







本文目录如下:
一、赛事背景
广告推荐主要基于用户对广告的历史曝光、点击等行为进行建模,如果只是使用广告域数据,用户行为数据稀疏,行为类型相对单一。而引入同一媒体的跨域数据,可以获得同一广告用户在其他域的行为数据,深度挖掘用户兴趣,丰富用户行为特征。引入其他媒体的广告用户行为数据,也能丰富用户和广告特征。本赛题希望选手基于广告日志数据,用户基本信息和跨域数据优化广告ctr预估准确率。目标域为广告域,源域为信息流推荐域,通过获取用户在信息流域中曝光、点击信息流等行为数据,进行用户兴趣建模,帮助广告域ctr的精准预估。比赛官网链接。
二、解决方案
基于鱼佬提供的2.1版本baseline代码,我做了进一步改进得到了以下的解决方案。
2.1 导入必要的库
#---------------------------------------------------
#导入库
#----------------数据探索----------------
import pandas as pd
import numpy as np
import os
import gc
import matplotlib.pyplot as plt
from tqdm import *
import featuretools as ft
#----------------核心模型----------------
from catboost import CatBoostClassifier
from sklearn.linear_model import SGDRegressor, LinearRegression, Ridge
#----------------交叉验证----------------
from sklearn.model_selection import StratifiedKFold, KFold
#----------------评估指标----------------
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score, log_loss
#----------------忽略报警----------------
import warnings
warnings.filterwarnings('ignore')
2.2 数据读取
# 读取训练数据和测试数据
train_data_ads = pd.read_csv('./train/train_data_ads.csv')
train_data_feeds = pd.read_csv('./train/train_data_feeds.csv')
test_data_ads = pd.read_csv('./test/test_data_ads.csv')
test_data_feeds = pd.read_csv('./test/test_data_feeds.csv')
train_data_ads.head(10)
| log_id | label | user_id | age | gender | residence | city | city_rank | series_dev | series_group | ... | ad_click_list_v001 | ad_click_list_v002 | ad_click_list_v003 | ad_close_list_v001 | ad_close_list_v002 | ad_close_list_v003 | pt_d | u_newsCatInterestsST | u_refreshTimes | u_feedLifeCycle | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 373250 | 0 | 100005 | 3 | 2 | 16 | 147 | 2 | 32 | 6 | ... | 30157^30648^14278^31706 | 2066^1776^1036 | 114^219^312 | 24107 | 1218 | 173 | 202206030326 | 39^220^16 | 0 | 15 |
| 1 | 373253 | 1 | 100005 | 3 | 2 | 16 | 147 | 2 | 32 | 6 | ... | 30157^30648^14278^31706 | 2066^1776^1036 | 114^219^312 | 24107 | 1218 | 173 | 202206030326 | 39^220^16 | 0 | 15 |
| 2 | 373252 | 1 | 100005 | 3 | 2 | 16 | 147 | 2 | 32 | 6 | ... | 30157^30648^14278^31706 | 2066^1776^1036 | 114^219^312 | 24107 | 1218 | 173 | 202206030326 | 39^220^16 | 0 | 15 |
| 3 | 373251 | 0 | 100005 | 3 | 2 | 16 | 147 | 2 | 32 | 6 | ... | 30157^30648^14278^31706 | 2066^1776^1036 | 114^219^312 | 24107 | 1218 | 173 | 202206030326 | 39^220^16 | 0 | 15 |
| 4 | 373255 | 0 | 100005 | 3 | 2 | 16 | 147 | 2 | 32 | 6 | ... | 30157^30648^14278^31706 | 2066^1776^1036 | 114^219^312 | 24107 | 1218 | 173 | 202206030328 | 39^220^16 | 0 | 15 |
| 5 | 373254 | 0 | 100005 | 3 | 2 | 16 | 147 | 2 | 32 | 6 | ... | 30157^30648^14278^31706 | 2066^1776^1036 | 114^219^312 | 24107 | 1218 | 173 | 202206030326 | 39^220^16 | 0 | 15 |
| 6 | 101100 | 0 | 100006 | 5 | 2 | 13 | 191 | 4 | 32 | 6 | ... | 28554^22548^13312^29694^11623 | 1776^1696^1230^1886 | 219^349^198^314 | 24107 | 1218 | 173 | 202206030844 | 39^78^220^142^16 | 3 | 17 |
| 7 | 101097 | 0 | 100006 | 5 | 2 | 13 | 191 | 4 | 32 | 6 | ... | 28554^22548^13312^29694^11623 | 1776^1696^1230^1886 | 219^349^198^314 | 24107 | 1218 | 173 | 202206030359 | 39^78^220^142^16 | 3 | 17 |
| 8 | 101098 | 0 | 100006 | 5 | 2 | 13 | 191 | 4 | 32 | 6 | ... | 28554^22548^13312^29694^11623 | 1776^1696^1230^1886 | 219^349^198^314 | 24107 | 1218 | 173 | 202206030916 | 39^78^220^142^16 | 3 | 17 |
| 9 | 101094 | 0 | 100006 | 5 | 2 | 13 | 191 | 4 | 32 | 6 | ... | 28554^22548^13312^29694^11623 | 1776^1696^1230^1886 | 219^349^198^314 | 24107 | 1218 | 173 | 202206030914 | 39^78^220^142^16 | 3 | 17 |
10 rows × 35 columns
train_data_feeds.head(10)
| u_userId | u_phonePrice | u_browserLifeCycle | u_browserMode | u_feedLifeCycle | u_refreshTimes | u_newsCatInterests | u_newsCatDislike | u_newsCatInterestsST | u_click_ca2_news | ... | e_ch | e_m | e_po | e_pl | e_rn | e_section | e_et | label | cillabel | pro | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 135880 | 16 | 17 | 10 | 17 | 0 | 195^168^109^98^108 | 0 | 195^44^168^112^21 | 195^168^44^112^21 | ... | 19 | 1217 | 1 | 561 | 2 | 0 | 202206081521 | -1 | -1 | 0 |
| 1 | 135880 | 16 | 17 | 10 | 17 | 0 | 195^168^109^98^108 | 0 | 195^44^168^112^21 | 195^168^44^112^21 | ... | 19 | 1217 | 9 | 561 | 1 | 0 | 202206081521 | -1 | -1 | 0 |
| 2 | 135880 | 16 | 17 | 10 | 17 | 0 | 195^168^109^98^108 | 0 | 195^44^168^112^21 | 195^168^44^112^21 | ... | 19 | 1217 | 18 | 561 | 1 | 0 | 202206081521 | -1 | -1 | 0 |
| 3 | 135880 | 16 | 17 | 10 | 17 | 0 | 195^168^109^98^108 | 0 | 195^44^168^112^21 | 195^168^44^112^21 | ... | 19 | 1217 | 7 | 561 | 1 | 1 | 202206081521 | -1 | -1 | 0 |
| 4 | 135880 | 16 | 17 | 10 | 17 | 0 | 195^168^109^98^108 | 0 | 195^44^168^112^21 | 195^168^44^112^21 | ... | 19 | 1217 | 7 | 561 | 2 | 0 | 202206081522 | -1 | -1 | 0 |
| 5 | 135880 | 16 | 17 | 10 | 17 | 0 | 195^168^109^98^108 | 0 | 195^44^168^112^21 | 195^168^44^112^21 | ... | 19 | 1217 | 13 | 561 | 1 | 0 | 202206081521 | -1 | -1 | 0 |
| 6 | 135880 | 16 | 17 | 10 | 17 | 0 | 195^168^109^98^108 | 0 | 195^44^168^112^21 | 195^168^44^112^21 | ... | 19 | 1217 | 5 | 561 | 3 | 0 | 202206081522 | -1 | -1 | 0 |
| 7 | 135880 | 16 | 17 | 10 | 17 | 0 | 195^168^109^98^108 | 0 | 195^44^168^112^21 | 195^168^44^112^21 | ... | 19 | 1217 | 17 | 561 | 1 | 0 | 202206081521 | -1 | -1 | 0 |
| 8 | 135880 | 16 | 17 | 10 | 17 | 0 | 195^168^109^98^108 | 0 | 195^44^168^112^21 | 195^168^44^112^21 | ... | 19 | 1217 | 6 | 561 | 1 | 1 | 202206081520 | -1 | -1 | 0 |
| 9 | 135880 | 16 | 17 | 10 | 17 | 0 | 195^168^109^98^108 | 0 | 195^44^168^112^21 | 195^168^44^112^21 | ... | 19 | 1217 | 4 | 561 | 3 | 0 | 202206081522 | -1 | -1 | 0 |
10 rows × 28 columns
# 合并数据
train_data_ads['istest'] = 0
test_data_ads['istest'] = 1
data_ads = pd.concat([train_data_ads, test_data_ads], axis=0, ignore_index=True)
train_data_feeds['istest'] = 0
test_data_feeds['istest'] = 1
data_feeds = pd.concat([train_data_feeds, test_data_feeds], axis=0, ignore_index=True)
del train_data_ads, test_data_ads, train_data_feeds, test_data_feeds
gc.collect()
522
def reduce_mem_usage(df, verbose=True):
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
if verbose: print('Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)'.format(end_mem, 100 * (start_mem - end_mem) / start_mem))
return df
2.3 特征工程
自然数编码
将文本变量数值化,方便后续计算。
# 自然数编码
def label_encode(series, series2):
unique = list(series.unique())
return series2.map(dict(zip(
unique, range(series.nunique())
)))
for col in ['ad_click_list_v001','ad_click_list_v002','ad_click_list_v003','ad_close_list_v001','ad_close_list_v002','ad_close_list_v003','u_newsCatInterestsST']:
data_ads[col] = label_encode(data_ads[col], data_ads[col])
目标域(广告域)穿越特征提取
由于这个数据的变量里有时间戳,所以我们可以统计用户两次行为之间的时间差来构建穿越特征。

穿越特征是一个非常强的特征,用了之后我的结果从0.72提升到了0.79,虽然没有鱼佬提升0.1那么厉害,但也说明这个穿越特征的重要性了。
浅薄理解:穿越特征本质就是时序特征,由于有了时间的加入,因此我们可以利用样本 t t t的历史数据 t − n , … , t − 1 t-n, \dots, t-1 t−n,…,t−1来更好地预测 t t t时刻的结果。类似的方法还有做差分、构建多阶滞后数据等。
Trick:这里的代码不仅构建了历史数据的穿越特征,还加入了 t t t时刻之后的穿越特征,也就是把未来的数据也加入到训练过程中,因此结果表现亮眼。但平心而论,这已经发生数据泄露了,因为工业上实际预测时不可能有未来的数据给你辅助预测。
%%time
gap_max = 4
gap_list = list(range(1, gap_max+1)) #穿越的间隔
print(f'间隔列表:{gap_list}')
print(data_ads.columns)
# 要找哪些不适合构建穿越特征
col_ads_deprecated = ['label', 'istest','age','gender','pt_d', 'log_id','residence','city','city_rank',
'series_dev','series_group','emui_dev','device_name','device_size', 'site_id',
'ad_close_list_v002', 'ad_close_list_v003', 'net_type',
'u_feedLifeCycle','hispace_app_tags', 'app_second_class', 'app_score',
]
cols = [f for f in data_ads.columns if f not in col_ads_deprecated]
print(f'用来构建穿越特征的广告域变量有{len(cols)}个,分别是:{cols}')
print(f'data_ads.shape = {data_ads.shape}')
print(f'data_feeds.shape = {data_feeds.shape}')
## 构建穿越特征
for col in tqdm(cols):
for gap in gap_list:
tmp = data_ads.groupby([col])['pt_d'].shift(-gap) #往左移动,即未来时刻的数据
data_ads['ts_{}_{}_diff_last'.format(col, gap)] = tmp - data_ads['pt_d'] #上一条样本到本条样本的时间差
for gap in gap_list:
tmp = data_ads.groupby([col])['pt_d'].shift(+gap) #往右移动,即过去时刻的数据
data_ads['ts_{}_{}_diff_next'.format(col, gap)] = tmp - data_ads['pt_d'] #上一条样本到本条样本的时间差
间隔列表:[1, 2, 3, 4]
Index(['log_id', 'label', 'user_id', 'age', 'gender', 'residence', 'city',
'city_rank', 'series_dev', 'series_group', 'emui_dev', 'device_name',
'device_size', 'net_type', 'task_id', 'adv_id', 'creat_type_cd',
'adv_prim_id', 'inter_type_cd', 'slot_id', 'site_id', 'spread_app_id',
'hispace_app_tags', 'app_second_class', 'app_score',
'ad_click_list_v001', 'ad_click_list_v002', 'ad_click_list_v003',
'ad_close_list_v001', 'ad_close_list_v002', 'ad_close_list_v003',
'pt_d', 'u_newsCatInterestsST', 'u_refreshTimes', 'u_feedLifeCycle',
'istest'],
dtype='object')
用来构建穿越特征的广告域变量有14个,分别是:['user_id', 'task_id', 'adv_id', 'creat_type_cd', 'adv_prim_id', 'inter_type_cd', 'slot_id', 'spread_app_id', 'ad_click_list_v001', 'ad_click_list_v002', 'ad_click_list_v003', 'ad_close_list_v001', 'u_newsCatInterestsST', 'u_refreshTimes']
data_ads.shape = (8651575, 36)
data_feeds.shape = (3597073, 29)
100%|██████████| 14/14 [00:43<00:00, 3.08s/it]
CPU times: user 32.6 s, sys: 10.5 s, total: 43.1 s
Wall time: 43.1 s
注:col_ads_deprecated为经过特征重要性结果筛选出来的较为不重要的特征,为防止维度爆炸和占内存,这里就不对这些不重要的变量构建穿越特征了。
内存压缩
此时的数据占用内存比较大了,先压缩一遍防止爆内存。
# 压缩使用内存
data_ads = reduce_mem_usage(data_ads)
print(f'data_ads.shape = {data_ads.shape}')
# Mem. usage decreased to 2351.47 Mb (69.3% reduction)
Mem. usage decreased to 3655.10 Mb (62.6% reduction)
data_ads.shape = (8651575, 148)
源域特征构建
源域即为信息域,目标域为广告域。这两者的关系就好比,你刷淘宝(源域),支付宝(广告域)根据你在淘宝的行为来给你推送广告。
源域可以提取的特征类型有:去重计数特征nunique,计数count,均值mean,最大值max,最小值min,方差std,是否为工作日weekday等。
print(f'data_feeds.shape = ',data_feeds.shape)
print(f'data_ads.shape = ',data_ads.shape)
print('信息域特征:')
print(data_feeds.columns)
## 去重计数特征
cols = [f for f in data_feeds.columns if f not in [ 'u_phonePrice', 'u_browserLifeCycle', 'u_browserMode',
'u_feedLifeCycle', 'u_refreshTimes', 'u_newsCatInterests','u_newsCatDislike','i_dislikeTimes','u_userId',
'i_dtype', 'e_ch', 'e_m', 'e_pl', 'e_rn', 'e_section', 'label', 'cillabel', 'pro', 'istest']]
print(f'用来构建nunique特征的源域变量有{len(cols)}个,分别是:{cols}')
for col in tqdm(cols):
tmp = data_feeds.groupby(['u_userId'])[col].nunique().reset_index() #无重复值
tmp.columns = ['user_id', col+'_feeds_nuni']
data_ads = data_ads.merge(tmp, on='user_id', how='left')
## 均值特征
cols = [f for f in data_feeds.columns if f in ['i_upTimes', 'u_refreshTimes']]
print(f'用来构建mean特征的源域变量有{len(cols)}个,分别是:{cols}')
for col in tqdm(cols):
tmp = data_feeds.groupby(['u_userId'])[col].mean().reset_index()
tmp.columns = ['user_id', col+'_feeds_mean']
data_ads = data_ads.merge(tmp, on='user_id', how='left')
print(f'data_feeds.shape = ',data_feeds.shape)
print(f'data_ads.shape = ',data_ads.shape)
data_feeds.shape = (3597073, 29)
data_ads.shape = (8651575, 148)
信息域特征:
Index(['u_userId', 'u_phonePrice', 'u_browserLifeCycle', 'u_browserMode',
'u_feedLifeCycle', 'u_refreshTimes', 'u_newsCatInterests',
'u_newsCatDislike', 'u_newsCatInterestsST', 'u_click_ca2_news',
'i_docId', 'i_s_sourceId', 'i_regionEntity', 'i_cat', 'i_entities',
'i_dislikeTimes', 'i_upTimes', 'i_dtype', 'e_ch', 'e_m', 'e_po', 'e_pl',
'e_rn', 'e_section', 'e_et', 'label', 'cillabel', 'pro', 'istest'],
dtype='object')
用来构建nunique特征的源域变量有10个,分别是:['u_newsCatInterestsST', 'u_click_ca2_news', 'i_docId', 'i_s_sourceId', 'i_regionEntity', 'i_cat', 'i_entities', 'i_upTimes', 'e_po', 'e_et']
100%|██████████| 10/10 [01:56<00:00, 11.65s/it]
用来构建mean特征的源域变量有2个,分别是:['u_refreshTimes', 'i_upTimes']
100%|██████████| 2/2 [00:20<00:00, 10.35s/it]
data_feeds.shape = (3597073, 29)
data_ads.shape = (8651575, 160)
内存压缩
合并源域的特征后,此时的数据已经占用了10多个G的内存,在进模型之前再压缩一遍内存。
# 压缩使用内存
print(f'data_ads.shape = {data_ads.shape}')
print(f'data_feeds.shape = {data_feeds.shape}')
data_ads = reduce_mem_usage(data_ads)
# Mem. usage decreased to 2351.47 Mb (69.3% reduction)
data_ads.shape = (8651575, 160)
data_feeds.shape = (3597073, 29)
Mem. usage decreased to 3894.37 Mb (13.7% reduction)
2.4 划分训练集和测试集
# 划分训练集和测试集
cols = [f for f in data_ads.columns if f not in ['label','istest']]
X_train = data_ads[data_ads.istest==0][cols]
X_test = data_ads[data_ads.istest==1][cols]
Y_train = data_ads[data_ads.istest==0]['label']
print('X_train.shape = ', X_train.shape)
print('Y_train.shape = ', Y_train.shape)
print('X_test.shape = ', X_test.shape)
del data_ads, data_feeds
gc.collect()
val_counts = Y_train.value_counts()
print(val_counts)
ratio = val_counts[1] / len(Y_train)
print(f'正样本个数:{val_counts[1]},样本总数:{Y_train.shape[0]},点击率:{ratio*100}%')
X_train.shape = (7675517, 158)
Y_train.shape = (7675517,)
X_test.shape = (976058, 158)
0.0 7556381
1.0 119136
Name: label, dtype: int64
正样本个数:119136,样本总数:7675517,点击率:1.552156030662169%
2.5 训练模型
配置说明:服务器6核CPU,英伟达A4000显卡,显存16G,内存30G,模型训练耗时20min左右。
def cv_model(clf, train_x, train_y, test_x, clf_name, seed=2022):
kf = StratifiedKFold(n_splits=5, shuffle=True, random_state=seed)
train = np.zeros(train_x.shape[0])
test = np.zeros(test_x.shape[0])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ Fold: {}************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
params = {'learning_rate': 0.3, 'depth': 7, 'l2_leaf_reg': 10, 'bootstrap_type':'Bernoulli','random_seed':seed,
'od_type': 'Iter', 'early_stopping_rounds' : 100, 'random_seed': 11, 'allow_writing_files': False, 'task_type':'GPU'}
model = clf(iterations=20000, **params, eval_metric='AUC')
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
metric_period=200,
cat_features=[],
use_best_model=True,
verbose=1)
val_pred = model.predict_proba(val_x)[:,1]
test_pred = model.predict_proba(test_x)[:,1]
train[valid_index] = val_pred
test += test_pred / kf.n_splits
cv_scores.append(roc_auc_score(val_y, val_pred))
print('Fold: ', i+1, ', cv_scores: ', cv_scores)
print("%s_score_list:" % clf_name, cv_scores)
print("%s_score_mean:" % clf_name, np.mean(cv_scores))
print("%s_score_std:" % clf_name, np.std(cv_scores))
return train, test, model
%%time
cat_train, cat_test, model_cat = cv_model(CatBoostClassifier, X_train, Y_train, X_test, "CatBoost")
************************************ Fold: 1************************************
0: test: 0.7189325 best: 0.7189325 (0) total: 65.2ms remaining: 21m 44s
200: test: 0.8568486 best: 0.8568486 (200) total: 11.1s remaining: 18m 10s
400: test: 0.8603237 best: 0.8603237 (400) total: 22.1s remaining: 17m 58s
600: test: 0.8611539 best: 0.8612658 (566) total: 33s remaining: 17m 44s
800: test: 0.8613431 best: 0.8614171 (774) total: 44.3s remaining: 17m 41s
bestTest = 0.8614170849
bestIteration = 774
Shrink model to first 775 iterations.
Fold: 1 , cv_scores: [0.8614170406506998]
************************************ Fold: 2************************************
0: test: 0.7211291 best: 0.7211291 (0) total: 63.7ms remaining: 21m 13s
200: test: 0.8612604 best: 0.8612604 (200) total: 11.1s remaining: 18m 17s
400: test: 0.8640077 best: 0.8640400 (373) total: 22s remaining: 17m 55s
600: test: 0.8653538 best: 0.8653761 (597) total: 33s remaining: 17m 46s
800: test: 0.8659144 best: 0.8660083 (764) total: 44.1s remaining: 17m 38s
bestTest = 0.8660082817
bestIteration = 764
Shrink model to first 765 iterations.
Fold: 2 , cv_scores: [0.8614170406506998, 0.8660083224675101]
************************************ Fold: 3************************************
0: test: 0.7199210 best: 0.7199210 (0) total: 62.8ms remaining: 20m 54s
200: test: 0.8606131 best: 0.8606131 (200) total: 11.1s remaining: 18m 8s
400: test: 0.8643171 best: 0.8643319 (398) total: 22.1s remaining: 17m 58s
600: test: 0.8649400 best: 0.8650057 (577) total: 32.9s remaining: 17m 43s
800: test: 0.8653334 best: 0.8653587 (793) total: 44s remaining: 17m 33s
bestTest = 0.8653598428
bestIteration = 836
Shrink model to first 837 iterations.
Fold: 3 , cv_scores: [0.8614170406506998, 0.8660083224675101, 0.8653597903214642]
************************************ Fold: 4************************************
0: test: 0.7193976 best: 0.7193976 (0) total: 65.9ms remaining: 21m 58s
200: test: 0.8614899 best: 0.8614899 (200) total: 11.1s remaining: 18m 11s
400: test: 0.8645635 best: 0.8645635 (400) total: 21.9s remaining: 17m 52s
600: test: 0.8654521 best: 0.8654521 (600) total: 32.9s remaining: 17m 43s
800: test: 0.8661223 best: 0.8661552 (756) total: 44.2s remaining: 17m 39s
bestTest = 0.8661551774
bestIteration = 756
Shrink model to first 757 iterations.
Fold: 4 , cv_scores: [0.8614170406506998, 0.8660083224675101, 0.8653597903214642, 0.8661551906990169]
************************************ Fold: 5************************************
0: test: 0.7192921 best: 0.7192921 (0) total: 64.8ms remaining: 21m 36s
200: test: 0.8610862 best: 0.8610862 (200) total: 11s remaining: 18m 7s
400: test: 0.8647963 best: 0.8647963 (400) total: 22.1s remaining: 17m 59s
600: test: 0.8656041 best: 0.8656041 (600) total: 33.1s remaining: 17m 47s
bestTest = 0.8656666577
bestIteration = 642
Shrink model to first 643 iterations.
Fold: 5 , cv_scores: [0.8614170406506998, 0.8660083224675101, 0.8653597903214642, 0.8661551906990169, 0.8656667777361056]
CatBoost_score_list: [0.8614170406506998, 0.8660083224675101, 0.8653597903214642, 0.8661551906990169, 0.8656667777361056]
CatBoost_score_mean: 0.8649214243749593
CatBoost_score_std: 0.001773806552522081
CPU times: user 24min 6s, sys: 2min 35s, total: 26min 41s
Wall time: 18min 8s
2.5 输出特征重要性结果
importances = model_cat.feature_importances_
plt.figure(figsize=(24,60), dpi=80)
plt.rc('font', size = 18)
plt.barh(X_train.columns, importances)
plt.title('Feature importances computed by CatBoost')
plt.savefig('feature_importances.png')
# plt.show()
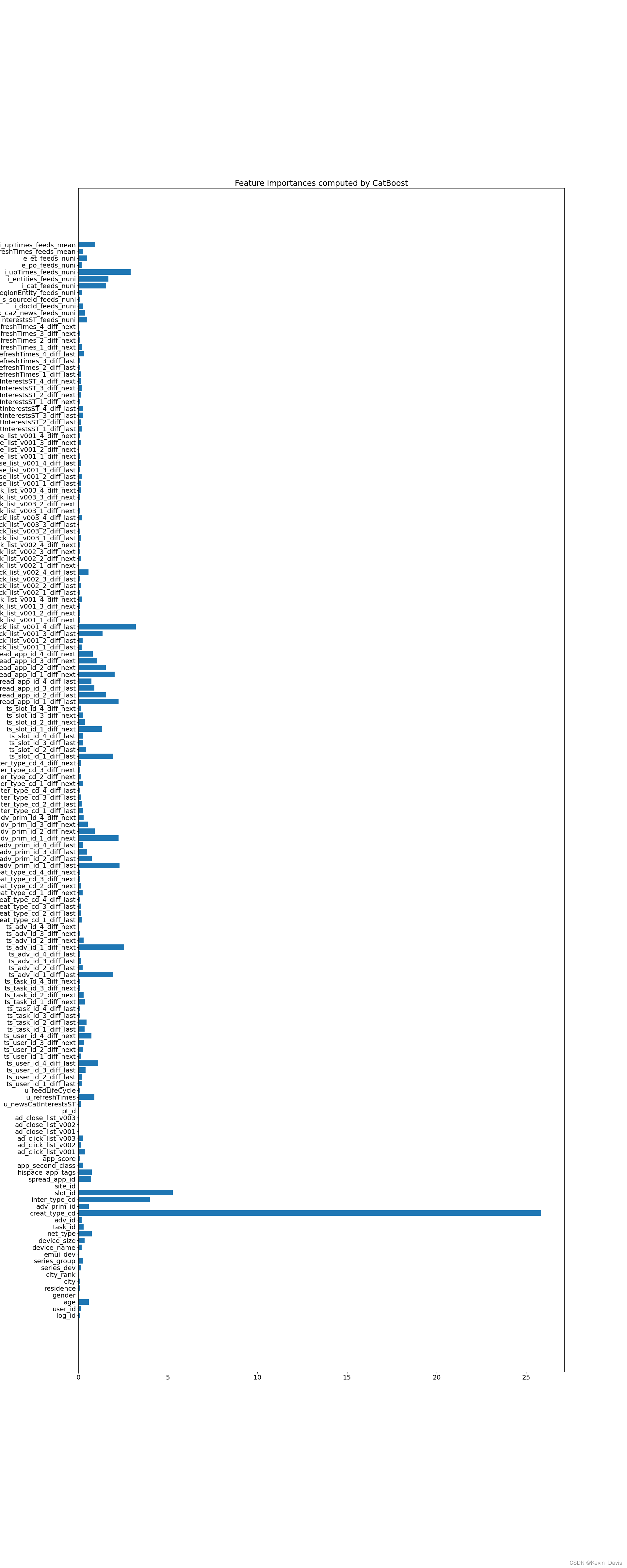
ranks = pd.DataFrame({'feature':X_train.columns, 'importance':importances})
ranks.sort_values(by=['importance'], ascending=False)[0:20]
| feature | importance | |
|---|---|---|
| 15 | creat_type_cd | 25.840919 |
| 18 | slot_id | 5.278525 |
| 17 | inter_type_cd | 3.995419 |
| 101 | ts_ad_click_list_v001_4_diff_last | 3.205468 |
| 153 | i_upTimes_feeds_nuni | 2.922680 |
| 54 | ts_adv_id_1_diff_next | 2.548166 |
| 66 | ts_adv_prim_id_1_diff_last | 2.305442 |
| 70 | ts_adv_prim_id_1_diff_next | 2.237118 |
| 90 | ts_spread_app_id_1_diff_last | 2.233946 |
| 94 | ts_spread_app_id_1_diff_next | 2.032714 |
| 50 | ts_adv_id_1_diff_last | 1.929151 |
| 82 | ts_slot_id_1_diff_last | 1.926440 |
| 152 | i_entities_feeds_nuni | 1.685816 |
| 151 | i_cat_feeds_nuni | 1.557056 |
| 91 | ts_spread_app_id_2_diff_last | 1.553180 |
| 95 | ts_spread_app_id_2_diff_next | 1.529100 |
| 100 | ts_ad_click_list_v001_3_diff_last | 1.342199 |
| 86 | ts_slot_id_1_diff_next | 1.328587 |
| 37 | ts_user_id_4_diff_last | 1.112328 |
| 96 | ts_spread_app_id_3_diff_next | 1.045964 |
result_importance = pd.DataFrame({'feature':X_train.columns, 'importance':importances})
result_importance.to_csv('feature_importance.csv', index=False)
print('Saved.')
Saved.
2.6 结果保存
X_test['pctr'] = cat_test
X_test[['log_id','pctr']].to_csv('submission.csv', index=False)
print('Done.')
Done.
三、总结
这次比赛我的最好结果为0.794884,一直没有突破0.8大关,有点遗憾。但也从这次比赛学到了许多,最重要的是了解掌握了一些特征工程的方法,算是半只脚踏进了推荐系统。
未来还可以提升的方向:
- 特征工程:还有一些特征我可能没注意到,比如是否工作日,穿越特征按天或按小时来算等。
- 模型:由于时间关系,这次只尝试了CatBoost模型(快),还有很多其他模型可以尝试,比如DeepFM、DCN等。
- 模型融合:比如Bagging、Stacking等。
欢迎各位大佬在评论区留言赐教。
参考资料
[1 鱼佬带你高分突破:广告信息流跨域ctr预估
[2] Datawhale_零基础入门推荐系统竞赛实践
[3] Coggle 30 Days of ML(22年8月)
















 462
462











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











