






本文将介绍如何利用已有的数据集训练lstm网络实现多变量时序预测模型,以此来检测GNSS欺骗攻击。我们使用了来自 Comma.ai 的真实数据集,名为 Comma2k19,其中包含各种自动驾驶车辆传感器数据。该数据集的下载和处理过程请参考我的另一篇文章comma2k19数据集使用。
1.数据准备
Comma.ai 使用的视听设备有一个前置摄像头、温度计和9轴惯性测量单元。除了这些传感器数据,Comma2k19 数据集还包含来自全球导航卫星系统(GNSS)和控制区域网络(CAN)的测量值(见表 1 和表 2)。数据收集使用了可跟踪全球导航卫星系统的 u-blox M8 全球导航卫星系统模块,水平位置精度为 2.5 米。位置测量使用了全球定位系统(GPS)和全球轨道导航卫星系统(GLONASS)信号。此外,使用开源的GNSS处理库 Laika 来减少定位误差,定位误差降低了 40%。
在这里我们选择部分数据用于接下来的模型中:
- GNSS数据集包含来自 u-blox 和 Qcom 的实时和原始导航卫星系统数据。每个实时数据包括纬度、经度、速度、utc 时间戳、高度和方位角数据。但它们都是未被Laika优化的数据,为了得到更好的效果,我们采用
global_pose文件夹中的frame_position、frame_gps_times和frame_velocities的数据,后续可看情况加入frame_orientations数据。综合起来用于训练的GNSS数据有时间,经纬度(高度可不考虑)和速度,如下表所示:

其中global_pose\frame_position中的坐标是ECEF的(x, y, z),须将其转化为GPS常用的经纬度坐标(wgs845),Python代码实现如下:
import pyproj
transformer = pyproj.Transformer.from_crs(
{"proj":'geocent', "ellps":'WGS84', "datum":'WGS84'},
{"proj":'latlong', "ellps":'WGS84', "datum":'WGS84'},
)
lon, lat, alt = transformer.transform(x,y,z,radians=False)
print (lat1, lon1, alt1 )
要注意返回的经纬度顺序是Longitude在前,与常规有所区别。
- 相关的CAN数据是CAN时间,车速和方向盘转角数据(见表2),可分别从
processed_log/CAN/speed/t、processed_log/CAN/speed/value和processed_log/CAN/steering_angle/value读取, 样例如下表所示。

- 同样,相关的IMU数据是三个方向的加速度,可分别从processed_log/IMU/accelerometer/t和processed_log/IMU/accelerometer/value中读取,样例如下表所示。

时间处理
值得注意的是,用于分析的数据集包含7200个GNSS观测值、35726个CAN观测值和72148个IMU观测值,GNSS、CAN和IMU数据的频率分别为10、50和100赫兹。这意味着不同数据源的时间是有略微不同的,在本项目中GNSS时间被用作参考时间,所有其他传感器数据被同步,以便为LSTM模型准备训练和测试数据集。为了在作为参考时间的准确时间获得CAN和IMU的数据,在GNSS的两个最近观测值之间要对CAN和IMU进行插值,在这里我采用scipy的样条插值方法,Python代码实现如下:
from scipy.interpolate import make_interp_spline
CAN_time = np.load(example_segment + 'processed_log/CAN/speed/t')
gps_time = np.load(example_segment + 'global_pose/frame_times')
# 对CAN的速度进行插值
CAN_speed = np.load(example_segment + 'processed_log/CAN/speed/value')
new_CAN_speed = make_interp_spline(CAN_time, CAN_speed)(gps_time)
plt.figure(figsize=(12, 12))
plt.plot(CAN_time, CAN_speed, label='CAN')
plt.plot(gps_time, new_CAN_speed, label='new_CAN')
plt.legend(fontsize=25)
plt.xlabel('boot time (s)', fontsize=18)
plt.ylabel('speed (m/s)', fontsize=18)
plt.show()

当处理时间数据的时候我发现它们存在一些小瑕疵,有重复值,而且即使是同样来自CAN的数据,speed的时间和steering_angle的时间也是不一致的,这意味着它们要分别读取,分别插值。Python代码实现:
# 数组去重
def unique(old_list):
newList = []
# 判断相邻时间是否相等
if np.any(old_list[1:] == old_list[:-1]):
for x in old_list:
if x in newList:
# 若相等,则加上一个微小的数使其不等
x = x + 0.005
newList.append(x)
return np.array(newList)
else: return old_list
temp_CAN_times = np.load(main_dir + '\\processed_log\\CAN\\speed\\t')
# 确保时间无重复值
temp_CAN_speed_times = unique(temp_CAN_times)
# CAN_angles_times和CAN_speed_times有时不一致
temp_CAN_angles_times = np.load(main_dir + '\\processed_log\\CAN\\steering_angle\\t')
temp_CAN_angles_times = unique(temp_CAN_angles_times)
temp_IMU_times = np.load(main_dir + '\\processed_log\\IMU\\accelerometer\\t')
距离计算
当我们预测自动驾驶车辆当前位置和最近未来位置之间的行驶距离时,从上一个时间步长开始的每个时间步长中的行驶距离是使用纬度和经度坐标以及以下哈弗辛大圆公式计算的:
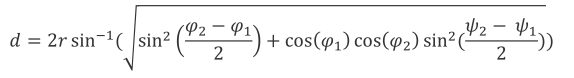
Python实现如下:
import math
EARTH_REDIUS = 6378.137
def rad(d):
return d * math.pi / 180.0
def getDistance(lats1, lngs1, lats2, lngs2):
# 对数组取元素做运算
res = []
for i in range(len(lat1)):
radLat1 = rad(lat1[i])
radLat2 = rad(lat2[i])
a = radLat1 - radLat2
b = rad(lng1[i]) - rad(lng2[i])
s = 2 * math.asin(math.sqrt(math.pow(math.sin(a / 2), 2) + math.cos(radLat1) * math.cos(radLat2) * math.pow(
math.sin(b / 2), 2)))
s = s * EARTH_REDIUS * 1000
res.append(s)
return res
# 计算距离
distance = getDistance(lats1, lngs1, lats2, lngs2)
plt.plot(times[:-1], distance, label='distance')
plt.title('Traveled distance between two consecutive timestamps', fontsize=20);
plt.legend(fontsize=20);
plt.xlabel('boot time (s)', fontsize=18);
plt.ylabel('distance(m) ', fontsize=18);
plt.show()

与速度图相比较,可以发现形状相似,说明计算无误。

对一个segment的distance绘图没有问题,但如果对一个route的多个segment一个绘图就会发现存在异常值,如下图所示:

异常值使得曲线非常不光滑

蓝色框中的数据和周边数据明显不同,对于这个问题我咨询comma.ai得到的解释是每个segment的数据是分别优化的,并不保证segment之间坐标的连续性,所以每跨一个段时(60s),就会出现这样的异常值。由于这些异常值占比极小,可忽略不计。
合并数据集
对比GNSS的速度与CAN的速度我们会发现存在偏差,考虑到CAN速度会比GNSS速度更能反映实际情况,故只采用CAN的速度,我们使用LSTM模型来预测每个时间戳的当前位置和最近的未来位置之间的距离,使用无攻击的CAN、IMU和GNSS数据。在本文中,我们使用的LSTM模型由一个输入层、一个具有50个神经元的递归隐藏层和一个输出层组成。训练LSTM模型的输入数据包括来自控制器局域网的速度和转向角数据以及来自惯性测量单元的前向加速度数据。输出是每个时间戳当前位置和最近未来位置之间的距离。
在训练数据规模上我们有考量,每个chunk之间甚至同一个chunk内不同route的数据都是不相关的,他们之间的不连续性使得它们没法反映真实情况,所幸同一个route之间的segments是基本连续的,我们将训练范围缩小至一个route文件夹的数据,如果用其他场景丰富且时间连续的数据集训练效果会更好,读取数据的代码实现如下:
dataset_directory = 'D:\comma2k19'
chunk_set = []
for chunk in os.listdir(dataset_directory):
# 忽略生成的csv文件
if ".csv" in chunk:
continue
# 如果序号为单个时在前补零,以便后面排序
if len(chunk) == 7:
used_name = chunk
chunk = str_insert(chunk,6,'0')
os.rename(os.path.join(dataset_directory, used_name), os.path.join(dataset_directory, chunk))
chunk_set.append(os.path.join(dataset_directory, chunk))
# 将序号小的片段放在前面
chunk_set.sort()
# 选一个chunk来训练(200分钟)
chunk_index = 0
route_set = []
for route_id in os.listdir(chunk_set[chunk_index]):
# 忽略生成的csv文件
if ".csv" in route_id:
continue
route_set.append(os.path.join(chunk_set[chunk_index], route_id))
segment_set = []
# 选一个路段训练
route_index = 9
for segment in os.listdir(route_set[route_index]):
# 如果序号为单个时在前补零,以便后面排序
if len(segment) == 1:
used_name = segment
segment = '0'+segment
os.rename(os.path.join(route_set[route_index], used_name),os.path.join(route_set[route_index], segment))
segment_set.append(os.path.join(route_set[route_index], segment))
# 将序号小的片段放在前面
segment_set.sort()
times = []
lons = []
lats = []
orientations = []
CAN_speeds = []
steering_angles = []
acceleration_forward = []
for main_dir in segment_set:
# 导入GNSS的时间和位置(pose)并将位置转化为经纬度
temp_GNSS_time = np.load(main_dir + '\\global_pose\\frame_times')
times = np.append(times, temp_GNSS_time)
# 打印每一段的长度
print(len(temp_GNSS_time))
positions = np.load(main_dir + '\\global_pose\\frame_positions')
positions = position_transformer.transform(positions[:, 0], positions[:, 1], positions[:, 2], radians=False)
lats = np.append(lats, positions[1])
lons = np.append(lons, positions[0])
temp_CAN_times = np.load(main_dir + '\\processed_log\\CAN\\speed\\t')
# 确保时间无重复值
temp_CAN_speed_times = unique(temp_CAN_times)
# 对CAN数据按照GNSS参考时间插值
temp_CAN_speeds = make_interp_spline(temp_CAN_speed_times, np.load(main_dir + '\\processed_log\\CAN\\speed\\value'))(temp_GNSS_time).flatten()
CAN_speeds = np.append(CAN_speeds, temp_CAN_speeds)
# CAN_angles_times和CAN_speed_times有时不一致
temp_CAN_angles_times = np.load(main_dir + '\\processed_log\\CAN\\steering_angle\\t')
temp_steering_angles = np.load(main_dir + '\\processed_log\\CAN\\steering_angle\\value')
temp_CAN_angles_times = unique(temp_CAN_angles_times)
temp_steering_angles = make_interp_spline(temp_CAN_angles_times, temp_steering_angles)(temp_GNSS_time)
steering_angles = np.append(steering_angles, temp_steering_angles)
# 对IMU数据按照GNSS参考时间插值
temp_IMU_times = np.load(main_dir + '\\processed_log\\IMU\\accelerometer\\t')
temp_acceleration_forward = make_interp_spline(temp_IMU_times, np.load(main_dir +
'\\processed_log\\IMU\\accelerometer\\value')[:, 0])(temp_GNSS_time)
acceleration_forward = np.append(acceleration_forward, temp_acceleration_forward)
转化为监督学习问题
该问题本质是监督学习问题,当前是时刻的速度,转角和前向加速度是feature,下一时刻位置离当前时刻位置的距离将作为标签,更多有关时序数据预测问题转化为监督学习,参考https://blog.csdn.net/qq_28031525/article/details/79046718
Python代码实现如下:
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = pd.DataFrame(data)
column_names = ['lats', 'lons', 'CAN_speeds', 'steering_angles', 'acceleration_forward']
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('%s(t-%d)' % (j, i)) for j in column_names]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('%s(t)' % (j)) for j in column_names]
else:
names += [('%s(t+%d)' % (j, i)) for j in column_names]
# put it all together
agg = pd.concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
DataSet = list(zip(times, lats, lons, CAN_speeds, steering_angles, acceleration_forward))
column_names = ['times', 'lats', 'lons', 'CAN_speeds', 'steering_angles', 'acceleration_forward']
df = pd.DataFrame(data=DataSet, columns=column_names)
times = df['times'].values
df = df.set_index(['times'], drop=True)
values = df.values.astype('float64')
# 转为监督学习问题, 其实就是将下一时刻的特征(distance)作为当前时刻的标签
reframed = series_to_supervised(values, 1, 1)
# 计算距离
lons_t = reframed['lons(t)'].values
lats_t = reframed['lats(t)'].values
distance = np.array(getDistance(lats[:-1], lons[:-1], lats_t, lons_t))
# drop columns we don't want to predict including(CAN_speed,steering_angel, acceleration_forward)
reframed.drop(reframed.columns[[0, 1, 5, 6, 7, 8, 9]], axis=1, inplace=True)
# 时间和计算的距离添加到数据集
reframed['distance'] = distance
reframed['times'] = times[: -1]
# for i in distance:
# if i > 100:
# print(i)
plt.plot(times[:-1], distance)
plt.xlabel('Boot time (s)', fontsize=18)
plt.ylabel('Distance travelled during single timestamp (m) ', fontsize=12)
plt.show()
# 将合并的数据保存为.csv文件
reframed.to_csv(route_set[route_index]+".csv", index=False, sep=',')
data_prepare完整代码:
这部分工作可以让我们在指定的范围内提取我们想要的数据,生成可供读写的.csv文件,可供训练和测试阶段直接利用。数据准备的完整实现代码如下:
import os
import numpy as np
import pandas as pd
import pyproj
from scipy.interpolate import make_interp_spline
import math
import matplotlib.pyplot as plt
# 在字符串指定位置的插入字符
def str_insert(str_origin, pos, str_add):
str_list = list(str_origin) # 字符串转list
str_list.insert(pos, str_add) # 在指定位置插入字符串
str_out = ''.join(str_list) # 空字符连接
return str_out
# 数组去重
def unique(old_list):
newList = []
# 判断相邻时间是否相等
if np.any(old_list[1:] == old_list[:-1]):
for x in old_list:
if x in newList:
# 若相等,则加上一个微小的数使其不等
x = x + 0.005
newList.append(x)
return np.array(newList)
else: return old_list
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = pd.DataFrame(data)
column_names = ['lats', 'lons', 'CAN_speeds', 'steering_angles', 'acceleration_forward']
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('%s(t-%d)' % (j, i)) for j in column_names]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('%s(t)' % (j)) for j in column_names]
else:
names += [('%s(t+%d)' % (j, i)) for j in column_names]
# put it all together
agg = pd.concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
EARTH_REDIUS = 6378.137
def rad(d):
return d * math.pi / 180.0
def getDistance(lat1, lng1, lat2, lng2):
# 对数组取元素做运算
res = []
for i in range(len(lat1)):
radLat1 = rad(lat1[i])
radLat2 = rad(lat2[i])
a = radLat1 - radLat2
b = rad(lng1[i]) - rad(lng2[i])
s = 2 * math.asin(math.sqrt(math.pow(math.sin(a / 2), 2) + math.cos(radLat1) * math.cos(radLat2) * math.pow(
math.sin(b / 2), 2)))
s = s * EARTH_REDIUS * 1000
res.append(s)
return res
if __name__ == '__main__':
# 用于GNSS坐标转化
position_transformer = pyproj.Transformer.from_crs(
{"proj": 'geocent', "ellps": 'WGS84', "datum": 'WGS84'},
{"proj": 'latlong', "ellps": 'WGS84', "datum": 'WGS84'},
)
dataset_directory = 'D:\comma2k19'
chunk_set = []
for chunk in os.listdir(dataset_directory):
# 忽略生成的csv文件
if ".csv" in chunk:
continue
# 如果序号为单个时在前补零,以便后面排序
if len(chunk) == 7:
used_name = chunk
chunk = str_insert(chunk,6,'0')
os.rename(os.path.join(dataset_directory, used_name), os.path.join(dataset_directory, chunk))
chunk_set.append(os.path.join(dataset_directory, chunk))
# 将序号小的片段放在前面
chunk_set.sort()
# 选一个chunk来训练(200分钟)
chunk_index = 0
route_set = []
for route_id in os.listdir(chunk_set[chunk_index]):
# 忽略生成的csv文件
if ".csv" in route_id:
continue
route_set.append(os.path.join(chunk_set[chunk_index], route_id))
segment_set = []
# 选一个路段训练
route_index = 9
for segment in os.listdir(route_set[route_index]):
# 如果序号为单个时在前补零,以便后面排序
if len(segment) == 1:
used_name = segment
segment = '0'+segment
os.rename(os.path.join(route_set[route_index], used_name),os.path.join(route_set[route_index], segment))
segment_set.append(os.path.join(route_set[route_index], segment))
# 将序号小的片段放在前面
segment_set.sort()
times = []
lons = []
lats = []
orientations = []
CAN_speeds = []
steering_angles = []
acceleration_forward = []
for main_dir in segment_set:
# 导入GNSS的时间和位置(pose)并将位置转化为经纬度
temp_GNSS_time = np.load(main_dir + '\\global_pose\\frame_times')
times = np.append(times, temp_GNSS_time)
# 打印每一段的长度
print(len(temp_GNSS_time))
positions = np.load(main_dir + '\\global_pose\\frame_positions')
positions = position_transformer.transform(positions[:, 0], positions[:, 1], positions[:, 2], radians=False)
lats = np.append(lats, positions[1])
lons = np.append(lons, positions[0])
temp_CAN_times = np.load(main_dir + '\\processed_log\\CAN\\speed\\t')
# 确保时间无重复值
temp_CAN_speed_times = unique(temp_CAN_times)
# 对CAN数据按照GNSS参考时间插值
temp_CAN_speeds = make_interp_spline(temp_CAN_speed_times, np.load(main_dir + '\\processed_log\\CAN\\speed\\value'))(temp_GNSS_time).flatten()
CAN_speeds = np.append(CAN_speeds, temp_CAN_speeds)
# CAN_angles_times和CAN_speed_times有时不一致
temp_CAN_angles_times = np.load(main_dir + '\\processed_log\\CAN\\steering_angle\\t')
temp_steering_angles = np.load(main_dir + '\\processed_log\\CAN\\steering_angle\\value')
temp_CAN_angles_times = unique(temp_CAN_angles_times)
temp_steering_angles = make_interp_spline(temp_CAN_angles_times, temp_steering_angles)(temp_GNSS_time)
steering_angles = np.append(steering_angles, temp_steering_angles)
# 对IMU数据按照GNSS参考时间插值
temp_IMU_times = np.load(main_dir + '\\processed_log\\IMU\\accelerometer\\t')
temp_acceleration_forward = make_interp_spline(temp_IMU_times, np.load(main_dir +
'\\processed_log\\IMU\\accelerometer\\value')[:, 0])(temp_GNSS_time)
acceleration_forward = np.append(acceleration_forward, temp_acceleration_forward)
DataSet = list(zip(times, lats, lons, CAN_speeds, steering_angles, acceleration_forward))
column_names = ['times', 'lats', 'lons', 'CAN_speeds', 'steering_angles', 'acceleration_forward']
df = pd.DataFrame(data=DataSet, columns=column_names)
times = df['times'].values
df = df.set_index(['times'], drop=True)
values = df.values.astype('float64')
# 转为监督学习问题
reframed = series_to_supervised(values, 1, 1)
# 计算距离
lons_t = reframed['lons(t)'].values
lats_t = reframed['lats(t)'].values
distance = np.array(getDistance(lats[:-1], lons[:-1], lats_t, lons_t))
# drop columns we don't want to predict including(CAN_speed,steering_angel, acceleration_forward)
reframed.drop(reframed.columns[[0, 1, 5, 6, 7, 8, 9]], axis=1, inplace=True)
# 时间和计算的距离添加到数据集
reframed['distance'] = distance
reframed['times'] = times[: -1]
plt.plot(times[:-1], distance)
plt.xlabel('Boot time (s)', fontsize=18)
plt.ylabel('Distance travelled during single timestamp (m) ', fontsize=12)
plt.show()
# 将合并的数据保存为.csv文件
reframed.to_csv(route_set[route_index]+".csv", index=False, sep=',')
模型训练和评估
读取数据
首先你需要任意选择两个route文件夹的数据分别做训练集合测试集,这可以通过data_prepare.py完成,接下来就是将他们分别读进来,并做一些处理,其中归一化可以提升训练效果和收敛速度,示例代码如下:
train_CSV_FILE_PATH = 'D:\\comma2k19\\Chunk_01\\b0c9d2329ad1606b_2018-08-02--08-34-47.csv'
test_CSV_FILE_PATH = 'D:\\comma2k19\\Chunk_01\\b0c9d2329ad1606b_2018-08-01--21-13-49.csv'
train_df = pd.read_csv(train_CSV_FILE_PATH)
test_df = pd.read_csv(test_CSV_FILE_PATH)
train_values = train_df.to_numpy()
train_times = train_values[:, -1]
train_distance = train_values[:, -2]
test_values = test_df.to_numpy()
test_times = test_values[:, -1]
test_distance = test_values[:, -2]
# 将输入特征归一化
scaler = MinMaxScaler(feature_range=(0, 1))
train_X, train_y = scaler.fit_transform(train_values[:, :-2]), train_distance
test_X, test_y = scaler.fit_transform(test_values[:, :-2]), test_distance
设计网络并训练
我们直接使用keras的lstm模块来建立网络模型,请确保你已搭建好相应环境。
现在可以搭建LSTM模型了。LSTM模型中,隐藏层有50个神经元,输出层1个神经元(回归问题),输入变量是一个时间步(t-1)的特征,损失函数采用Mean Absolute Error(MAE),优化算法采用Adam。
# 设计网络
model = Sequential()
model.add(LSTM(50, input_shape=(train_X.shape[1], train_X.shape[2])))
model.add(Dense(1))
# 设置学习率等参数
# adam = optimizers.Adam(lr=0.01, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model.compile(loss='mae', optimizer='adam')
# fit network
history = model.fit(train_X, train_y, epochs=500, batch_size=1200, validation_data=(test_X, test_y), verbose=2,
shuffle=False)
model.save('lstm.model')
# full_X = values[:, :3]
# full_X = full_X.reshape((full_X.shape[0], 1, full_X.shape[1]))
train_yhat = model.predict(train_X)[:, 0]
test_yhat = model.predict(test_X)[:, 0]
rmse = math.sqrt(mean_squared_error(test_yhat, test_y))
print('Test RMSE: %.3f' % rmse)
# plot history
plt.plot(history.history['loss'], label='train')
plt.plot(history.history['val_loss'], label='test')
plt.legend()
plt.show()
学习率可以通过optimizer来设置,adam默认为0.01,其他超参数可参考表4:

评估的python代码如下:
import pandas as pd
import math
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.preprocessing import MinMaxScaler
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
def average(seq, total=0.0):
num = 0
for item in seq:
total += item
num += 1
return total / num
if __name__ == '__main__':
CSV_FILE_PATH = 'D:\\comma2k19\\Chunk_03\\99c94dc769b5d96e_2018-05-01--08-13-53.csv'
df = pd.read_csv(CSV_FILE_PATH)
values = df.to_numpy()
times = values[:, -1]
distance = values[:, -2]
model = tf.keras.models.load_model('lstm.model')
test_X = values[:, :3]
# 因为训练的时候输入特征是归一化的,所以预测的时候也要将输入特征归一化
scaler = MinMaxScaler(feature_range=(0, 1))
test_X = scaler.fit_transform(test_X)
test_X = test_X.reshape((test_X.shape[0], 1, test_X.shape[1]))
# train_len = (int)(0.75 * len(values[:, 0]))
# train = values[:train_len, :]
# test = values[train_len:, :]
test_y = distance
yhat = model.predict(test_X)[:, 0]
rmse = math.sqrt(mean_squared_error(yhat, test_y))
print('Test RMSE: %.3f' % rmse)
scores = model.evaluate(test_X, test_y)
rmse = math.sqrt(mean_squared_error(yhat, test_y))
plt.plot(times, yhat, label='prediction')
plt.plot(times, distance, label="ground_truth")
plt.title('Comparison between truth and prediction', fontsize=18)
plt.xlabel('Boot time (s)', fontsize=18)
plt.ylabel('Distance travelled during single timestamp (m) ', fontsize=12)
plt.legend()
plt.show()
min = min((distance - yhat), key=abs)
max = max((distance - yhat), key=abs)
avr = average(distance-yhat)
print('Min:%f' % min)
print('Max:%f' % max)
print('average:%f' % avr)
使用其他epoch和batch_size训练
我令训练集和测试集分别取自不同的route,来看训练情况是否更好
- 当batch_size = 50 epoch = 100时,训练时loss在epoch = 50左右就不动了


测试集上的预测效果如下:


重新挑选一个route进行预测,可以看出预测效果还是不错的,误差绝对值的最大最小和平均值分别如下:


- 由于每一段数据基本都由1200个数据组成,所以我想令batch_size = 1200,这样分段训练,每训练一个segment才调整梯度,于是我令
batch_size = 1200 epoch = 300,发现训练速度很快,误差也不算太大。




说明batch_size = 1200 epoch = 300训练效果更好,用非测试集去做预测评估,大部分的误差都不大


误差的最大最小和平均值分别如下:

这可能是训练集太小导致的,训练集只有10分钟,不足以包含所有情况。模型本身很好,但需要寻找更好的数据集来进行训练。
完整代码已上传到Github















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









