






CS231n学习笔记目录(2016年Andrej Karpathy主讲课程)
- Lecture1:Introduction(介绍)
- Lecture2:Image Classification Pipeline(数据驱动的图像分类方式) (上)
- Lecture2:Image Classification Pipeline(数据驱动的图像分类方式) (下)
- Lecture3:Loss functions and Optimization(线性分类器损失函数与最优化)
- Lecture4:Backpropagation and Neural Networks(反向传播与神经网络)
- Lecture5:Training Neural Networks(神经网络训练细节) Part 1
- Lecture6:Training Neural Networks(神经网络训练细节) Part 2
- Lecture7:Convolutional Neural Networks(卷积神经网络)
假设xi为输入样本,yi为样本标签,W为权重,f为分类器,则损失函数的一般形式如下:
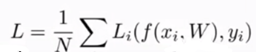
Multiclass SVM loss
SVM损失函数格式如下,这是一个二分类支持向量机的泛化,计算了所有不正确的类别,将所有不正确类别的评分和正确类别的评分作差,然后加上1,将得到的数值与0比较,取最大的数值,然后将所有的数值求和再取平均。这里不仅要求正确类别的评分高于错误类别,而且使用了一个安全系数1,该值并不是固定的,因为W是无标度的,可以成比例地变化,所以分数的大小与它的量度的选择紧密相关。
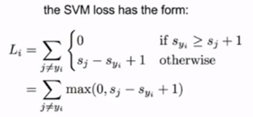
假设有3个类别,分别为cat、car、frog,下图中展现了对应每张图片在某种W下的得分:

根据SVM损失函数的定义,计算cat类、car类、frog类的损失为:
L1=max(0,5.1-3.2+1)+max(0,-1.7-3.2+1)=max(0,2.9)+max(0,-3.9)=2.9+0=2.0;
L2=max(0,1.3-4.9+1)+max(0,2.0-4.9+1)=max(0,-2.6)+max(0,-1.9)=0+0=0;
L3=max(0,2.2+3.1+1)+max(0,2.5+3.1+1)=max(0,6.3)+max(0,6.6)=12.9。
因此可以看出第二张图片得到了最小的loss,分类效果最好,最终的loss为:
L=(L1+L2+L3)/3=(2.9+0+12.9)/3=5.27
Problems
1、公式里面在计算损失时没有加入yi(j不为yi),如果选择将所有类别都加入计算,而不仅仅针对不正确的类别,则计算结果在原有的值上加1。
2、如果在计算每类分别的loss时不求平均值/求平均值,只是将loss的大小成比例地改变,还是会得到最优的W。
因此可以认为,参数的改变对结果是没有影响的。
3、如果用下面的公式
![]()
则会得到不同的损失。上面的问题1和2都是在不断地缩放或者平移损失,而这里是在非线性地改变,实际上计算了另一种损失函数(Square hinge loss)。损失函数的选择也可以视为超参数选择的一种。
4、当初始化W都接近于0的时候,输出的损失函数为类别数-1。这是一个不重要但有意义的数值。
5、如果得到了L=0,那么满足条件的W是不是唯一的?不是。W可以成比例的增加。
Weight Regularization
上述工作是在训练数据集中寻找最小损失的分类器,但实际上我们关心的重点并不是训练数据集,而是测试集。如果只关心测试集的表现,分类器拟合的太好,其在测试集上的表现可能不会很理想,也就是过拟合。而正则化是解决过拟合的一种方法。我们不仅想要数据拟合的更好,还需要优化W。
正则化是为了权衡训练损失和泛化损失,在原始函数中加入正则化项:
Data loss部分是为了拟合训练数据,Regularization部分是想让W呈现一种特殊的方式,我们想要同时实现这两个目标,因此在计算中这两个目标之间会相互竞争。
In common use
正则化最常用的形式有:

其中L2正则化是最常用的形式,如下例子,先有一个输入x,有两种候选的W权重,我们分别对它们计算损失,发现结果都是1,那么对于损失函数最小的规则来说,这两个权重都是很好的,当根据L2正则化项来判断,R(w1)=1,R(w2)=(0.25)²+(0.25)²+(0.25)²+(0.25)²=0.25,因此第二组权重更优。

这说明,当我们根据数据计算分类损失得到相同结果时,正则化会告诉我们要选择哪一组权重,上述w2权重考虑了输入x中的大部分,尽可能地展开W权重,尽可能地利用输入的维度,这样比只关注某个信息要好。
Softmax Classifier (Multinomial Logistic Regression)
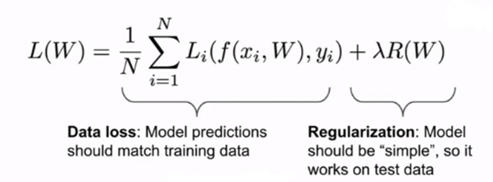
在softmax分类中,不将这些分数视为某种边界,而是对应不同类别为标准化的对数概率。公式如下:
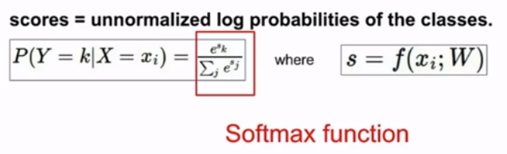
这里,sk代表第k类的得分,分子e^sk代表e的指数次幂,分母代表所有类别的概率和,我们的损失函数想要使正确类别的概率对数最大或者使得负概率对数最小(交叉熵损失函数):
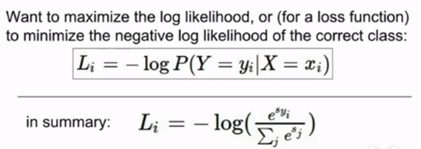
下面是计算实例,输入原始得分,然后根据公式计算e^sk,得到(24.5,164.0,0.18),然后计算softmax函数,(24.5/(24.5+164.0+0.18),164.0/(24.5+164.0+0.18),0.18/(24.5+164.0+0.18))=(0.13,0.87,0.00),最后计算损失,如L1=-log(0.13)=0.89。

Problems
1、loss的最大值最小值:当概率最大为1时,-log的值为0;当概率最小为0时,-log为正无穷。
2、当初始化W的值很小(接近于0)时,e^sk均接近于1,因此loss的值均为-log(1/类别总数)。
Softmax vs. SVM
给出以下三个分析样例,分别代表三个不同的类别,第一类是正确的类别。例如第三个[10,-100,-100],表示第一类的评分为10,第二类和第三类的评分为-100,那么损失的计算为:
L_svm0=max(0,-100-10+1)+max(0,-100-10+1)=0;
L_softmax0=-log(e^10/ (e^10+ e^-100+ e^-100))
假如对其评分进行细微的调整,比如调整为[9,-99,-101],则损失为:
L_svm=max(0,-99-9+1)+max(0,-101-19+1)=0;
L_softmax0=-log(e^9/ (e^9+ e^-99+ e^-101))
对于两个损失函数而言,SVM损失并不会改变,具有一定的稳定性,因为该损失是由边界值决定的,一些细微的变动不会影响边界,但对于softmax来说,对每一个样本点都有关注,因此每一个样本点的改变都会影响到softmax的值。因此,一旦样本点满足边界条件,这个样本点就不会影响SVM的损失函数,但会影响softmax损失函数,这是两者最大的区别。这个实例也表明,SVM分类器对一小部分接近于分类边界的样本点较为敏感(支持向量),而对远离分类边界的样本点不敏感,但softmax分类器对所有样本点都有考量。

Optimization
Slope
对于给出的W,我们需要计算相对于的损失,来反映分类器工作的好坏,如果损失很低,就说明分类器在训练集上的表现很好,通过随机搜索可以随机选取W,然后计算对应的损失,最后选取损失最小的W。但这种方法的效果并不好,这就像是一个人在山谷里面漫无目的地行走,想要找到山谷的最低点,但这是一个很棘手的问题。因此引入了梯度的概念,计算每个方向的斜率slope,然后再往下走,Follow the slope。

斜率的公式如下:
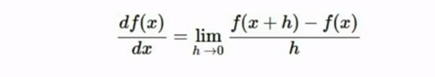
也就是求导,建立一个倒数向量,分别对应每个维度上的梯度,但这个公式在多维度情况下显得十分复杂,每改变一小步就要算出所有参数的损失值,只有算出loss后才能根据改变的loss求得梯度,因此会十分缓慢。观察到,loss是关于W的方程,因此只需要根据微分写出梯度的公式,就不用反复求解损失值了。
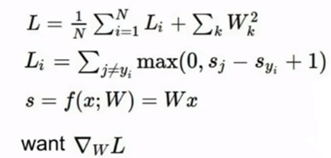
另外在实际操作中,我们取得一般是数据集当中的小批量数据,比如32、64或256个数据样本来计算损失、更新梯度,进行一次又一次的重复之后,来确定找到的使得损失最小的W。但也是因为所取得数据集是小批量,因此得到的梯度可能是一个噪声,没有什么意义,因此我们不会过多关注计算出的损失,这也算作取样求梯度得缺点,但是能够明显提高运算速度,可以计算更多的次数。实际运用中,小批量的效率更高,而且使用所有数据来计算梯度是不切实际的,GPU可能无法承受那么大的计计算量,所以一般我们不会用初始的集合来做模型优化。如下图的迭代过程中的损失:
在使用小批量样本计算梯度的过程中,即便会出现很多噪声,但总体上仍然呈现下降的趋势,如果使用全部样本,则这条曲线会变得平滑。
Learning rate
学习率是指在每一个循环中移动的大小,是一种十分重要的超参数,不同的学习率对损失函数有不同的影响。如果学习率太高(very high),每一步走的太远,那么一开始损失函数就会在空间里乱窜,甚至之后不会收敛,还会越来越大;如果学习率很低(low)的话,梯度更新速度就会很慢,损失函数达到收敛需要很长的时间;如果使用一个较高的学习率(high),最终也可能达到收敛,但收敛之后的函数值会卡在一个比较高的位置,也就是说最后收敛的值可能只是局部最小值;所以学习率的选择对最终的结果有很大的影响,大部分人会首先选择一个较高的学习率,然后再一点点的降低这个学习率。
Aside : Image Features
在计算机视觉历史观点中,一开始我们一直都在用线性分类器,但很明显无法将线性分类器直接应用到一张没有经过任何处理的图片上去,因为线性分类器无法解决像素的问题,因此人们习惯于计算图片的不同特征,然后计算对不同特征的描述,通过统计总结来理解这张图片是什么。比如下面红点和蓝点的分类,是无法用一条直线区分的,因此使用了极坐标转换,就可以把复杂的数据集变成线性可分的,实现正确分类。这个过程就是特征转换。

对于图像来说,一个典型的特征转换的例子就是使用颜色直方图,如下图中,每一个像素中的像素值都对应一个光谱,将这些光谱用分布的柱状图表示,计算每个光谱中像素点出现的频次,因此这种方法能从全局上告诉我们图像中有哪些颜色,比如这张青蛙的图片,颜色直方图很明确的告诉我们这张图里面绿色的部分较多,紫色和红色较少。

在神经网络兴起前,几种常用的特征向量就是HOG、SIFT、Bag of words。这个阶段通常都是先对图片进行特征提取,不同的图片关注的重点也不同,决定了什么是分类器比较感兴趣的特征,因此人们往往选择多个特征展开成一个很大的特征向量,然后放到线性分类器中。但神经网络出现后,人们发现并不需要去设计需要提取什么特征,而是建立了一个可以仿真出许多不同特征的结构,由机器直接从像素开始训练,完成整个训练过程,不需要人为确定哪些特征更重要。
(纯学习分享,如有侵权,联系删文)
















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











