








Bidirectional Attention Flow for Machine Comprehension
Abstract
机器阅读理解MC,即根据上下文段落回答问题,要求对上下文和问题之前的复杂交互进行建模。最近,注意力机制成功应用在MC上,特别是这些模型使用attention对context的部分内容进行专注,并归纳成特定大小的向量。本文引入BiDAF(双线注意力流网络),这是一个多阶段的多层次的处理过程,它以不同的粒度级别分别表示上下文,并使用双向注意力流机制获得query-aware context表示。
1.Instruction
机器阅读理解在最近几年取得了令人振奋的结果,进步的关键因素之一是神经注意机制的 使用,这使系统能够在上下文段落或图像内聚焦于与回答问题最相关的目标区域。
在以前的研究中,注意机制通常具有以下一个或多个特征。
-
首先,计算的注意力权重通常被用来通过将上下文总结为固定大小的向量,一次来从上下文中提取最相关的信息来回答问题。
-
其次,在文本领域中,注意力通常是时间动态的,由此当前时间步长的关注权重是前一时间步长的关注向量的函数。
-
它们通常是单向的,其中query关注上下文段落或图像。
本文的注意力网络,是一个分层的多阶段体系结构,用于在不同的粒度级别上对上下文段落的表示进行建模。如 figure 1 所示。
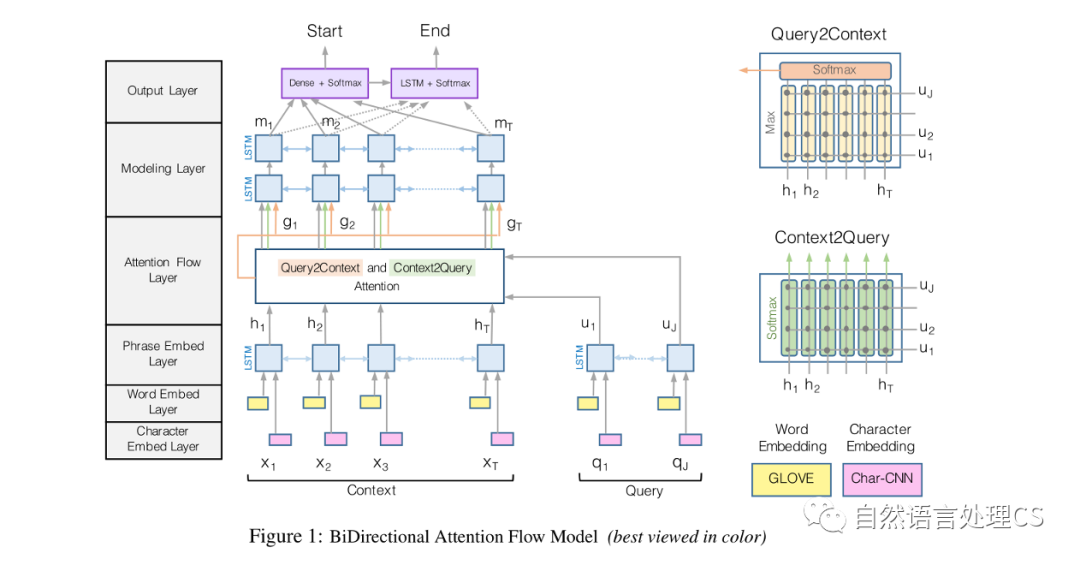
该网络包括:字符级、词级和上下文嵌入,并使用双向注意力流获得query-aware context表示。
本文的注意力机制对以前流行的注意力范式进行了以下改进:
-
首先,该注意力层不是用来将上下文段落总结为固定大小的向量。相反,将为每个时间步长计算注意力,并允许每个时间步长的附属向量与先前层的表示一起流向后续建模型,这减少了早期汇总造成的信息损失。
-
其次,本文使用了一种无记忆注意机制。也就是说,当通过时间迭代地计算注意力时,每个时间步长的关注度仅是当前时间步长的query和context段落的函数,而不是直接依赖于上一个时间步长的关注度。这种机制迫使关注层专注于学习query和context之间的注意力,并使建模层专注于学习可识别query的context表示内的交互。
2. Model
2.1 字符嵌入层
设和分别表示输入的context段落和query的单词。
本文使用CNN获得每个单词的字符级嵌入,并对CNN的输出执行max-pooled,以获得每个单词的固定大小。
2.2 单词嵌入
使用预训练的词向量glove获得每个单词的固定单词的嵌入。
字符级嵌入和单词嵌入经过拼接后会被送到一个两层的highway network。
残差网络的输出是两个d维向量的序列,对于context的表示向量为
,query的表示向量为。
2.3 上下文嵌入
将字符级嵌入和单词特征拼接后经过highway network的输出作为LSTM的输入,增加单词之间的交互,从context词向量X中得到,从query词向量Q中得到。
2.4 Attention Flow Layer
注意力流负责连接和融合来自不同上下文和query词的信息。该层的输入是上下文 和query 的上下文向量表示。输出是上下文词G的query-aware context表示,以及来自前一层的上下文嵌入。
在这一层中,从两个方向计算关注度:
-
from context to query
-
from query to context
下面讨论的两个方向的attention都是从上下文和query 的上下文嵌入之间的共享相似性矩阵中导出的,其中表示第t个context和第j个query单词之间的相似度矩阵。
其中是的第t列向量,同样如此,。
2.4.1 Context-to-query Attention
Context-to-query(C2Q)的注意表示哪些查询词与每个上下文词最相关。
设表示由第t个上下文词对查询单词的关注度权重,对于所有。
关注度权重由计算,随后每个关注查询向量是。
因此,是包含整个上下文的关注查询向量的2d×T矩阵。
2.4.2 Query-to-context Attention
Query-to-context(Q2C)注意表示哪些上下文词与查询词中的一个最相似,因此对回答查询至关重要。
我们通过来获得上下文词的关注权重,其中最大函数()是跨列执行的。
则参加的上下文向量是。该向量指示上下文中最重要的单词相对于查询的加权和。在整个柱子上平铺T次,从而得到到。
最后,将上下文嵌入和注意力向量组合在一起以产生G,其中每个列向量可以被认为是每个上下文词的查询感知表示。我们用G来定义:
其中,是第t列向量(对应于第t个上下文词),是融合其(三个)输入向量的可训练向量函数,是函数的输出维度。虽然函数可以是任意可训练的神经网络,如多层感知器,但在实验中,(即)仍然显示出良好的性能。
2.5. Modeling Layer
建模层的输入是G,它对上下文词的查询感知表示进行编码。建模层的输出捕获了以查询为条件的上下文词之间的交互。这与上下文嵌入层不同,上下文嵌入层独立于查询捕获上下文词之间的交互。我们使用两层双向LSTM,每个方向的输出大小为d。因此,我们得到一个矩阵,该矩阵被传递到输出层以预测答案。预期M的每个列向量包含关于整个上下文段落和查询的关于该单词的上下文信息。
3. Experiments
3.1 Result
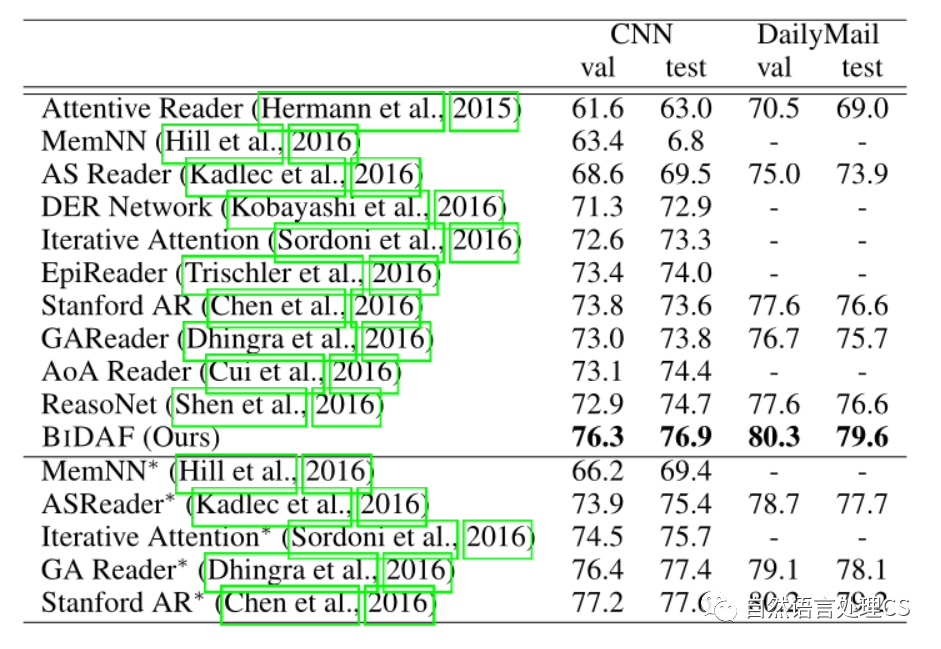
4. 启示
-
最牛的一篇阅读理解paper之一。
-
对于一对的输入序列都可以用双向注意力流,我愿称之为YYDS。
-
欢迎关注微信公众号:自然语言处理CS,一起来交流NLP。
















 503
503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











