






由于本文公式较多,简书不支持公式渲染,完整版已发布在个人博客
存储
DianNao系列的存储的设计理念是分裂存储,这样有几个好处:
- 增大带宽:相同大小的单个存储器和多个存储器相比,多个存储器能提供更大的带宽
- 匹配位宽:有些数据对位宽的需求不同,将位宽需求不同的数据放在不同位宽的存储器中可以避免位宽浪费
DianNao与DaDianNao
DianNao和DaDianNao的存储设计基本相同,区别在于DaDianNao使用了片上eDRAM增大了片上存储的面积,下图为DaDianNao的存储部分,DianNao的存储部分类似,可以参考整体架构中DianNao的架构图:
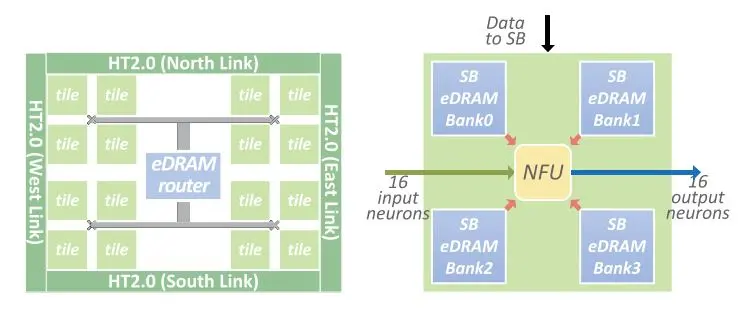
存储被分裂为三个部分:
- NBin:用于存储输入数据,需要位宽$T_n$(一次处理所需的输入数量x每个输入位宽)
- NBout:用于存储部分和与最终运算结果,需要位宽$T_n$
- SB:用于存储权值,需要位宽$T_n \times T_n$
DianNao和DaDianNao的重用策略是重用输入数据即NBin中的数据。当需要NBin参与的运算全部完成后,NBin才会被覆盖。因此,在DaDianNao中,所有运算单元共享eDRAM实现的NBin和NBout(图中eDRAM router部分),但具有自己的SB缓存(每个节点有4个eDRAM)
ShiDianNao
ShiDianNao的存储比较有特色,由于其特殊性,并未采用DaDianNao的eDRAM组成超大片上存储。仅使用了288KB的SRAM,因此其存储组织更值得研究,下图为NBin缓存及其控制器的设计:
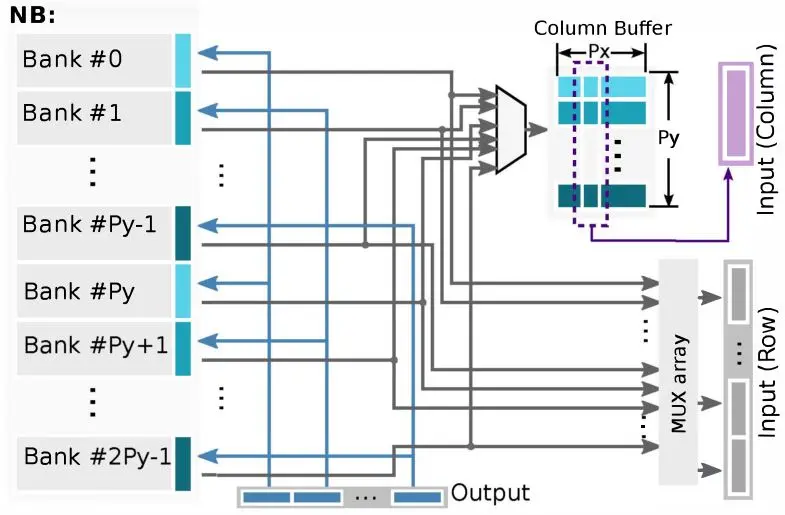
可以发现,每个存储器分裂为$2 \times P_y$个Bank,每个Bank的位宽是$P_x \times 16bit$。其中$P_y$为运算阵列的行数,$P_x$为计算阵列的列数,16bit为数据位宽。该存储器支持的读取方式有6种:
- 读bank0~bank$P_y-1$,共$P_y \times P_x \times 16bit$数据,可以填充计算阵列中每个节点。
- 读bank$P_y$~bank$2 \times P_y-1$,共$P_y \times P_x \times 16bit$数据,可以填充计算阵列中每个节点。
- 读取一个Bank,共$P_x \times 16bit$数据,可以填充计算阵列中的一行。
- 读取一个Bank中的一个数据(16bit)
- 读取每个Bank中指定间隔的数据,共$2 \times P_y \times 16bit$数据。
- 读取bank$P_y$~bank$2 \times P_y-1$中每个Bank中指定位置的数据,共$P_y \times 16bit$数据,可以填充计算阵列中的一列。
写方面,采用缓存-存储的方式,即现先待写入数据换存入output寄存器中,待全部运算单元完成运算后统一将数据从output寄存器中写入存储器。
PuDianNao
PuDianNao抛弃了按用途分裂存储器的方法,改为按重用频率分裂存储器。且其设计方法更贴近通用处理器CPU,以实现通用机器学习处理器。PuDianNao认为其能实现的7种机器学习算法在存储上分为两种:

第一种与k-NN(k-邻近算法)类似,每个数据的重用间隔(这一次使用和下一次使用之间的间隔数据数量)明确的类聚为几类。第二种与NB(朴素贝叶斯)类似,除了位置为1上的明显类聚外,数据重用间隔在一段上均有分布。因此PuDianNao实现三个片上存储,分别为:
- ColdBuffer:16KB,存储重用间隔较长的数据,位宽较小。
- HotBuffer:8KB,存储重用数据较少的数据,位宽较大。
- OutputBuffer:8KB,存储输出数据。
映射方法
映射方法指现有硬件加速器如何实现神经网络中的运算,包括卷积,池化和全连接层等。
DianNao与DaDianNao
由于DianNao和DaDianNao的论文中都没有明确阐述这两款加速器如何映射运算,因此以下内容均为个人推测
DianNao和DaDianNao的运算单元均为NFU,参考其设计,其功能描述如下:
$$
mul: y_i = \sum\limits^{T_n}{i=1} w_i \cdot x_i \
max:y_i = max{x_1,x_2,...,x{T_n}}
$$
向量内积与卷积
无论是向量内积还是卷积,其最终都是对应位置元素相乘再相加。都可以使用运算核心的MUL功能解决,即将NFU-2配置为加法树。在存储中,输入数据按[高度,宽度,通道数]维度排列,即先存储第一个数据位置的所有通道数据,再存储第二个数据位置的所有通道数据,以此类推。权值数据按[高度,宽度,输出通道数,输入通道数]排列。其实现图如下所示:

上图为一个$T_n = 2$的例子,其中数据含义如下所示:
| 标记 | 来源 | 说明 |
|---|---|---|
| X000 | 输入数据 | 数据位置(0,0),通道0数据 |
| X001 | 输入数据 | 数据位置(0,0),通道1数据 |
| W0000 | 参数 | 数据位置(0,0),通道0数据对应输出通道0的参数 |
| W0001 | 参数 | 数据位置(0,0),通道1数据对应输出通道0的参数 |
| W0010 | 参数 | 数据位置(0,0),通道0数据对应输出通道1的参数 |
| W0011 | 参数 | 数据位置(0,0),通道1数据对应输出通道1的参数 |
其实现的运算在卷积中如下所示:

池化
实现池化层时,输入数据按[通道数,高度,宽度]排列,NFU-2被配置为取最大值树。
ShiDianNao
ShiDianNao由阵列实现卷积,池化,向量内积等操作,映射比较复杂。以下说明均使用$P_x=P_y=2$
卷积
ShiDianNao的每个节点的简化图形如下所示,以下说明将使用该图示:

实现卷积的第一步是初始化,将数据读入运算阵列,使用缓存读方式1或2:

随后读Bank2和Bank3的第一个神经元,将其填充到运算阵列的右侧,同时输入数据右移,这等效的是标记参与运算的数据框向右扩展:

之后读Bank2和Bank3的第二个神经元,将其填充到运算阵列右侧,同时输入数据右移,这等效的是标记参与运算的数据框向右扩展:

随后读Bank1的两个神经元,将其填充到底部,同时数据上移,这等效标记参与运算的数据框向下扩展:

下表表示了每一个运算节点使用过的权值和数据:
| 坐标 | 参数=K00 | 参数=K10 | 参数=K20 | 参数=K01 |
|---|---|---|---|---|
| 0,0(左上) | X00 | X10 | X20 | X01 |
| 0,1(右上) | X10 | X20 | X30 | X11 |
| 1,0(左下) | X01 | X11 | X21 | X02 |
| 1,1(右下) | X11 | X21 | X31 | X12 |
注意上文中运算单元和SB的行为为原文中注明的,存储器行为为个人推断,此外,原文中的推断到此为止,理由为保持简洁,然而下一步的操作使用以上几步无法完全推测,原文中说明该复用方法可以节约44.4%的带宽,有$4 \times 9 \times 44.4% = 16$,所以一共读了20次,图像中有16个数据,推测就是中心处被复用最多次的X11,X21,X12和X22。该部分说明的原图如下图所示:

池化
池化的映射方法与卷积类似,且由于池化的Stride一般不为1,因此需要注意的是FIFO-H和FIFO-V的深度不再是1。其中$S_x$和$S_y$分别是X方向和Y方向的Stride。
全连接层
矩阵乘法中,每个计算节点代表一个输出神经元,除非一个输出神经元的计算全部完成,否则不会进行下一个神经元的运算。与卷积不同的是,被广播的数据是输入数据而不是权值。因为在矩阵乘运算中,权值的数量多于数据且不被复用。每次运算分为以下几个步骤:
- 一个输入数据和$P_x \times P_y$个权值,每个计算节点接收一个数据和被广播的数据。
- 计算节点将输入数据和权值相乘后与之前的部分和积累。
- 当一个输出神经元的所有计算都完成后,将每个节点累积的结果缓存回片上存储中。
PuDianNao
PuDianNao的映射方法比较简单,由于较多的考虑了灵活性,因此使用类似软件的方式控制整个芯片。推测方法为:
- 控制模块控制DMA将指定数据从片外存储搬运到片上buufer中,并将其搬运到指定处理单元中
- 处理单元在控制模块控制下对数据进行处理
- DMA将结果从处理单元单元搬运到buffer中















 1586
1586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









