







首先要阐述一个观点,任何技术都是为解决某一个领域的问题而存在的,我们在使用它的时候,尽可能使用它的优势(亮点),去发挥它应具备的业务价值。es在很多公司应用非常广泛,它已经成为玩大数据的必备的技能,在之前的章节我吐槽过es写方面的问题,今天将吐槽下es查询-terms语法的那些坑,这里探讨两点:一个是多terms并发带来高CPU,另一个是terms使用不当会导致bug。
业务场景
我们基于门店+商品做了一个业务上的大宽表,有各种维度的查询,需要分页,比如按商品的采购组织、采购组、商品的类别(部类-大类-中类-小类)、商品名称查询等
{undefined
"from": 0,
"size": 200,
"timeout": "30s",
"query": {undefined
"bool": {undefined
"must": [
{undefined
"terms": {undefined
"purchase_org_code": [
"${purchase}"
],
"boost": 1.0
}
},
{undefined
"terms": {undefined
"purchase_group_code": [
"P05",
"P06",
"P07",
"P08",
"P09",
"P10",
"P11",
"U01",
"U02",
"U03",
"U04",
"U05",
"U06",
"U07",
"U08",
"U09",
"U10",
"U11",
"U12",
"U13",
"U15",
"U16",
"U17",
"U18"
],
"boost": 1.0
}
},
{undefined
"terms": {undefined
"product_code": [
"${product1}",
"${product2}",
"${product3}",
"${product4}",
"${product5}"
],
"boost": 1.0
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
}
}
集群规模
目前集群规模也不大,版本是6.7.1,大概是3个data3个master,这里我展示其中一台data数据存储情况:
doc.count:3.4亿
jvm.heap:12g
store.size:106G
os.men:15G
压测的结果
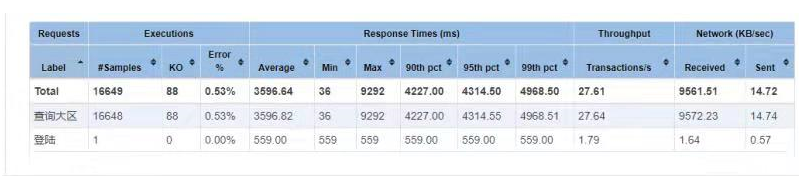
what?你没看错,TPS不行,失败率太高了。最后通过监控发,IO-wait太乱了,通过命令检测发现,IO读(即使是不是随机读)基本上就是40~50mb的峰值,延迟超5s以上。真是服了拿着高薪玩着云计算的同事,号称云版SSD盘,距离阿里云ECS的SSD差点不是一点点,以下是阿里云上的给出的指标
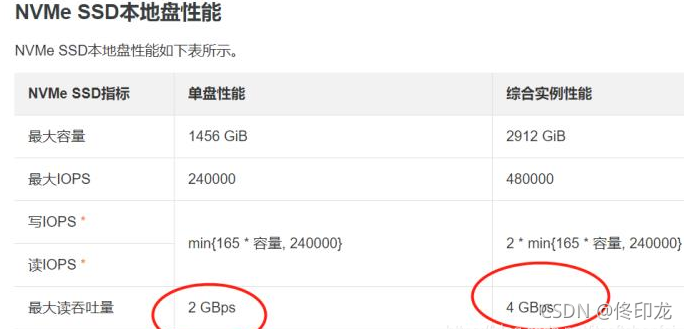
注:1GBps=1024/8=128MB
下云-建新集群-数据迁移
采用了虚拟机的方式,磁盘IO-wait不是那么严重了,迁移集群又变得很麻烦。由于集群线上不能停机,而reindex又太慢了,那就盘拷贝吧。
要知道:es的频繁的读盘会受pageCache影响,因此堆内存、机器内存都增加。
由于没有关闭索引,部分translog文件会被损坏了(/data/es/nodes/0/indices/jkZF34s-SVuGhTiBgDv2cw/3/translog/translog-185.tlog文件恢复不了),只能把这个索引删掉,老老实实的reindex。
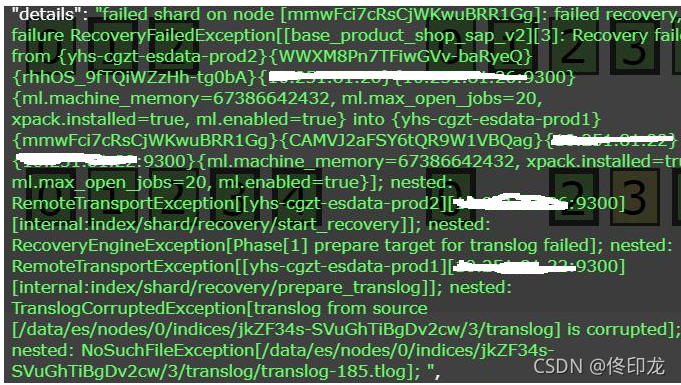
热门问题:99%… cpu usage by thread…6/10 snapshots sharing following 29 elements
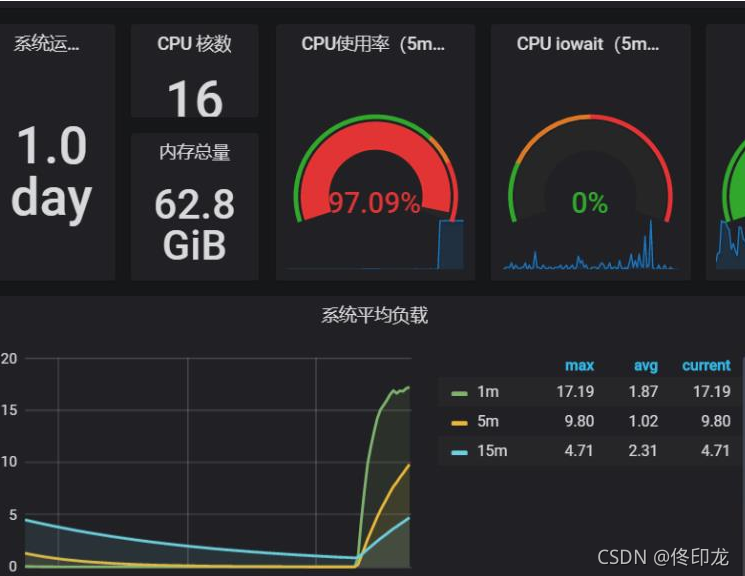
继续并发压测的确失败率降下来了,但16核的CPU跑满了!!
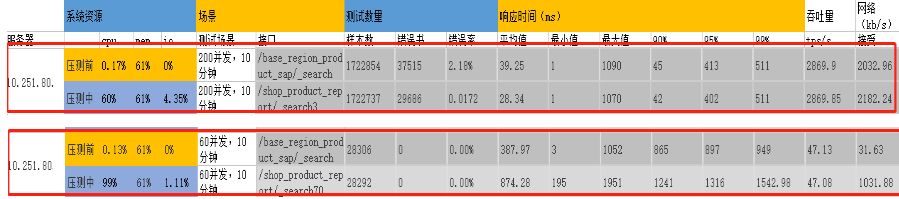
注意:第二个查询条件里,每个terms里数据比第一个多了将近30个,差异地区很大的。
看监控也确实是usr进程,通过_nodes/hot_threads便可得到上面的那个热门问题(google都能搜到不下于百万级同样问题的反馈,即使是官方也不少)
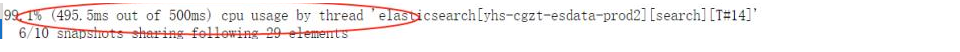
"elasticsearch[yhs-cgzt-esdata-prod1][search][T#19]" #171 daemon prio=5 os_prio=0 tid=0x00007f326c041000 nid=0x4c76 runnable [0x00007f15752d6000]
java.lang.Thread.State: RUNNABLE
at org.apache.lucene.util.BitSet.or(BitSet.java:95)
at org.apache.lucene.util.FixedBitSet.or(FixedBitSet.java:271)
at org.apache.lucene.util.DocIdSetBuilder.add(DocIdSetBuilder.java:151)
at org.apache.lucene.search.TermInSetQuery$1.rewrite(TermInSetQuery.java:259)
at org.apache.lucene.search.TermInSetQuery$1.scorer(TermInSetQuery.java:322)
at org.apache.lucene.search.Weight.scorerSupplier(Weight.java:143)
at org.apache.lucene.search.LRUQueryCache$CachingWrapperWeight.scorerSupplier(LRUQueryCache.java:719)
at org.elasticsearch.indices.IndicesQueryCache$CachingWeightWrapper.scorerSupplier(IndicesQueryCache.java:157)
at org.apache.lucene.search.BooleanWeight.scorerSupplier(BooleanWeight.java:364)
at org.apache.lucene.search.BooleanWeight.scorer(BooleanWeight.java:330)
at org.apache.lucene.search.Weight.bulkScorer(Weight.java:177)
at org.apache.lucene.search.BooleanWeight.bulkScorer(BooleanWeight.java:324)
at org.elasticsearch.search.internal.ContextIndexSearcher$1.bulkScorer(ContextIndexSearcher.java:180)
at org.apache.lucene.search.IndexSearcher.search(IndexSearcher.java:667)
at org.elasticsearch.search.internal.ContextIndexSearcher.search(ContextIndexSearcher.java:191)
at org.apache.lucene.search.IndexSearcher.search(IndexSearcher.java:471)
at org.elasticsearch.search.query.QueryPhase.execute(QueryPhase.java:276)
at org.elasticsearch.search.query.QueryPhase.execute(QueryPhase.java:114)
at org.elasticsearch.search.SearchService.loadOrExecuteQueryPhase(SearchService.java:349)
at org.elasticsearch.search.SearchService.executeQueryPhase(SearchService.java:393)
at org.elasticsearch.search.SearchService.access$100(SearchService.java:125)
at org.elasticsearch.search.SearchService$2.onResponse(SearchService.java:358)
at org.elasticsearch.search.SearchService$2.onResponse(SearchService.java:354)
at org.elasticsearch.search.SearchService$4.doRun(SearchService.java:1085)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37)
at org.elasticsearch.common.util.concurrent.TimedRunnable.doRun(TimedRunnable.java:41)
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingAbstractRunnable.doRun(ThreadContext.java:751)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
堆栈看上去没有啥问题,这个问题一般而言(低成本),再准备一个es集群(选什么版本呢,你认为最稳定bug,es更新太频繁了:笔者经验及社区里反馈不止一次遇到过版本问题,每个小版本更新的bug非常多),使用同样的数据同样的配置再试下。
不好意思,很不幸,问题依然还是那个问题,这时恭喜你摊上事情了,只能硬啃了。
首先针对GC的问题(频繁的GC,GC一次时间很长),按某大牛建议,需安装Java 11(他说es7.1以上版本,自带java11),切换成G1,也确实问题得到了解决。

G1GC Configuration
NOTE: G1GC is only supported on JDK version 10 or later.
To use G1GC uncomment the lines below.
-XX:-UseConcMarkSweepGC
-XX:-UseCMSInitiatingOccupancyOnly
-XX:+UseG1GC
-XX:InitiatingHeapOccupancyPercent=75
其实如果你有足够的玩ES经验,从hot_threads中snapshots sharing following 29 elements 可以推测这涉及到大量的查询,很不正常。对,借助监控api就足以验证这点(Query Count和Fetch Count确实很高啊)
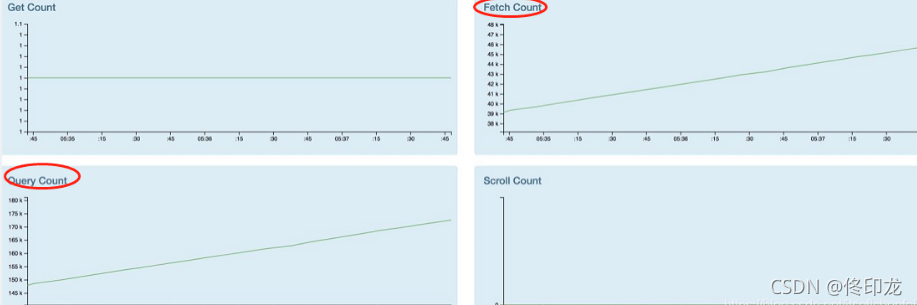
关于Query和Fetch 补充点背景知识
ES的查询和mapreduce也很类似,首先ES客户端会将这个搜索词同时向5个分片发起搜索请求,他们基于本Shard独立完成搜索,这叫Scatter,然后将符合条件的结果全部返回这一步叫Gather。
数量问题
当用户搜索某个词需要返回最符合条件的前10条,但在5个分片中每个分片都会返回符合条件的10条记录,此时,客户端最多会收到10*5=50条记录。
排名问题
每个分片计算分值(包括词频率)都是基于自己的分片数据进行计算的,而ES进行整体排名是基于每个分片计算后的分值进行排序的,这就可能会导致排名不准确的问题。这就可能会导致排名不准确的问题。如果我们想更精确的控制排序,应该先将计算排序和排名相关的信息(词频率等)从5个分片收集上来,进行统一计算,然后使用整体的词频率去每个分片进行查询。
ES对数量问题和排名问题也没有什么较好的解决方法,最终把选择的权利交给用户。
es在查询时可以指定搜索类型为:
QUERY_THEN_FETCH(默认),大概分两个步骤,第一步,先向所有的shard发出请求,各分片只返回排序和排名相关的信息(注意,不包括文档document),然后按照各分片返回的分数进行重新排序和排名,取前size个文档。然后进行第二步,去相关的shard取document。这种方式返回的document与用户要求的size是相等的。优点是数据量是准确的,但性能一般并且数据排名不准确。
QUERY_AND_FEATCH,向索引的所有分片(shard)都发出查询请求,各分片返回的时候把元素文档(document)和计算后的排名信息一起返回。这种搜索方式是最快的。这种查询方法只需要去shard查询一次。但是各个shard返回的结果的数量之和可能是用户要求的size的n倍。优点是搜索方式是最快的,但返回的数据量不准确。
DFS_QUERY_THEN_FEATC,这种方式比第一种方式多了一个初始化散发(initial scatter)步骤,先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块, 再执行后面的操作。优点很明显,数据量是准确并且排名也准确,但性能是最差的。
DFS_QUERY_AND_FEATCH,这种方式比第二种多了一个初始化散发(initial scatter)步骤,可以更精确控制搜索打分和排名,过程与上一种类似,优点是排名准确,但返回的数据量不准确,可能返回(N*分片数量)的数据。
从性能考虑QUERY_AND_FETCH是最快的且性能最好,DFS_QUERY_THEN_FETCH是最慢的、性能一般、数据排名也不准确。从搜索的准确度来说,DFS要比非DFS的准确度更高。可参阅6.2系列文档
多个terms搜索
在mysql中的方言中有这样的语法:select * from user where (user_id,type) in ((568,6),(569,6),(600,8)),此时使用terms很显然是无能无力的(包括笔者也犯过这样低级的问题),它查询的逻辑更多笛卡尔乘积的并集。
注:交集要有预估,如果terms的个数较多并且terms中的词数目也比较多,多个大数据集合并,很容易占核,稍微一点并非就会game over。
确实业务诉求也要满足,笔者想到了2中对策:
index时,需查询的多列合并为一列,就不存在数据交叉的问题
使用bool多层嵌套,满足语义
{undefined
"from": 0,
"size": 200,
"timeout": "30s",
"query": {undefined
"bool": {undefined
"should": [
{undefined
"bool": {undefined
"must": [
{undefined
"term": {undefined
"shop_code": "9120"
}
},
{undefined
"term": {undefined
"product_code": "771630106"
}
}
]
}
},
{undefined
"bool": {undefined
"must": [
{undefined
"term": {undefined
"shop_code": "9011"
}
},
{undefined
"term": {undefined
"product_code": "771630106"
}
}
]
}
}
]
}
}
}
es确实很强健,超过1024个term,就报错了…无语…
如果用terms查询,传入数组,默认最大长度65535,也可以通过index.max_terms_count更改这个值。
的确,es默认支持元素数量为1024个(可调整配置elasticsearch.yml的index.query.bool.max_clause_count: 10240)
回去看了代码
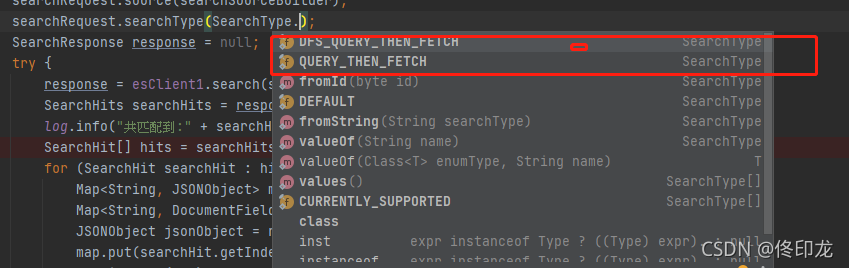
目前es 7.3.1 仅仅支持这2 种,使用大多数 使用DFS_QUERY_THEN_FETCH














 3526
3526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









