







 本文详细介绍了线性回归的概念、应用和实现,包括一元线性回归和多元线性回归。重点讲解了线性回归的拟合原理,特别是梯度下降法,包括批梯度下降、随机梯度下降和Mini-Batch梯度下降,并通过实例展示了如何利用Sklearn库进行线性回归预测。最后,讨论了在不同训练集大小下选择合适梯度下降策略的方法。
本文详细介绍了线性回归的概念、应用和实现,包括一元线性回归和多元线性回归。重点讲解了线性回归的拟合原理,特别是梯度下降法,包括批梯度下降、随机梯度下降和Mini-Batch梯度下降,并通过实例展示了如何利用Sklearn库进行线性回归预测。最后,讨论了在不同训练集大小下选择合适梯度下降策略的方法。
机器学习 线性回归
一、一元线性回归算法
1.回归的理解
大自然让我们回归到一定的区间范围之内;反过来说就是,有一个平均的水平,可以让突出的事物能向他靠拢。
回归是由达尔文(Charles Darwin)的表兄弟Francis Galton发明的。 Galton于1877年完成了第一次回归预测,目的是根据上一代豌豆种子(双亲)的尺寸来预测下一代豌豆种子(孩子)的尺寸。Galton在大量对象上应用了回归分析,甚至包括人的身高。他注意到,如果双亲的高度比平均高度高,他们的子女也倾向于比平均高度高,但尚不及双亲。孩子的高度向着平均高度回退(回归)。Galton在多项研究上都注意到这个现象,所以尽管这个英文单词跟数值预测没有任何关系,但这种研究方法仍被称作回归 。
那些高个子的后代的身高,有种回归到大众身高的趋势。 eg: 姚明身高2米26,叶莉身高1米90, 但是他们后代的身高是会逐渐回归到正常的身高水平。
2.回归应用
销售量预测
制造缺陷预测。
预测名人的离婚率。
预测所在地区的房价。
3.线性回归
线性:利用算法生成的模型是一条直线。
回归:让数据聚集到一个特定的模型中。
线性回归:如果模型是一条直线,就是让数据靠近这条直线。
(1)利用Sklearn做线性回归的预测
预测步骤如下:
- 导包:
from sklearn.linear_model import LinearRegression - 导数据:导入文件或者随机生成
- 建模:利用 sklearn中 LinearRegression的
fit方法:
1> 实例化一个线性回归类:lin_reg= LinearRegression()
2> 训练模型,确定参数:lin_reg.fit(X,Y)
3> 参数存入对象lin_reg中,可以通过lin_reg.intercept_(截距)、lin_reg.coef_(系数)查看参数。 - 预测:利用 sklearn中 LinearRegression的predict()方法:
1> 准入预测数据X_predict
2> lin_reg.predict(X_predict)
(2)例:预测一组数据中当输入为12 对应输出的值。
import numpy as np
from sklearn.linear_model import LinearRegression #在线性模型中导入线性回归
X=np.array([1,2,3,4,5,6,7,8,9,10,11]).reshape(-1,1)#x从一维转为二维
Y=np.array([3,4,5,7,9,11,13,15,17,19,21])#Y:一维
#实例化对象
lin_reg= LinearRegression()
#调用fit方法 训练模型找规律
lin_reg.fit(X,Y)
#找到规律 截距与斜率
print(lin_reg.intercept_,lin_reg.coef_)
#预测x=12对应的Y
X_new=np.array([[12]]) #创建数组
print(lin_reg.predict(X_new))
执行结果:
0.03636363636363171 [1.87272727]
[22.50909091]
4.线性回归拟合原理(fit方法)
- 拟合就是把平面上一系列的点,用一条光滑的曲线连接起来。因为这条曲线有无数种可能,从而有各种拟合方法。拟合的曲线一般可以用函数表示。
- 对于一元线性回归(单变量线性回归)来说,学习算法为 y = ax + b 换一种写法: hθ(x) = θ0 + θ1x1
- 线性回归实际上要做的事情就是: 选择合适的参数(θ0, θ1),使得hθ(x)方程,很好的拟合训练集。实现如何把最有可能的直线与我们的数据相拟合。
- 我们选择的参数决定了我们得到的直线相对于我们的训练集的准确程度,模型所预测的值与训练集中实际值之间的差距就是建模误差(modeling
error)。 - 我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。 即使得损失函数最小。
- 模型=规律=函数=函数所表示的图像
(1)损失函数
判断模型最优拟合方式:损失函数- 损失函数含义:所有的点与模型距离平均和的公式。距离为0表示所有点都在直线上,参数为最优参数,拟合最准确。距离不为0时,要尽量找到损失函数的最小值时所对应的参数。
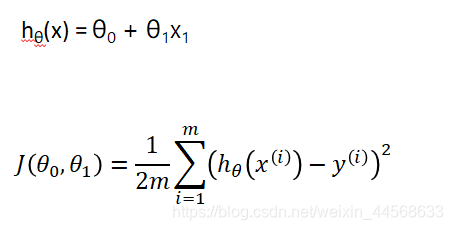
(2)梯度下降法
使得损失函数最小的方法:梯度下降法
- 思想:
1:随机初始化参数确定模型θ0 、θ1,得到一个损失函数值
2:使用特殊的更新方法更新参数θ0 、θ1,使得每一次所对应的损失函数的值越来越小。
3:直到更新参数损失函数的值变化波动不大,表示斜率到达最平稳处参数不变化进而损失函数不变化,找到损失函数最小值,此时对应的参数为最优解。
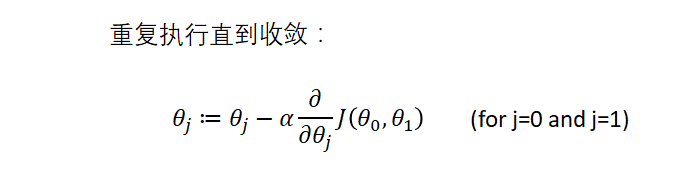
即:

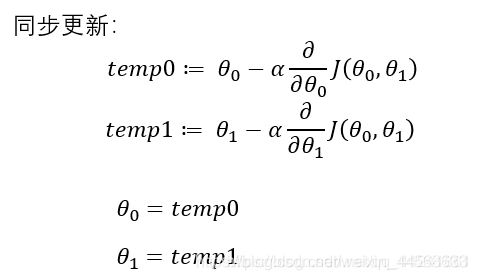
- 损失函数是一个凸函数,斜率变化是逐渐平缓的
如果α太小的话,梯度下降会很慢
如果α太大的话,梯度下降越过最小值,不仅不会收敛,而且有可能发散 - 即使学习率α是固定不变的,梯度下降也会熟练到一个最低点
因为随着梯度下降迭代次数的递增,斜率会趋于平缓,也就是说,导数部分𝜕/(𝜕𝜃_1 ) 𝐽(𝜃_0,𝜃_1 )会慢慢变小
做法: 根据上图公式
1> 求出损失函数对参数的偏导数
2> 损失函数对参数的偏导数乘学习率(梯度下降的幅度),得到梯度下降的距离。
3> 用梯度下降的距离更新参数
(3)梯度下降的分类
1>“Batch” Gradient Descent 批梯度下降
批梯度下降:指的是每下降一步,使用所有的训练集来计算梯度值
在梯度下降中,在计算微分求导项时,我们需要进行求和运算,所以,在每一个单独的梯度下降中,我们最终都要计算这样一个东西,这个项需要对所有个训练样本求和。因此,批量梯度下降法这个名字说明了我们需要考虑所有这一"批"训练样本。
线性回归实现一元批梯度下降:
import numpy as np
X = 2*np.random.rand(100,1) #生成100行1列的向量范围为0-2
Y=4+3*X+np.random.randn(100,1) #截距为4,斜率为3
#c_把两个维度相同的矩阵结合成以个矩阵 3x1 3x2 ->3x3
X_b=np.c_[np.ones((100,1)),X] #将 100行1列全为1的向量与X向量结合。实现矩阵的相乘截距处乘1,因此将x结合100行1列全为1的向量。为样本
learning_rate=0.1 #实现梯度下降函数的步长为0.1(1、0.1、0.2.。)
n_iterations=1000 #梯度函数执行1000次,自行判断是否收敛
m=100#样本数为100
theta=np.random.randn(2,1) #初始化,theta为一次函数的斜率和截距 2行1列
count=0
for iteration in range(n_iterations):
count+=1
#按照梯度函数公式求梯度
gradients= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 861
861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









