






Spring AI 是 Spring 生态系统中的一个新兴模块,专注于简化人工智能和机器学习技术在 Spring 应用程序中的集成。本文将详细介绍 Spring AI 的核心组件、功能模块及其之间的关系,帮助具有技术基础的读者快速了解和应用 Spring AI。
Spring AI 的核心概念
Spring AI 的设计理念遵循 Spring 框架一贯的原则:简化复杂技术的使用,让开发者能够专注于业务逻辑而非底层实现细节。在人工智能领域,Spring AI 通过抽象常见的 AI 操作,提供了一套统一的 API,使得与各种 AI 服务和模型的集成变得简单而直观。
Spring AI 模块分类
根据功能和用途,Spring AI 可以分为以下几个主要模块类别:
- AI 模型集成模块
- 向量数据库支持模块
- 文档处理模块
- 对话记忆存储模块
- 优化求解模块
让我们用 Mermaid 思维导图来展示这些模块的关系:
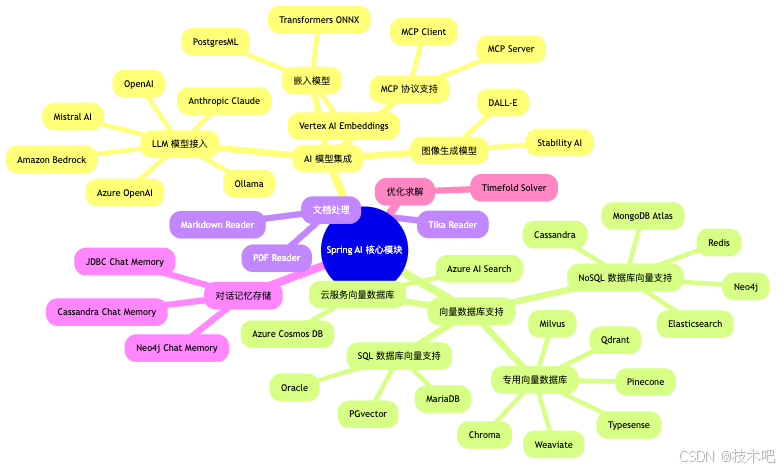
模块详解
1. AI 模型集成模块
这个模块提供了与各种 AI 模型和服务的集成能力,让开发者可以轻松地在 Spring 应用中使用先进的 AI 功能。
1.1 大型语言模型 (LLM) 支持
Spring AI 支持多种流行的大型语言模型服务:
- OpenAI - 提供对 ChatGPT 和 DALL-E 的支持
- Azure OpenAI - 微软的 OpenAI 服务版本,具有增强的功能
- Anthropic Claude - 支持 Anthropic 的 Claude 模型
- Mistral AI - 开源可移植的生成式 AI 模型
- Ollama - 本地运行各种 LLM 模型的解决方案
- Vertex AI Gemini - 谷歌的 Gemini 聊天模型支持
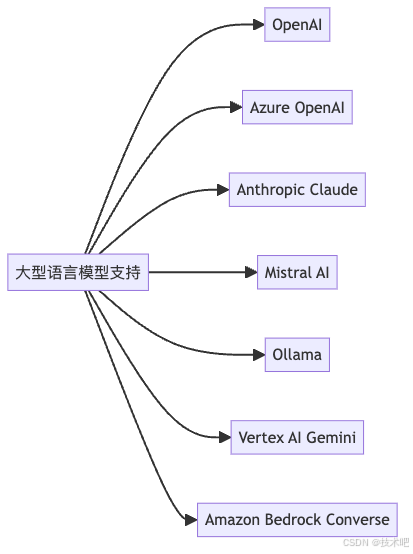
1.2 嵌入模型
嵌入模型将文本或多模态内容转换为向量表示,是实现语义搜索、推荐系统等功能的基础:
- Vertex AI Embeddings - Google 的文本和多模态嵌入模型
- Amazon Bedrock - 亚马逊的 Cohere 和 Titan 嵌入模型
- PostgresML - PostgreSQL 的文本嵌入模型
- Transformers (ONNX) - 预训练转换器模型,序列化为 ONNX 格式
1.3 图像生成模型
- Stability AI - 支持 Stability AI 的文本到图像生成模型
- OpenAI DALL-E - OpenAI 提供的图像生成模型
1.4 模型上下文协议 (MCP) 支持
- Model Context Protocol Server - MCP 服务器支持
- Model Context Protocol Client - MCP 客户端支持
2. 向量数据库支持模块
向量数据库是 AI 应用的重要组成部分,用于存储和检索嵌入向量。Spring AI 提供了丰富的向量数据库集成选项。
2.1 SQL 数据库向量支持
- PGvector - PostgreSQL 的向量扩展
- MariaDB Vector Database - MariaDB 的向量存储支持
- Oracle Vector Database - Oracle 的向量嵌入支持
2.2 NoSQL 数据库向量支持
- MongoDB Atlas Vector Database - MongoDB Atlas 的向量数据库支持
- Elasticsearch Vector Database - Elasticsearch 的向量搜索
- Redis Search and Query - Redis 的向量搜索功能
- Neo4j Vector Database - Neo4j 的向量搜索
- Apache Cassandra Vector Database - Cassandra 的向量数据库支持
2.3 专用向量数据库
- Pinecone - 云原生向量数据库
- Weaviate - 开源向量数据库
- Qdrant - 高性能向量搜索引擎
- Milvus - 开源向量数据库
- Chroma - 开源嵌入数据库
- Typesense - 向量搜索支持
2.4 云服务向量数据库
- Azure AI Search - 微软的 AI 搜索平台
- Azure Cosmos DB Vector Store - Azure Cosmos DB 的向量存储

3. 文档处理模块
Spring AI 提供了多种文档读取和处理工具,能够从不同格式的文档中提取文本并转换为 Spring AI Document 对象。
- Markdown Document Reader - 读取和处理 Markdown 文档
- PDF Document Reader - 使用 Apache PdfBox 读取 PDF 文档
- Tika Document Reader - 使用 Apache Tika 提取多种文档格式的文本
4. 对话记忆存储模块
这些模块提供了存储和管理聊天历史的功能,对于构建具有上下文感知能力的对话应用至关重要。
- JDBC Chat Memory Repository - 基于 JDBC 的聊天记忆存储
- Cassandra Chat Memory Repository - 基于 Cassandra 的聊天记忆存储
- Neo4j Chat Memory Repository - 基于 Neo4j 的聊天记忆存储
5. 优化求解模块
- Timefold Solver - AI 求解器,用于优化操作和调度问题
Spring AI 架构与工作流程
下面的图表展示了 Spring AI 的典型工作流程:
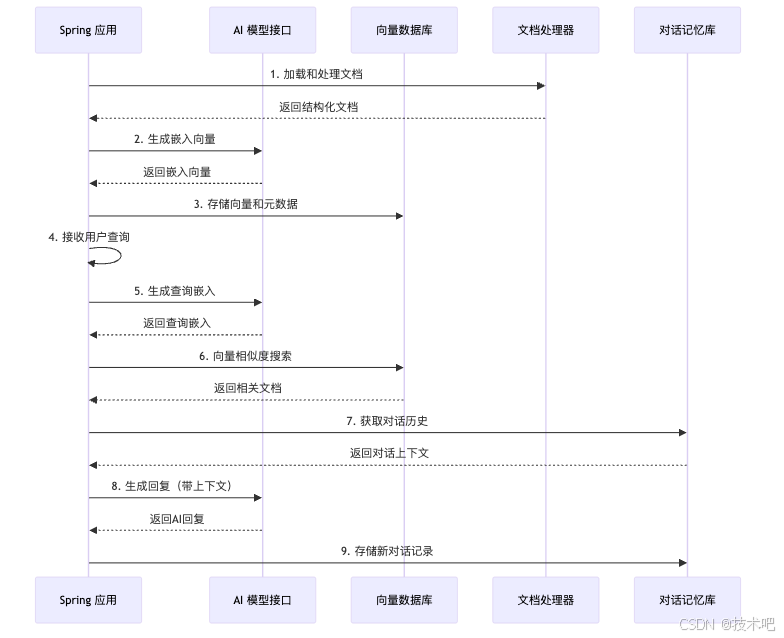
实际应用场景
Spring AI 可以应用于多种实际场景:
- 智能客服系统 - 利用 LLM 和对话记忆库构建上下文感知的客服系统
- 文档智能搜索 - 使用文档处理器、嵌入模型和向量数据库实现语义搜索
- 内容生成 - 利用 LLM 或图像生成模型创建内容
- 知识管理系统 - 将企业文档转化为可查询的知识库
- 智能调度系统 - 使用 Timefold Solver 优化资源分配
与 Spring 生态系统的集成
Spring AI 无缝集成到 Spring 生态系统中,可以与其他 Spring 项目协同工作:
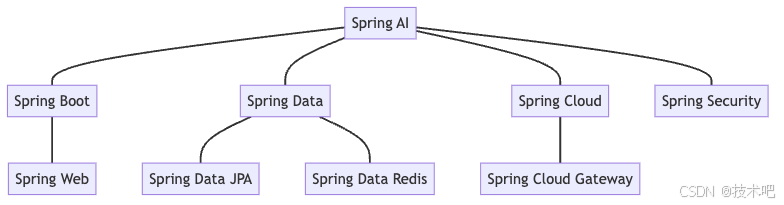
入门示例
以下是一个简单的 Spring AI 应用程序示例,展示了如何使用 Ollama 本地运行的 LLM 模型:
@RestController
public class ChatController {
private final OllamaChatModel chatModel;
@Autowired
public ChatController(OllamaChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map<String,String> generate(@RequestParam(value = "message", defaultValue = "讲个程序员的笑话") String message) {
return Map.of("generation", this.chatModel.call(message));
}
}
配置 Ollama 客户端:
# application.yaml
spring:
ai:
ollama:
base-url: http://localhost:11434 # Ollama 默认运行地址
chat:
options:
model: qwen2.5:latest # 可以使用任何已在 Ollama 中安装的模型
temperature: 0.7
在使用上述代码前,你需要:
- 安装 Ollama (https://ollama.com/)
- 拉取所需的模型,例如:
ollama pull qwen2.5:latest - 确保 Ollama 服务正在运行
添加 Maven 依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
示例响应:
{
"generation": "当然可以,这里有一个程序员相关的笑话:
为什么26个字母只剩下25个了?
因为字母“Q”被程序员‘u’了!(谐音梗:“被程序员输(u)了”,意指被击败或打败)
希望这个小笑话能让你会心一笑!"
}
写在最后
Spring AI 提供了一套全面的工具和抽象,简化了在 Spring 应用中集成 AI 功能的过程。通过标准化的接口,开发者可以轻松地切换不同的 AI 服务提供商,同时保持应用程序代码的一致性。
随着人工智能技术的快速发展,Spring AI 也在不断扩展其功能范围,支持更多的模型、数据库和应用场景。无论是构建简单的聊天机器人还是复杂的 AI 驱动系统,Spring AI 都提供了一条简捷的路径。


















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











