






文章题目:
VoxCeleb: a large-scale speaker identification dataset
VoxCeleb2: Deep Speaker Recognition
文章地址:
http://www.robots.ox.ac.uk/~vgg/publications/2017/Nagrani17/nagrani17.pdf http://www.robots.ox.ac.uk/~vgg/publications/2018/Chung18a/chung18a.pdf
数据集下载地址:
http://www.robots.ox.ac.uk/~vgg/data/voxceleb/
背景
在无约束、噪声条件下的说话人识别是一个极具挑战性的课题。从高安全性系统中的身份验证和法医测试,到在大型语音数据库中搜索人员,说话人识别具有丰富的应用场景。所有这些场景都要求其在真实环境下具有较高的识别性能。这是一项极其困难的任务,因为在真实环境中,不仅包含各种外在变量(如背景交谈、背景音乐、笑声、混响、通道和麦克风影响),还包含了多种的内在变量(如说话人年龄、口音、情绪、声调和说话方式)。
说话人识别任务在很长一段时间内使用的是高斯混合模型(GMM)算法,后来有了i-vectors算法等。这些算法都基于低维度的特征,比如MFCC特征。然而,MFCC特征不仅在有噪音时衰退严重,而且它表示的是语音的整体包络特征,缺少了可能包含说话人判别性特征的信息(比如音高)。另一方面,卷积神经网络(Convolutional Neural Network, CNN)无须手工产生特征就可以处理真实环境下的噪音数据,因而在语音识别、计算机视觉等领域取得了明显效果。因此,CNN作为特征提取器更加适用于说话人识别任务,但这也意味着需要喂给它大量的真实环境下的数据。
大多数说话人识别数据集是在受限制的条件下采集并手工标注的,这些因素大大限制了数据集的规模。而本文介绍的两篇文章正是目前最大规模的与文本无关的“自然”说话人识别数据集,即VoxCeleb1和VoxCeleb2数据集。它们分别是牛津大学在2017年与2018年发布的大规模开源音视频数据集。
数据集介绍
VoxCeleb1和VoxCeleb2是没有重复交集的两个说话人识别数据集,它们均是通过一套基于计算机视觉技术开发的全自动程序从开源视频网站中捕捉而得到的。它们的区别在于规模大小的不同,而这是由于相关的全自动数据集采集程序的不同而造成的。在下面的章节中会详细介绍改进后的全自动数据集采集程序(构建VoxCeleb2数据集所用程序)。除此之外,两者均具有以下相同特性:
1.数据属于自然环境下的真实场景,音视频取自于YouTube网站;
2.属于完全真实的英文语音;
3.数据集是文本无关的;
4.说话人范围广泛,具有多样的种族,口音,职业和年龄;
5.数据集男女性别分布均衡;
6.音频的采样率为16kHz,16bit,单声道,PCM-WAV格式;
7.语音带有一定真实噪声,非人造白噪声,噪声出现时间点无规律,人声有大有小;
8.噪声包括:环境突发噪声、背景人声、笑声、语音混叠、回声、室内噪音、录音设备噪音等;
9.视频场景包括:明星红地毯、名人讲台演讲、真人节目访谈、大型体育场解说等;
VoxCeleb2弥补了VoxCeleb1中缺乏种族多样性的不足,在数据规模上是VoxCeleb1的五倍,它们的数据集的比较如下表1所示。其中,POI指数据集中包含的说话人。
下图1展示了VoxCeleb2数据集的示例和相关统计信息。从图中可以看出,数据集中的每段音频均均有对应的说话人。下面一行是对数据集的统计信息,可以看出其涵盖了更多种族、口音和地区。
数据集构建流程
VoxCeleb2数据集的构建流程是在VoxCeleb1数据集的基础上经过改进取得的。下面着重介绍VoxCeleb2数据集的全自动构建流程。
该流程分为以下几个阶段:
-阶段1:选取感兴趣人员名单(POIs)
选用VGGFace2数据集中的人员列表,该列表具有相当大的种族多样性和职业多样性。这份名单包含了9000多个人物,其身份包含演员、运动员、政治家等。与VoxCeleb1和SITW数据集重叠的人员标识也被从列表中删除,以避免重复。
-阶段2:下载视频
通过YouTube搜索并自动下载每个POIs的前100个视频。在搜索查询中,单词“interview”也被附加到POI的名称后面,以增加视频包含POI说话的可能性,降低搜索到体育或音乐视频的概率。
-阶段3:人脸跟踪
本阶段采用基于单镜头多盒检测器(SSD)的CNN人脸检测器来检测每帧视频中的人脸外观。与VoxCeleb1数据集所使用的人脸跟踪器相比,该检测器有明显的改进,可以检测侧面和极端姿势中的人脸。
-阶段4:人脸验证
该阶段的目标是验证人脸跟踪的结果是否属于POI名单。这里使用的分类网络是在VGGFace2数据集上训练的ResNet- 50网络。
-阶段5:主动说话者验证
这个阶段的目标是确定是否当前可见的面孔是说话者。这是通过使用SyncNet的多视图自适应实现的,它是一种双流CNN网络,通过估计音频轨迹和视频嘴部运动之间的相关性来验证主动说话者。该方法同样可以避免视频剪辑中的配音或画外音。
-阶段6:滤重
使用YouTube作为视频来源通常会遇到相同的视频(或视频的一部分)被上传多次的情形。因此,文章设计了重复视频的识别和删除算法,其过程如下:计算同一说话人的所有特征对之间的距离,如果任何两个语音段之间的距离小于一个非常保守的阈值,则认为这两个语音段是相同的,并删除其中一个。这种方法能精确识别所有的重复。
-阶段7:获得说话人国籍标签
从维基百科上为数据集中的所有名人抓取国籍标签。为了更能体现其口音,文章爬取的目标是名人的国籍国家,而不是种族。除428名被标记为未知外,所有人都获得了国籍标签。数据集中的说话者共来自145个国家(VoxCeleb1为36个),从而具有更丰富的种族多样性。并且,VoxCeleb2包含的美国人比例(29%)要小于VoxCeleb1中美国人所占比例(64%)。
说话人识别算法
文章还提出了基于VoxCeleb2数据集的说话人识别系统,即名为VGGVox的嵌套系统。该系统以直接从原始音频中提取的短时语谱图为训练对象,无需其他预处理。采用深度神经网络主干结构来提取帧级特征,然后池化成句子级别的说话人嵌入向量。整个模型使用对比损失进行训练。为了提高模型性能,该文首先使用softmax层和交叉熵进行了识别预训练。
评估方法:
系统使用的训练集是VoxCeleb2数据集,其在训练阶段生成配对;
系统使用的测试集是VoxCeleb1数据集,其本身就含有配对信息。
文中使用的性能度量标准为:
- 等错误率(EER):即错分正负样本概率相等的值。
- 损失函数:
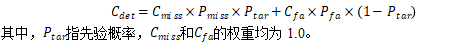 这两个指标经常被用于评估身份验证系统。
这两个指标经常被用于评估身份验证系统。
主干网络:
-VGG-M:该网络是在已有VGG-M CNN网络的基础上稍作修改后形成的。这里的VGG-M网络将原始的VGG-M网络的最后一层全连接层fc6替换成了两层——一层全连接层与一个平均池化层。这样修改后的网络与时间位置无关,与频率有关,这正是语音信号与图像的区别之处。
-ResNets:文中采用了ResNet-34和ResNet-50两种网络架构,为了适应输入层的频谱图对各层稍微做了修改,网络的结构如下表3所示。
训练损失策略:
由于对比损失非常难以训练,因此,为了避免在训练早期出现次优局部极小值,文章分为两步进行训练:
1)使用SoftMax损失进行预识别训练;
本阶段的目的在于通过SoftMax训练初始化网络的权重。为了评估识别性能,文章从每个人物的单个视频中抽取所有语音片段组成了held-out验证集。
2)利用对比损失进行微调。
本阶段将预识别训练网络的分类层(5994个分类标签)替换成输出维度为512的全连接层,使用对比损失再次训练该网络。
测试时间增广:
文章在测试阶段使用三种方式来评估模型性能,分别是:
1)不同的平均池化层;
2)从每个测试样本抽取10个3秒时长的语音片段,计算其特征的均值;
3)从每个测试样本抽取10个3秒时长的语音片段,计算两个测试样本中可能配对(10χ10=100)的距离,使用这100个距离值的均值。该方法稍微提升了性能,如表4所示。
实现细节
-输入特征:使用帧长为25ms、帧移为10ms的汉明窗在原始语音信号中滑动,产生大小为512χ300的语谱图(假设语音信号为3秒时长)。语谱图的每个频率成分均进行了均值和方差正则化。
-训练:在训练阶段,文章从每个语句随机抽样3秒的语音片段。网络的实现基于深度学习工具MatConvNet。每个网络都在三台Titan X GPUs上迭代30次或直到验证集误差停止下降。
实验结果
文章在不同的测试集测试了说话人识别网络的性能,包括:
1)原始的VoxCeleb1测试集。
2)从整个VoxCeleb1数据集抽取的581,480个配对(涵盖1251个人物),从而组成了扩展的VoxCeleb1测试集VoxCeleb1-E。
3)从整个VoxCeleb1数据集中抽取具有相同国籍和性别的数据集作为VoxCeleb1-H数据集。
在以上数据集中的实验效果如下表5所示。
总结
文章为说话人验证任务引入了新的体系结构和训练策略,并在VoxCeleb1数据集上展示了最先进的性能。其学习到的身份嵌套是压缩的(512维),因此易于存储,并可用于检索等其他任务。文章还引入了VoxCeleb2数据集,它比任何说话人识别数据集都要大好几倍,并对VoxCeleb1数据集进行了重新定位,使该整个数据集可以作为说话人验证任务的测试集。
本文已整理pdf文件及word版本,如有需要可私信联系。


















 3959
3959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









