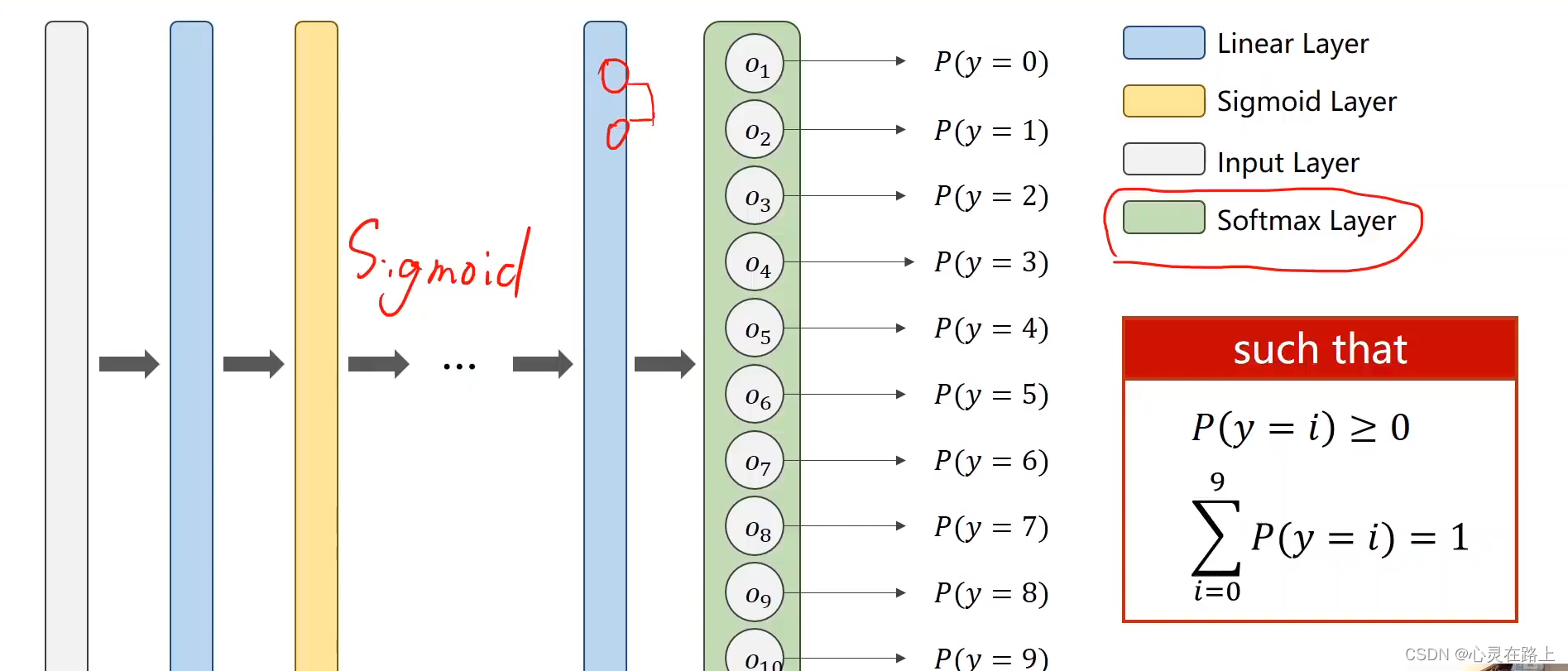
softmax 函数可以用来使输出的结果都大于0且相加之和等于1。
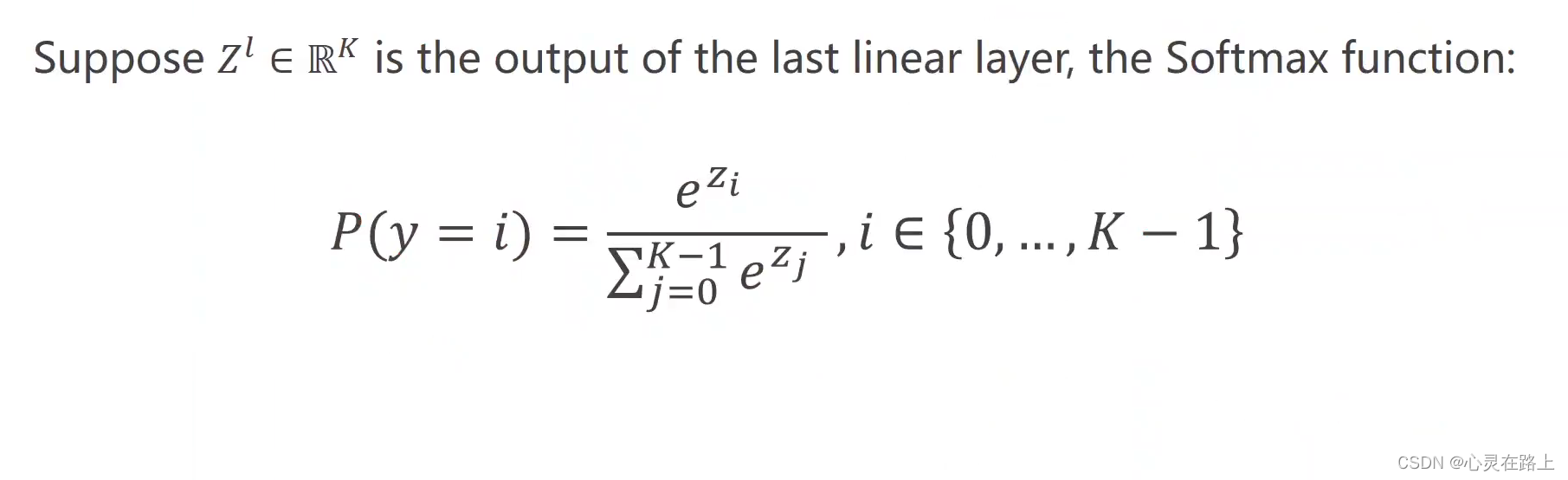
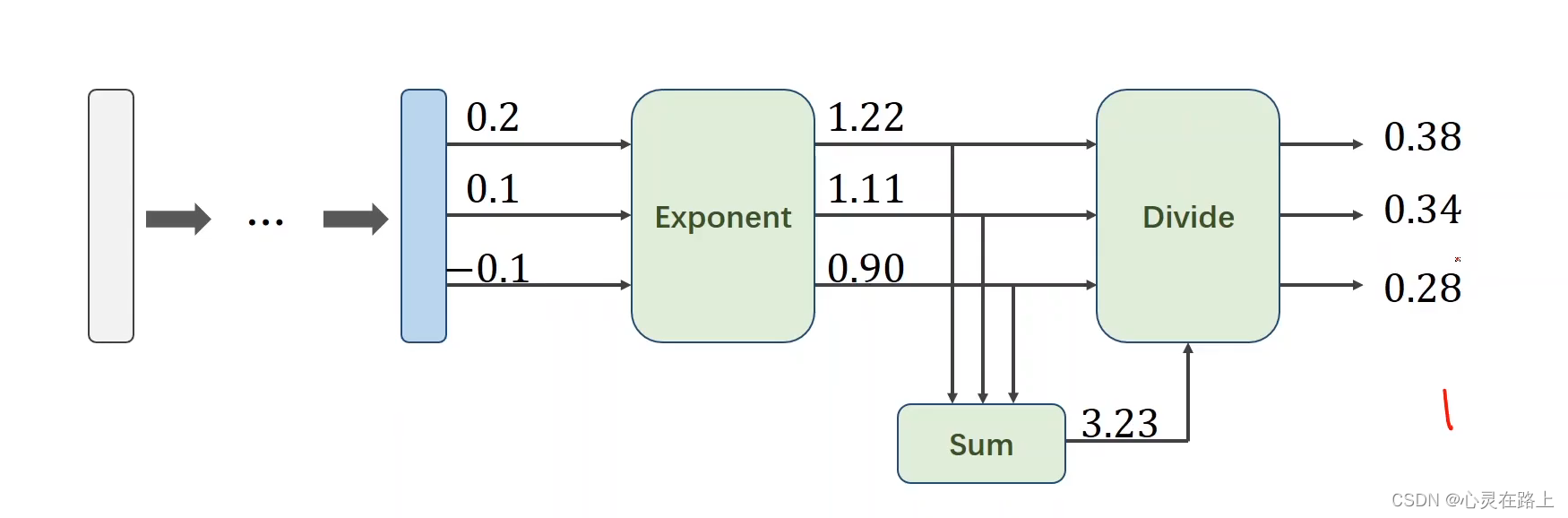
下面就是求解过程的一个展示。
求EXP和Divide的过程就是softmax。
Loss function
NLLLoss
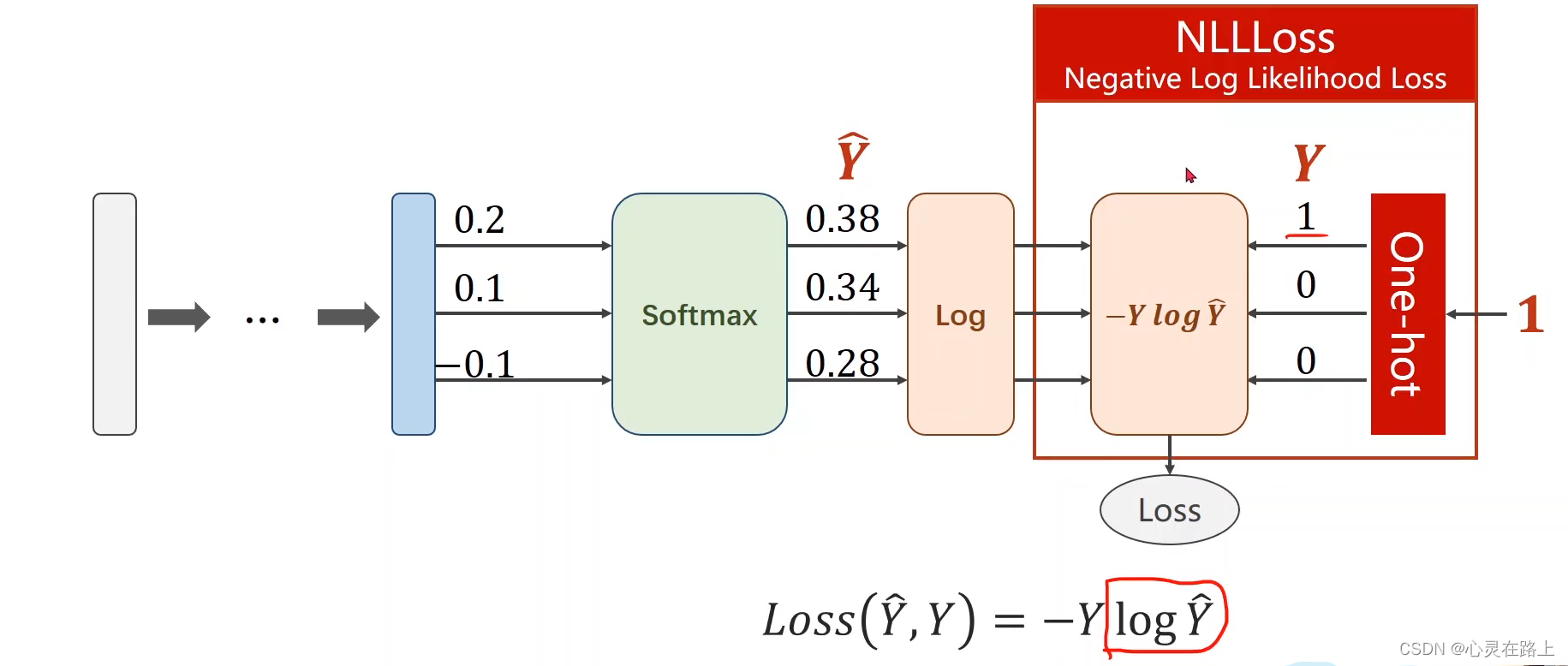
这里求NLLLoss是没有求log的过程的,所以我们要在使用损失函数前,计算log的值
import numpy as np
y = np.array([1,0,0)
z = np.array([0.2,0.1,-0.1)
y_pred = np.exp(z)/np.exp(z).sun()
loss = (-y * np.log(y_pred)).sum()
print(loss)
CrossEntropyLoss
相信会有道友了解过交叉熵,上面的过程其实就是在计算交叉熵,在torch里面也有封装好的库。
这里顺带说一下为什么
−
Y
l
o
g
y
^
-Ylog\hat{y}
−Ylogy^要加负号,因为是概率值小于1,求出的log值时负的
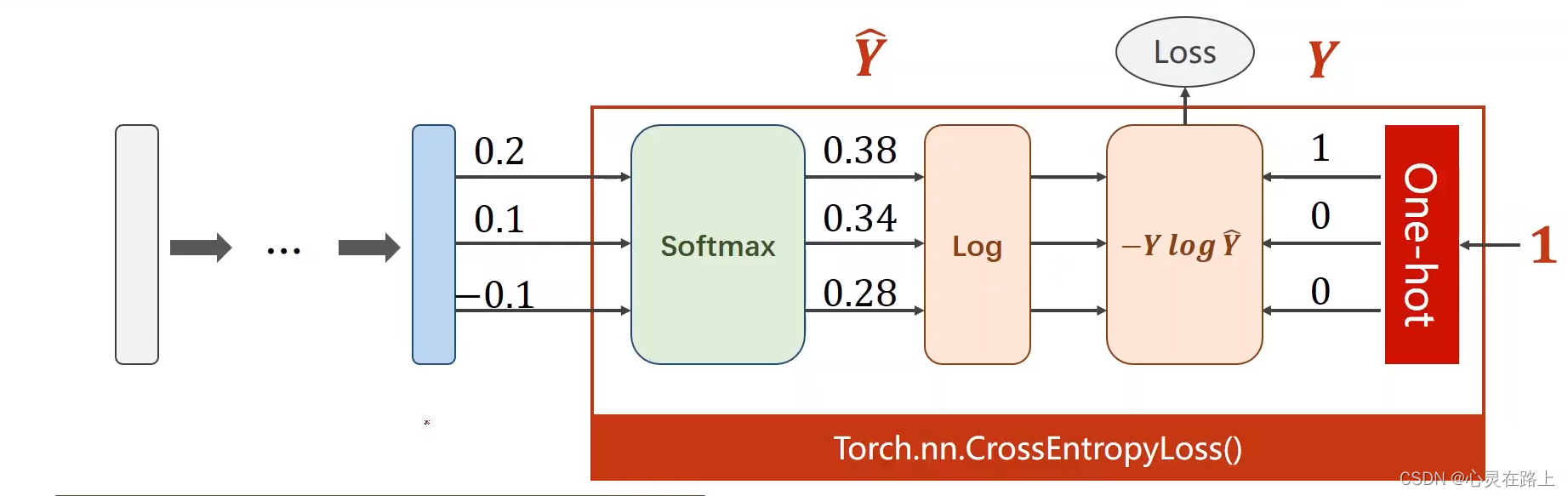
CLASStorch.nn.CrossEntropyLoss(weight=None,
size_average=None,
ignore_index=- 100,
reduce=None,
reduction='mean',
label_smoothing=0.0)
import torch
y = torch.LongTorch([0])
z = torch.Tensor([0.2, 0.1, -0.1])
criterion = -torch.nn.CrossEntropyLoss()
loss = criterion(z, y)
print(loss)
练习
import torch
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
#这里Normalize归一化 第一个值时mean均值,第二个是标准差,为什么写这两个数,老师说是算出来的.....
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081))
])
#读取数据切记要有相应文件夹,不然会报错
train_dataset=datasets.MNIST(root='./datasets/mnist/',train=True,transform= transforms.ToTensor(),download=True)
test_dataset=datasets.MNIST(root='./datasets/mnist/',train=False,transform= transforms.ToTensor(),download=True)
train_loader=DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
#测试的时候不需要随机
test_loader = DataLoader(dataset=test_dataset,batch_size=batch_size,shuffle=False)
#创建linear的时候上下只要收尾数字一致就可以,
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
# 这里用的是relu
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
#momentum 动量因子,必须是浮点数,可以优化训练过程
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1,momentum = 0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print("[%d,%5d] loss: %.3f" % (epoch + 1, batch_idx + 1, running_loss /300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim = 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print("Accuracy on test set : %d %%"% (100 * correct /total))
for epoch in range(10):
train(epoch)
test()















 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









