






前言
在C和C++中,malloc函数是用于动态分配内存的常用函数。本文将深入探究malloc函数的内存分配实现机制,详细介绍其工作原理和实现细节。
一、malloc实现原理概括?
malloc函数底层是由brk、mmap系统调用实现的;分为以下几步
初始化内存池:malloc首次调用时,通常会初始化内存池。内存池是预先分配的一大块内存空间,用于满足后续内存分配请求。初始化过程包括从操作系统请求内存(如使用sbrk或mmap系统调用),并建立数据结构来跟踪可用的内存块(称为free list)。
查找合适的内存块:当malloc收到内存分配请求时,它会在free list中查找一个大小满足需求的内存块。内存块查找策略可能有所不同,如首次适配(first fit)、最佳适配(best fit)或最差适配(worst fit)等。策略选择会影响内存分配的性能和内存碎片化程度。如果找不到足够大小的内存,它会从新向操作系统申请,申请大小小于128KB用brk,大于128KB时用mmap。
分割内存块:如果找到的内存块大小远大于请求的内存大小,malloc可能会将其分割成两部分。一部分用于满足当前请求,另一部分保留在free list中以供后续分配使用。
更新数据结构:malloc将找到的内存块从free list中移除,并更新相关的数据结构。此外,malloc通常会在返回的内存块前附加一些元数据(如内存块大小),以便于后续的内存释放(free)和重新分配(realloc)操作。
返回内存块地址:malloc返回分配的内存块地址,供程序使用。需要注意的是,分配的内存块内容可能是未初始化的,需要在使用前进行适当的初始化操作
所以
malloc 申请内存的时候,会有两种方式向操作系统申请堆内存。
方式一:通过 brk() 系统调用从堆分配内存
方式二:通过 mmap() 系统调用在文件映射区域分配内存;
二、brk() 函数与mmap()函数
如果用户分配的内存小于 128 KB,则通过 brk() 申请内存;
如果用户分配的内存大于 128 KB,则通过 mmap() 申请内存;
方式一、实现的方式很简单,就是通过 brk() 函数将「堆顶」指针向高地址移动,获得新的内存空间。如下图:
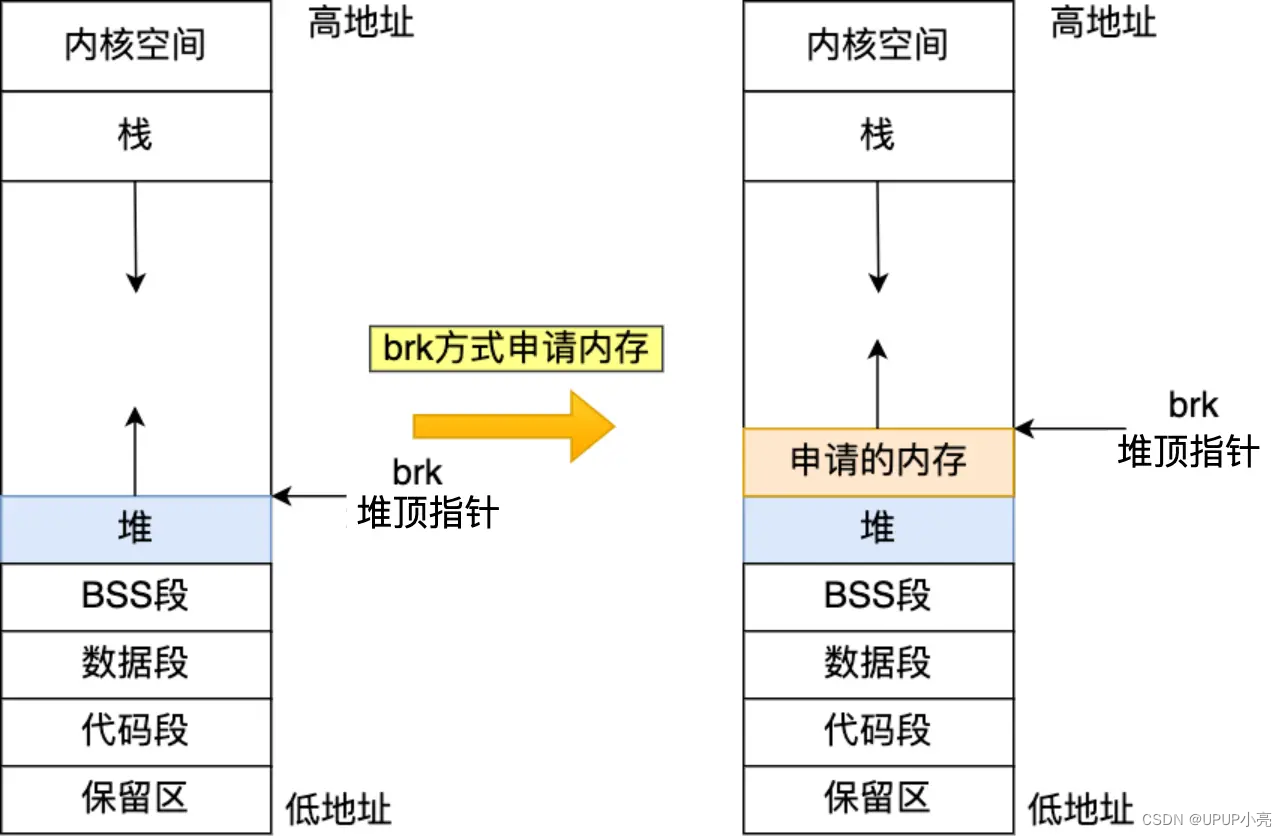
malloc 通过 brk() 方式申请的内存,free 释放内存的时候,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用,这样就可以重复使用。
优点
malloc 通过 brk() 系统调用在堆空间申请内存的时候,由于堆空间是连续的,所以直接预分配更大的内存来作为内存池,当内存释放的时候,就缓存在内存池中。
等下次在申请内存的时候,就直接从内存池取出对应的内存块就行了,而且可能这个内存块的虚拟地址与物理地址的映射关系还存在,这样不仅减少了系统调用的次数,也减少了缺页中断的次数,这将大大降低 CPU 的消耗
缺点:由于申请的内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。brk()方式之所以会产生内存碎片,是由于brk通过移动堆顶的位置来分配内存,并且使用完不会立即归还系统,重复使用,如果高地址的内存不释放,低地址的内存是得不到释放的。
方式二通过 mmap() 系统调用中「私有匿名映射」的方式,在文件映射区分配一块内存,也就是从文件映射区“偷”了一块内存。如下图:
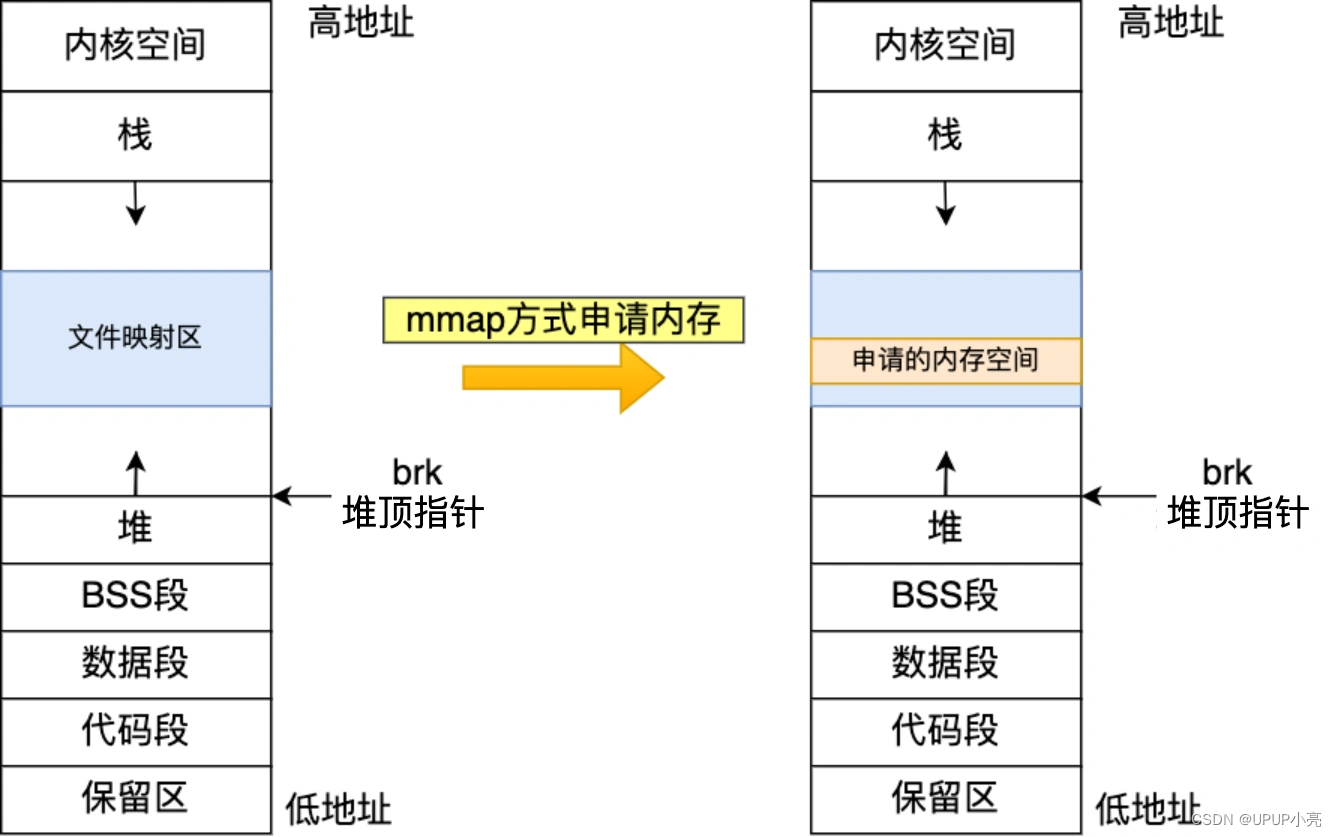
优点
1、对文件的读取操作跨过了页缓存,减少了数据的拷贝次数,用内存读写取代了I/O读写,提高了读取的效率。
2、实现了用户空间和内核空间的高校交互方式,两空间的各自修改操作可以直接反映在映射的区域内,从而被对方空间及时捕捉。
3、提供进程间共享内存及互相通信的方式。不管是父子进程还是无亲缘关系进程,都可以将自身空间用户映射到同一个文件或者匿名映射到同一片区域。从而通过各自映射区域的改动,打到进程间通信和进程间共享的目的。
缺点
申请内存的操作应该避免频繁的系统调用,如果都用 mmap 来分配内存,等于每次都要执行系统调用。
另外,因为 mmap 分配的内存每次释放的时候,都会归还给操作系统,于是每次 mmap 分配的虚拟地址都是缺页状态的,然后在第一次访问该虚拟地址的时候,就会触发缺页中断。
频繁通过 mmap 分配的内存话,不仅每次都会发生运行态的切换,还会发生缺页中断(在第一次访问虚拟地址后),这样会导致 CPU 消耗较大。
三、mmap实现原理
普通读写与mmap对比
在unix/linux平台下读写文件,一般有两种方式。第一种是首先open文件,接着使用read系统调用读取文件的全部或一部分。于是内核将文件的内容从磁盘上读取到内核页高速缓冲(也即pageCache),再从内核高速缓冲读取到用户进程的地址空间。而写的时候,需要将数据从用户进程拷贝到内核高速缓冲,然后在从内核高速缓冲把数据刷到磁盘中,那么完成一次读写就需要在内核和用户空间之间做四次数据拷贝。而且当多个进程同时读取一个文件时,则每一个进程在自己的地址空间都有这个文件的副本,这样也造成了物理内存的浪费
mmap 是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用 read、write 等系统调用函数。
mmap内存映射实现过程
(一)进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域**
1、进程在用户空间调用库函数mmap,原型:void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
2、在当前进程的虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址
3、为此虚拟区分配一个vm_area_struct结构,接着对这个结构的各个域进行了初始化
4、将新建的虚拟区结构(vm_area_struct)插入进程的虚拟地址区域链表或树中
(二)调用内核空间的系统调用函数mmap(不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射关系
5、为映射分配了新的虚拟地址区域后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过文件描述符,链接到内核“已打开文件集”中该文件的文件结构体(struct file),每个文件结构体维护着和这个已打开文件相关各项信息。
6、通过该文件的文件结构体,链接到file_operations模块,调用内核函数mmap,其原型为:int mmap(struct file *filp, struct vm_area_struct *vma),不同于用户空间库函数。
7、内核mmap函数通过虚拟文件系统inode模块定位到文件磁盘物理地址。
8、通过remap_pfn_range函数建立页表,即实现了文件地址和虚拟地址区域的映射关系。此时,这片虚拟地址并没有任何数据关联到主存中。
(三)进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝
注:前两个阶段仅在于创建虚拟区间并完成地址映射,但是并没有将任何文件数据的拷贝至主存。真正的文件读取是当进程发起读或写操作时。
9、进程的读或写操作访问虚拟地址空间这一段映射地址,通过查询页表,发现这一段地址并不在物理页面上。因为目前只建立了地址映射,真正的硬盘数据还没有拷贝到内存中,因此引发缺页异常。
10、缺页异常进行一系列判断,确定无非法操作后,内核发起请求调页过程。
11、调页过程先在交换缓存空间(swap cache)中寻找需要访问的内存页,如果没有则调用nopage函数把所缺的页从磁盘装入到主存中。
12、之后进程即可对这片主存进行读或者写的操作,如果写操作改变了其内容,一定时间后系统会自动回写脏页面到对应磁盘地址,也即完成了写入到文件的过程。
mmap 的适用场景
mmap 的适用场景实际上非常受限,在如下场合下可以选择使用 mmap 机制:
多个线程以只读的方式同时访问一个文件,这是因为 mmap 机制下多线程共享了同一物理内存空间,因此节约了内存。案例:多个进程可能依赖于同一个动态链接库,利用 mmap 可以实现内存仅仅加载一份动态链接库,多个进程共享此动态链接库。
mmap 非常适合用于进程间通信,这是因为对同一文件对应的 mmap 分配的物理内存天然多线程共享,并可以依赖于操作系统的同步原语;
mmap 虽然比 sendfile 等机制多了一次 CPU 全程参与的内存拷贝,但是用户空间与内核空间并不需要数据拷贝,因此在正确使用情况下并不比 sendfile 效率差














 2113
2113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









