







BiDAF-用于机器理解的双向注意力流
目录

摘要
机器理解(MC),回答关于给定文本段落的查询,要求对文本和查询之间的复杂交互进行建模。目前的方法都使用单向注意力。
本文提出了双向注意力流网络。是个多级的分层结构。在多个不同层面的粒度上表示文本。without early summarization。在SQuAD数据集和CNN/DailyMail完形填空数据集上取得了目前最好的效果。
1 介绍
取得进步的重要因素之一是神经注意力机制的使用,使得系统能够在文本段落中(用于MC)/或者在图像中(用于视觉QA)专注于目标区域。这对于回答问题来说,是最有关的。
之前的工作中,注意力机制有以下几个特征:
- 计算过的注意力权值被用来从上下文中提取最相关的信息,概括上下文到一个定长的向量中。
- 在文本中,注意力机制经常是暂时的动态,当前时刻的注意力权值是之前时刻的attended向量的函数。
- 通常是单向的。
本文介绍了双向注意力流网络,一种多层分级结构,在不同层级的粒度上给文本段落表征来建模。
BiDAF包括字符级别,单词级别,上下文嵌入,( character-level, word-level, and contextual embeddings),使用双向注意力流获得query-aware文本表示。
BiDAF和之前流行的注意力范式(paradigm)相比,在以下几个方面有所提高:
- 注意力层不被用来概括上下文段落到一个定长的向量中。每个时间步都计算注意力,每个时间步的attended向量,和前一层的表征(representations),都允许流向(flow through)随后的建模层(modeling layer)。这降低了由早期概括引起的信息损失。
- 使用memory-loss注意力机制。当通过时间迭代地计算注意力时,每个时间步的注意力只是当前时间步的查询和文本段落的函数,并不直接取决于之前时间步的注意力。
将注意力层和建模层的功能分开,让注意力层专注于学习查询和文本之间的注意力,让建模曾专注于学习query-aware文本表征的交互(即注意力层的输出)。这让每个时间步的注意力,不会被之前时间步的错误信息影响。
本文实验表明,memory-less注意力比动态注意力更好。 - 使用双向注意力,query-to-context and context-to-query,为彼此提供互补的信息。
2 模型
包括六层:
- 字符嵌入层:将每个单词映射(map)到一个向量空间,使用字符级别的卷积神经网络CNN。
- 单词嵌入层:将每个单词映射到一个向量空间,使用预训练单词嵌入模型。
- 文本嵌入层:使用从附近的的单词中获得的上下文线索,优化单词的嵌入。
以上三层用于查询和文本。 - 注意力流层:将查询向量和文本向量结合,为文中每个单词产生一组query-aware特征向量。
- 建模层:使用循环神经网络RNN扫描文本。
- 输出层:给出查询的答案。

2.1 字符嵌入层
映射每个单词到一个高维的向量空间。
{X1, X2,…, Xt}表示输入的文本。
{Q1, Q2,…, Qj}表示输入的查询。
使用CNN获得每个单词的字符嵌入。字符嵌入为向量,可以看作CNN的一维输入,向量的size就是CNN的输入channel size。
CNN的输出在整个宽度上经过最大池化操作后,获得每个单词的定长向量。
2.2 单词嵌入层
该层也映射每个单词到一个高维向量空间。
使用预训练的词向量来获得每个单词的固定的词嵌入。
字符和单词嵌入向量的连接,传递给一个两层的网络。该网络的输出是d维向量的两个序列,或者说是两个矩阵:文本X(d x T)和查询Q(d x J)
2.3 文本嵌入层
在之前的嵌入之上,使用LSTM来给单词之间的短暂交互建模。使用双向LSTM,并连接两个方向LSTM的输出。从文本词向量X(d x T)中得到H(2d x T),从查询词向量Q(d x J)中得到U(2d x J)。
H和U中的2d维度,是由于连接了LSTM的正向和反向输出,每个方向都有一个d维的输出。
模型的前三层,都是用来从查询和文本中,在不同层级的粒度上,计算特征。类似(akin to)计算机视觉领域中,卷积神经网络CNN中的多级特征计算。
2.4 注意力流层
该层从文本和查询单词中连接、融合信息。
和之前的注意力机制不同,并不会把查询和文本概括成单独的特征向量。相反,每个时间步的注意力向量,和前几层的嵌入,都流入随后的建模层。降低了由早期概括引起的信息丢失。
该层的输入是文本H和查询U的上下文向量表征。
该层的输出是文本单词的query-aware向量表征 G ,和前几层的上下文嵌入。
在该层,计算两个方向的注意力:context-2-query和query-2-context。这些注意力,源自一个共享相似度矩阵 S(T x J),在文本 H 和查询 U 之间的上下文嵌入中,Stj 代表第 t 个文本单词和第 j 个查询单词之间的相似度。矩阵 S 按该式计算:
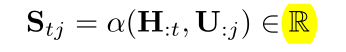
α 是一个可训练标量函数,计算两个输入向量之间的相似度。

C2Q Attention
计算查询中哪个单词和每个文本单词最相关。
知识盲区:softmax()是什么?
Q2C Attention
计算文本中哪个单词和每个查询单词最相似。
2.5 建模层
该层的输入是 G ,编码了文本单词的query-aware表征。
该层的输出获取了由查询决定的文本单词交互。这和文本嵌入层不同,文本嵌入层获取的文本单词交互和查询无关。
使用两层的双向LSTM网络,每个方向的输出size是 d 。得到矩阵 M(2d x T),将其传入输出层来预测答案。
矩阵 M 的每一个列向量包含关于全文和查询的单词的上下文信息。
2.6 输出层
该层是根据应用专用的。BiDAF的模块化性质(modular nature)使得我们可以轻松地根据任务改变输出层,因为其他层几乎都是一样的。
以QA任务为例描述输出层。
QA任务要求找到段落中的子短语来回答查询。该子短语通过预测段落中短语的开始和结束位置来得到。通过下式得到开始位置的概率分布:
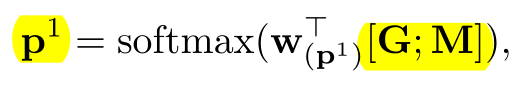
通过下式得到结束位置的概率分布:
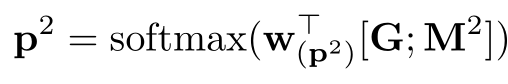
训练过程:
定义loss函数:
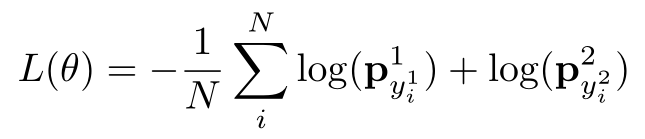
测试过程:
答案区域(k, l),其中k<l,并且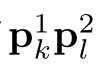 的值最大,则为答案。
的值最大,则为答案。
这可以通过动态规划(dynamic programming)在线性时间内求解。
3 相关工作
机器理解MC
可视化问答VQA
4 问答实验
数据集:SQuAD,基于维基百科的大型数据集,包含十万多条问题。问题的答案通常是文本中的一部分。
衡量模型的两条准则:完全匹配(EM),F1。衡量准确率的加权平均和字符级别的召回率。
5 完形填空实验
相关笔记
https://zhuanlan.zhihu.com/p/93543804
这一篇有一张详细的流程框架图,可以帮助理解
https://zhuanlan.zhihu.com/p/53470020
https://blog.csdn.net/ljp1919/article/details/89101850
https://www.jiqizhixin.com/articles/2019-10-09














 937
937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









