







简介
在对搜索结果进行排名时,如果需要返回用户的点击行为,就要用到神经网络去进行监督学习,此例中使用了多层感知机网络,以tanh()为激活函数,使用前馈算法计算输出,使用反向传播算法进行学习(调整权重矩阵),其中以用户的点击行为作为目标输出。
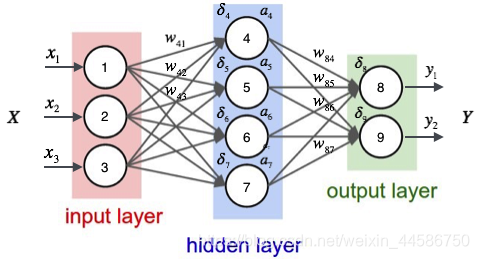
图片来源:https://www.zybuluo.com/hanbingtao/note/476663#an1
设置数据库
由于神经网络需要在用户查询时不断地训练,因此我们要将网络的信息存入数据库中
数据库中已有的表:涉及单词以及url
(1)数据库需要新增的表:
1.一张隐藏层的表:hiddennode(create_key)
2.一张连接输入层与隐藏层的表:wordhidden(fromid,toid,strength)
3.一张连接隐藏层和输出层的表:hiddenurl(fromid,toid,strength)
class searchnet:
def __init__(self, dbname):
self.con = sqlite3.connect(dbname)
def __del__(self):
self.con.close()
def maketables(self):
self.con.execute('drop table if exists hiddennode')
self.con.execute('drop table if exists wordhidden')
self.con.execute('drop table if exists hiddenurl')
self.con.execute('create table hiddennode(create_key)')
self.con.execute('create table wordhidden(fromid,toid,strength)')
self.con.execute('create table hiddenurl(fromid,toid,strength)')
self.con.commit()
(2)建立一个方法获取两个节点之间的连接强度,如果两个节点的连接之前未出现过(即出现了新连接),则返回连接强度的默认值
#判断当前连接的强度 新连接只在必要时才会被创建,此方法在连接不存在时会返回一个默认值
def getstrength(self,fromid,toid,layer):
if layer==0:
table='wordhidden'
else:
table='hiddenurl'
res=self.con.execute('select strength from %s where fromid=%d and toid=%d' %(table,fromid,toid)).fetchone()
if res==None:
if layer==0:return -0.2
if layer==1:return 0
else:
return res[0]
(3)建立一个setstrength()方法,判断连接是否存在,并用新的强度值更新连接或创建连接。
#判断连接是否已存在,并利用新的强度值更新连接或创建连接
def setstrength(self,fromid,toid,layer,strength):
if layer==0:
table='wordhidden'
else:
table='hiddenurl'
#在层级表中查找索引号
res=self.con.execute('select rowid from %s where fromid=%d and toid=%d' %(table,fromid,toid)).fetchone()
if res==None:
self.con.execute('insert into %s (fromid,toid,strength) values (%d,%d,%f)' %(table,fromid,toid,strength))
else:
rowid=res[0]
self.con.execute('update %s set strength=%f where rowid=%d' %(table,strength,rowid))
(4)每传入一组从未见过的单词组合,该函数就会在隐藏层中建立一个新的节点。随后,函数会为单词与隐藏节点之间,以及隐藏节点与输出节点(url)之间,建立起具有默认权重的连接
#每传入一组从未见过的单词组合,该函数就会在隐藏层中建立一个新的节点
#[wordids]->wordhidden->hiddennode->hiddenurl->[urls]
#hiddennode(create_key)
#wordhidden(fromid,toid,strength)
#hiddenurl(fromid,toid,strength)
def generatehiddennode(self,wordids,urls):
if len(wordids)>3:return None
#检查我们是否已经为这组单词建好了一个节点 单词节点排序例 "1_2_3"
#先排序,方便检查
createkey='_'.join(sorted([str(wi) for wi in wordids]))
res=self.con.execute("select rowid from hiddennode where create_key='%s'" %createkey).fetchone()
#如果没有,则建立之
if res==None:
cur=self.con.execute("insert into hiddennode (create_key) values ('%s')" %createkey)
hiddenid=cur.lastrowid
#设置默认权重
for wordid in wordids:
self.setstrength(wordid,hiddenid,0,1.0/len(wordids))
for urlid in urls:
self.setstrength(hiddenid,urlid,1,0.1)
self.con.commit()
前馈法
前馈法接受一组单词作为输入,激活网路中的连接,针对url给出一组输出
(1)建立一个方法,从数据库中查询出节点与连接的信息,然后在内存中建立起与某项查询相关的那一部分网络(每次使用前馈法计算输出时,并不会用到所有的隐藏层节点,只会用到与查询单词相关的隐藏层节点)
注意:
python3中不支持对dict的keys()进行索引
#从隐藏层中找出与查询单词以及url相关的所有节点
def getallhiddenids(self,wordids,urlids):
l1={}
for wordid in wordids:
#找出所有查询的单词对应的隐藏层的节点
cur=self.con.execute('select toid from wordhidden where fromid=%d' %wordid)
for row in cur:
l1[row[0]]=1
for urlid in urlids:
cur=self.con.execute('select fromid from hiddenurl where toid=%d' %urlid)
for row in cur:
l1[row[0]]=1
#python3不支持dict的key索引
return list(l1.keys())
(2)建立一个方法,为searchnet定义多个实例变量,包括:
1.单词列表、查询节点,URL
2.单词节点的输出、查询节点的输出、URL节点的输出
3.每个节点间的权重值
#建立起神经网络来
def setupnetwork(self,wordids,urlids):
#值列表
self.wordids=wordids
self.hiddenids=self.getallhiddenids(wordids,urlids)
self.urlids=urlids
#节点输出
self.ai=[1.0]*len(self.wordids)
self.ah=[1.0]*len(self.hiddenids)
self.ao=[1.0]*len(self.urlids)
#建立权重矩阵
self.wi=[[self.getstrength(wordid,hiddenid,0) for hiddenid in self.hiddenids] for wordid in self.wordids]
self.wo=[[self.getstrength(hiddenid,urlid,1) for urlid in self.urlids] for hiddenid in self.hiddenids]
(3)构造前馈算法,算法接受一列输入,将其推入网络,然后返回所有输出层节点的输出结果
选择输入(搜索词)->加权并激活->选择对应的查询节点(隐藏层)->加权并激活->url节点(输出,也是给定一个url的范围)
#构造前馈算法 算法接受一列输入,将其推入网络,然后返回所有输出层节点的输出结果
#本例中由于已经构造了一个只与查询条件中的单词相关的网络,因此所有来自输入层节点的输出结果总是1
#不同的单词组合决定的是采用哪几个查询节点
def feedforward(self):
#查询单词是仅有的输入
for i in range(len(self.wordids)):
self.ai[i]=1
#隐藏层节点的活跃程度
for j in range(len(self.hiddenids)):
sum=0.0
for i in range(len(self.wordids)):
sum+=self.ai[i]*self.wi[i][j]
self.ah[j]=tanh(sum)
#输出层节点的活跃程度
for k in range(len(self.urlids)):
sum=0.0
for j in range(len(self.hiddenids)):
sum=sum+self.ah[j]*self.wo[j][k]
self.ao[k]=tanh(sum)
return self.ao[:]
(4)生成结果,从建立网络到前馈
def getresult(self,wordids,urlids):
self.setupnetwork(wordids,urlids)
return self.feedforward()
反向传播法训练
具体的步骤已经做了笔记,且可以参考如下网址,讲得很好:
https://www.zybuluo.com/hanbingtao/note/476663#an1
也是一系列固定的步骤
#反向传播法
def backPropagate(self,targets,N=0.5):
#计算输出层的误差
output_deltas=[0.0]*len(self.urlids)
for k in range(len(self.urlids)):
error=targets[k]-self.ao[k]
output_deltas[k]=dtanh(self.ao[k])*error
#计算隐藏层的误差
hidden_deltas=[0.0]*len(self.hiddenids)
for j in range(len(self.hiddenids)):
error=0.0
for k in range(len(self.urlids)):
error=error+output_deltas[k]*self.wo[j][k]
hidden_deltas[j]=dtanh(self.ah[j])*error
#更新输出权重
for j in range(len(self.hiddenids)):
for k in range(len(self.urlids)):
change=output_deltas[k]*self.ah[j]
self.wo[j][k]=self.wo[j][k]+N*change
#更新输入权重
for i in range(len(self.wordids)):
for j in range(len(self.hiddenids)):
change=hidden_deltas[j]*self.ai[i]
self.wi[i][j]=self.wi[i][j]+N*change
(2)然后将前面函数集合到一个函数,用于训练
注意:
每一次反向传播学习前,需要重新前馈一下,因为此时输出值已经发生了变化
#更新数据库
def updatedatabase(self):
#将值存入数据库
for i in range(len(self.wordids)):
for j in range(len(self.hiddenids)):
self.setstrength(self.wordids[i],self.hiddenids[j],0,self.wi[i][j])
for j in range(len(self.hiddenids)):
for k in range(len(self.urlids)):
self.setstrength(self.hiddenids[j],self.urlids[k],1,self.wo[j][k])
self.con.commit()
#聚集各类方法 输入单词ID urlid 选择的url
def trainquery(self,wordids,urlids,selectedurl):
#如有必要,生成一个隐藏节点
self.generatehiddennode(wordids,urlids)
self.setupnetwork(wordids,urlids)
self.feedforward()
targets=[0.0]*len(urlids)
targets[urlids.index(selectedurl)]=1.0
self.backPropagate(targets)
self.updatedatabase()
与搜索引擎结合
(1)让排序的结果输出,主要还是为了返回单词ID和urlid(好像可以不需要。。。)
#输出排序后的结果
def query(self,q):
rows,wordids=self.getmatchrows(q)
scores=self.getscoredlist(rows,wordids)
rankedscores=sorted([(score,url) for (url,score) in scores.items()],reverse=1)
for (score,urlid) in rankedscores[0:10]:
print('%f\t%d %s' %(score,urlid,self.geturlname(urlid)))
#返回单词ID以及urlID
return wordids,[r[1] for r in rankedscores[0:10]]
(2)建立一个新的基于神经网络的评分算法
#利用神经网络去进行排序
def nnscore(self,rows,wordids):
#获得一个由唯一的URL ID构成的有序列表
urlids=[urlid for urlid in set([row[0] for row in rows])]
nnres=mynet.getresult(wordids,urlids)
scores=dict([(urlids[i],nnres[i]) for i in range(len(urlids))])
return self.normalizescores(scores)
(3)更改weights,训练后排序输出
e=searcher('searchindex.db')
rows,wordids=e.getmatchrows("functional programming")
urlids=[]
for row in rows:
urlids.append(row[0])
#给urlids去重 重复的节点过多会对神经网络有影响
t=set(urlids)
urlids=list(t)
for i in range(5):
mynet.trainquery(wordids,urlids,220)
#打印出来的应该是[(x1,x2,x3)...]的形式
#其中x1表示url的id,具体url可用过id在urllist中找到
#x2表示查询的第一个单词在该url对应的网页提取出来的文本的具体位置
#x3表示查询的第二个单词在该url对应的网页提取出来的文本的具体位置
#print(e.getmatchrows("functional programming"))
#输出查询到的排在前十的url
e.query("functional programming")
#e.calculatepagerank()
这神经网络搞了半天。。。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









