







1.分析
对于手写数字集MNIST进行处理,实现0和非0元素的分类,手写数字集MNIST中包含60000个训练集和10000个测试集,共包括70000 张 28 ×28的手写数字灰度图像,图像数据已经被转换为28 × 28 = 784维的向量形式存储,标签对应的为10维向量存储,如数字3对应的标签为[0.0 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0.0.0]
2.矩阵操作
将 28 × 28 28×28 28×28矩阵展开,将二维变为一维,好处是解除变量之间的位置关系
X = [ v 1 , v 2 , . . . , v 784 ] X=[v_1,v_2,...,v_{784}] X=[v1,v2,...,v784]
X : [ 1 , d x ] X: [1,dx] X:[1,dx]
用三个线性函数嵌套来解决问题:
-
H 1 = X W 1 + b 1 H_1=XW_1+b_1 H1=XW1+b1
W 1 : [ d 1 , d x ] W_1: [d_1,dx] W1:[d1,dx]
b 1 : [ 1 , d 1 ] b_1:[1,d_1] b1:[1,d1]
-
H 2 = H 1 W 2 + b 2 H_2=H_1W_2+b_2 H2=H1W2+b2
W 2 : [ d 2 , d 1 ] W_2: [d_2,d_1] W2:[d2,d1]
b 2 : [ 1 , d 2 ] b_2:[1,d_2] b2:[1,d2]
-
H 3 = H 2 W 3 + b 3 H_3=H_2W_3+b_3 H3=H2W3+b3
W 3 : [ 10 , d 2 ] W_3: [10,d_2] W3:[10,d2]
b 3 : [ 1 , 10 ] b_3:[1,10] b3:[1,10]
3.损失函数
样本的 H 3 H_3 H3与标签之间的欧氏距离之和
4.非线性部分引入
三个线性函数嵌套,整个模型总体来说也是线性的,引入一个非线性部分激活函数,增强表达能力:
例如使用
R
e
L
U
ReLU
ReLU
- H 1 = r e l u ( X W 1 + b 1 ) H_1=relu(XW_1+b_1) H1=relu(XW1+b1)
- H 2 = r e l u ( H 1 W 2 + b 2 ) H_2=relu(H_1W_2+b_2) H2=relu(H1W2+b2)
- H 3 = r e l u ( H 2 W 3 + b 3 ) H_3=relu(H_2W_3+b_3) H3=relu(H2W3+b3)
5.分类结果
最后获得 H 3 H_3 H3中最大值的索引,即预测值
6.实现
1).基础
torchvision
t
o
r
c
h
v
i
s
i
o
n
torchvision
torchvision 由流行的数据集
(
d
a
t
a
s
e
t
s
)
( datasets)
(datasets)、模型架构
(
m
o
d
e
l
s
)
(models)
(models)和计算机视觉常用的图像转换
(
t
r
a
n
s
f
o
r
m
s
)
(transforms)
(transforms)组成
t
o
r
c
h
v
i
s
i
o
n
.
d
a
t
a
s
e
t
s
torchvision.datasets
torchvision.datasets 是用来进行数据加载的,PyTorch团队在这个包中帮我们提前处理好了很多很多图片数据集,包括
M
N
I
S
T
,
C
O
C
O
MNIST,COCO
MNIST,COCO等等
torch.utils.data.DataLoader
Pytorch数据读取(Dataset, DataLoader, DataLoaderIter)
PyTorch中数据读取的一个重要接口是torch.utils.data.DataLoader,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口,该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入,因此该接口有点承上启下的作用,比较重要(参考PyTorch源码解读之torch.utils.data.DataLoader)
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=2, persistent_workers=False)
输入
dataset (Dataset)-数据集
batch_size-一次加载多少图片
shuffle-true将数据随机打散
next与iter
def __iter__(self):
return DataLoaderIter(self)
用了dataloader 的__iter__() 方法, 产生了一个DataLoaderIter,DataLoader就是DataLoaderIter的一个框架, 用来传给DataLoaderIter 一堆参数, 并把自己装进DataLoaderIter 里。
def __next__(self):
if self.num_workers == 0: # same-process loading
indices = next(self.sample_iter) # may raise StopIteration
batch = self.collate_fn([self.dataset[i] for i in indices])
if self.pin_memory:
batch = pin_memory_batch(batch)
return batch
# check if the next sample has already been generated
if self.rcvd_idx in self.reorder_dict:
batch = self.reorder_dict.pop(self.rcvd_idx)
return self._process_next_batch(batch)
if self.batches_outstanding == 0:
self._shutdown_workers()
raise StopIteration
while True:
assert (not self.shutdown and self.batches_outstanding > 0)
idx, batch = self._get_batch()
self.batches_outstanding -= 1
if idx != self.rcvd_idx:
# store out-of-order samples
self.reorder_dict[idx] = batch
continue
return self._process_next_batch(batch)
while循环就是真正用来从队列中读取数据的操作,得到的batch一般是长度为2的列表,列表的两个值都是Tensor,分别表示数据(是一个batch的)和标签
TORCH.TENSOR
TENSOR即张量,张量是包含单一数据类型元素的多维矩阵,Tensor(张量)是一个多维数组,它是标量、向量、矩阵的高维拓展。
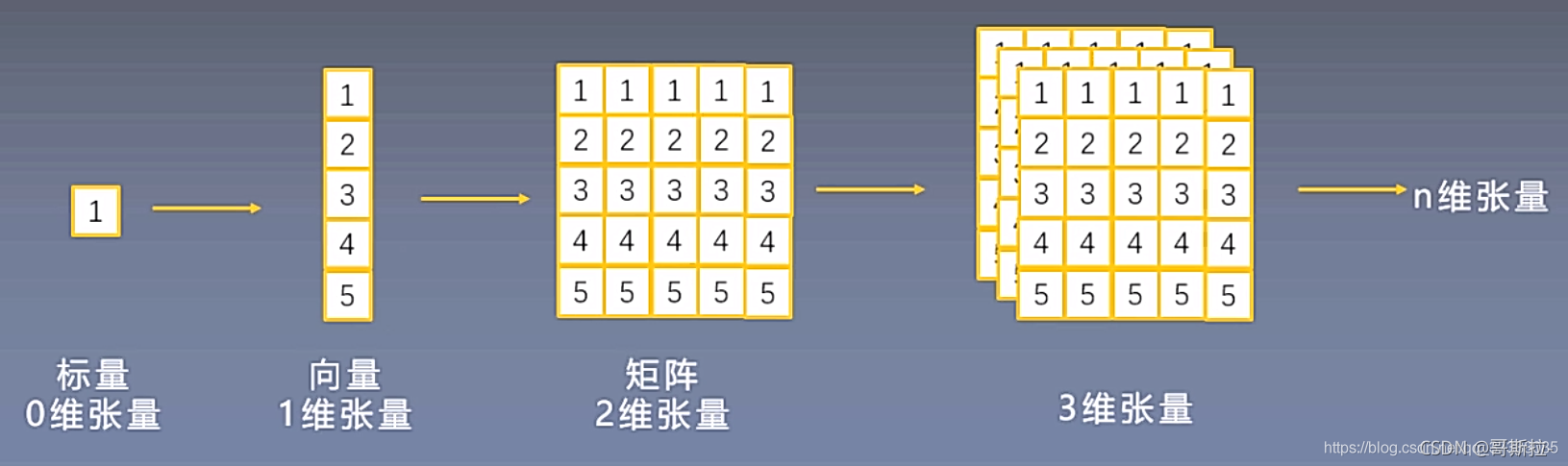
TORCH.TENSOR官方文档,Torch根据CPU和GPU定义了10种变量类型,torch.Tensor是默认张量类型(torch.FloatTensor)。
1).代码
import torch
from torch import nn
from torch.nn import functional as F
from torch import optim
import torchvision
#from matplotlib import pyplot as plt
from utils import plot_image,plot_curve,one_hot
#加载数据集
#batch_size一次处理图片的数量
# step1. load dataset
batch_size = 512
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=False)
x, y = next(iter(train_loader))
print(x.shape, y.shape, x.min(), x.max())
print(torch.__version__)
#plot_image(x, y, 'image sample')
class Net(nn.Module):
def __init__(self):#初始化函数
super(Net,self).__init__()
#xw+b
self.fc1=nn.Linear(28*28,256)
self.fc2=nn.Linear(256,64)
self.fc3 = nn.Linear(64,10)
def forward(self,x):
x = F.relu( self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net=Net()
optimizer=optim.SGD(net.parameters(),lr=0.01,momentum=0.9)
train_loss=[]
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中
for epoch in range(3):#循环三次
for batch_idx,(x,y) in enumerate(train_loader):
#x:[512,1,28,28] ,y:[512]
#[512,1,28,28]=>[512,784]
x=x.view(x.size(0),28*28)
out = net(x)
y_onehot=one_hot(y)
loss=F.mse_loss(out,y_onehot)
optimizer.zero_grad()#清零梯度
loss.backward()#计算梯度
optimizer.step()#更新梯度
train_loss.append(loss.item())#append() 方法用于在列表末尾添加新的对象
if batch_idx %10==0:
print(epoch,batch_idx,loss.item())

















 9836
9836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









