







如果我们的Elasticsearch集群做了一些离线的维护操作时,如扩容磁盘,升级版本等,需要对集群进行启动,节点数较多时,从第一个节点开始启动,到最后一个节点启动完成,耗时可能较长,有时候还可能出现某几个节点因故障无法启动,排查问题、修复故障后才能加入到集群中,此时集群会干什么呢?
假设10个节点的集群,每个节点有1个shard,升级后重启节点,结果有3台节点因故障未能启动,需要耗费时间排查故障,如下图所示:
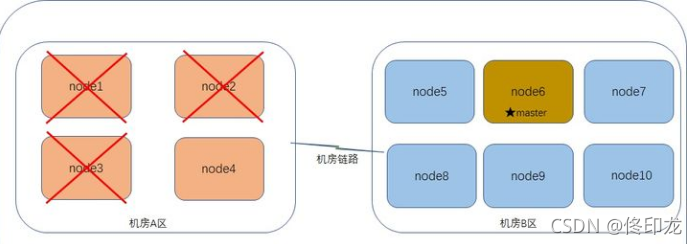
整个过程步骤如下:
集群已完成master选举(node6),master发现未加入集群的node1、node2、node3包含的shard丢失,便立即发出shard恢复的指令。
在线的7台node,将其中一个replica shard升级为primary shard,并且进行为这些primary shard复制足够的replica shard。
执行shard rebalance操作。
故障的3台节点已排除,启动成功后加入集群。
这3台节点发现自己的shard已经在集群中的其他节点上了,便删除本地的shard数据。
master发现新的3台node没有shard数据,重新执行一次shard rebalance操作。
这个过程可以发现,多做了四次IO操作,shard复制,shard首次移动,shard本地删除,shard再次移动,这样凭空造成大量的IO压力,如果数据量是TB级别的,那费时费力不讨好。
出现此类问题的原因是节点启动的间隔时间不能确定,并且节点越多,这个问题越容易出现,如果可以设置集群等待多少个节点启动后,再决定是否对shard进行移动,这样IO压力就能小很多。
针对这个问题,我们有下面几个参数:
gateway.recover_after_nodes:集群必须要有多少个节点时,才开始做shard恢复操作。
gateway.expected_nodes: 集群应该有多少个节点
gateway.recover_after_time: 集群启动后等待的shard恢复时间
如上面的案例,我们可以这样设置:
gateway.recover_after_nodes: 8
gateway.expected_nodes: 10
gateway.recover_after_time: 5m
这三个参数的含义:集群总共有10个节点,必须要有8个节点加入集群时,才允许执行shard恢复操作,如果10个节点未全部启动成功,最长的等待时间为5分钟。
这几个参数的值可以根据实际的集群规模来设置,并且只能在elasticsearch.yml文件里设置,没有动态修改的入口。
上面的参数设置合理的情况,集群启动是没有shard移动的现象,这样集群启动的时候就可以由之前的几小时,变成几秒钟。














 3542
3542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









