






 CTR预估是广告系统的核心,涉及用户、广告和上下文的点击概率预测。技术经历了LogisticRegression、交叉特征到深度学习的演变,包括兴趣建模、多目标建模、交叉特征、多场景适应等方法。在线学习和大模型架构也是关键研究方向,同时,评估指标如Logloss、AUC和GAUC衡量模型性能。
CTR预估是广告系统的核心,涉及用户、广告和上下文的点击概率预测。技术经历了LogisticRegression、交叉特征到深度学习的演变,包括兴趣建模、多目标建模、交叉特征、多场景适应等方法。在线学习和大模型架构也是关键研究方向,同时,评估指标如Logloss、AUC和GAUC衡量模型性能。
1 CTR预估简介
在搜索、推荐、广告领域,预估技术一直是非常重要的模块,规模比较大的互联网公司如谷歌、FB、阿里、字节等依靠广告系统带来了百亿乃至千亿以上美元的营收。在广告系统中,最后展示给用户的广告(如商品、视频、图文)往往需要经过大规模精细化的排序计算。在现在大多数CPC(Cost Per Click)计费的广告系统中,广告往往通过eCPM(千次展现计费价值)进行最终排序,eCPM主要由pCtr和bid两部分相乘得到,bid往往取决于商品自身的价值或广告主的预算成本,而pCtr则由广告系统计算得出。事实上,精准的pCtr结果能给商业公司带来极大的收益提升。
传统的CTR预估定义主要分两种,在搜索广告中,我们定义
pCtr=P(click|q,u,a)
,部分定义为
pCtr=P(click|q,a)
,其中
q
代表query,
u
代表用户,
a
代表广告。在推荐广告中,我们定义
pCtr=P(click|u,a,c)
,其中
u
代表用户,
a
代表广告,
c
代表上下文。无论是以上的哪种,CTR预估都可以看作是建模一个用户对商品的点击概率,这是一个经过深度定义的机器学习问题。
在大规模机器学习时代,CTR技术主要经过了三个阶段,我们称之为1.0阶段、2.0阶段、3.0阶段。1.0阶段是大规模Logistic Regression+海量特征时期(2010-2014),其中最具代表性的系统是谷歌的Ads Word和百度的凤巢系统。2.0阶段是交叉特征阶段,FM、FFM、NFM以及MLR等模型提出,自动化地进行二阶的特征交叉来捕获用户和商品的交互信息。在3.0阶段,深度学习模型被引入,在CV、NLP方向中取得了极大成功的技术也被迁移到CTR预估领域,ResNet、Attention、Transformer、Bert等技术以及Embedding&MLP的模型范式已经成为现阶段主流公司的main traffic choose。
2 CTR预估在广告系统中的位置
3.0阶段的现代推荐系统往往由级联的模块组成,用户打开一个APP或者搜索页面,其看到的结果往往由召回、粗排、精排、重排、出价等模块进行漏斗式过滤生成。传统的CTR预估技术往往特指粗排、精排等排序方向的技术,但模型排序、预估技术本身在召回、出价等模块也有广泛的应用。
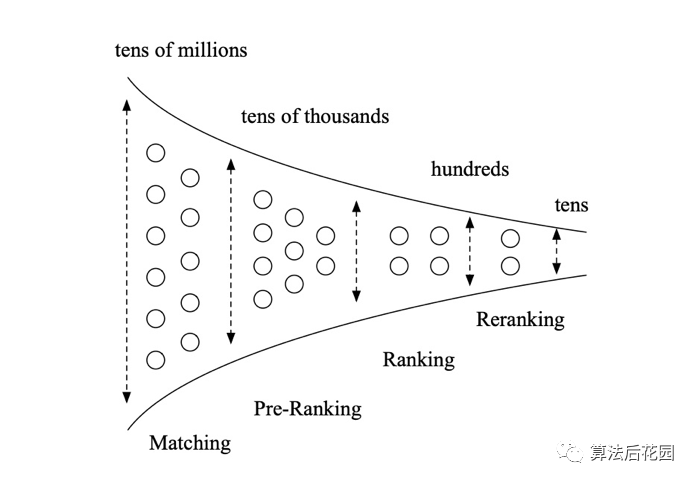
3 CTR预估技术体系
3.1 算法篇
在反向传播 BP以及卷积神经网络(AlexNet)带来人脸识别的巨大突破以后,深度学习在图像、语音、自然语言处理取得了巨大的成功。搜索、推荐、广告领域的专家们也看到了相应的机会,遵循“数据-特征-模型结构”的机器学习范式,也取得了很大的收益。不同于图像的像素、语音的音素、自然语言处理中的单词,用户在互联网APP的曝光、点击、浏览、购买等行为数据天然具有正样本少、信息不完备、数据量大等特点。
当前比较火的CTR算法Topic大概包含以下几个方向:
(1) 兴趣建模 用户的行为序列是用户在互联网APP信息度最高的特征集合,如何有效的通过用户在APP上的点击、购买等行为抽取出用户对商品的点击趋势是CTR预估领域经久不衰的问题。
(2)多目标建模 多目标建模是MTL(Multi-Task Learning)在CTR领域中的重要应用,在互联网商业竞争越来越激烈的时代,除点击以外,播放时长、购买、收藏、评论等目标也越来越重要。在多目标建模中,多个目标之间往往相互制约,存在跷跷板(seesaw)现象,如何能最大化地利用数据在整体上带来收益最大化,是Multi-Task Learning应用的关键。
(3)交叉特征建模 在互联网CTR预估1.0阶段,手动海量特征+LR是非常有效的方式。2.0阶段的FM、MLR等提供了二阶的特征交叉方法,来捕获用户和商品的交互信息。在3.0阶段,深度学习神经网络相比浅层模型的巨大优势是在于宽深的网络结构,理论上深度学习能带来非常高阶的特征交叉,但是由于神经网络的训练存在局部最优的问题,仅仅依赖隐式的特征交叉往往不能带来最完美的效果,显示+隐式的交叉行为可以为CTR预估带来更好的效果。
(4)多场景建模/迁移学习/元学习 随着推荐广告业务场景的扩展,我们希望能将主场景的数据、模型能力赋能给更多的小业务场景,同时也带来人力成本、经济成本的节省,因此多场景建模是CTR预估非常重要的研究方向。元学习(Meta-Learning)也被称为Learn To Learn,与机器学习输出input和label的映射关系不同,元学习常见的输出是训练范式(比如一种好的梯度初始化方式MAML)。元学习最常见的应用方式就是在少量样本集合上快速训练达到一个较好的模型精度,由于工业界存在一类典型的小场景小样本CTR排序模型的场景,因此元学习也在大量的尝试被应用在CTR模型和冷启动中。迁移学习同样是将source domain的知识迁移到target domain的一种方式,多场景建模、元学习、迁移学习在工业界的应用往往是大数据带动小数据训练,大场景带动小场景提升模型精度,以及大小场景如何有效共享知识。
(5)动态参数建模 在排序模型中,我们往往在特征层面实现了不同的用户、商品有不同的输入信息,但我们的模型参数是同一套,如果能在模型层面给予个性化的参数结构,就能给CTR模型带来更大的表征能力,PPNet、APG是比较典型的个性化参数建模思路。
(6)输入端表征建模 Embedding&MLP范式下,如何有效地学习到一个更具有表征能力的embedding,同样能带来更好的模型效果?引入外部信息pretrain是最近非常火的一类做法。
(7)图神经网络 图神经网络在学术界是非常火的方向之一,图结构相比传统的线性结构,具有更强的现实表达能力。图天然在数据结构上具有邻域、多跳等特点,user和item都可以基于图的节点进行表示,从图中抽取出嵌入式信息进行建模,无论是在召回侧,还是在排序侧,都有很广泛的应用。
(8)因果推断 因果推断目前也是非常火的方向之一,工业界的模型训练大都是基于实际流量的数据进行有监督训练,但是观测数据往往是有偏的,例如用户倾向于和偏好的商品进行交互,这会导致训练空间和预测空间的样本分布不一致,产生选择偏差。针对观测数据的不完善问题,近年来工业界围绕“如何进行无偏学习”、“如何建模非显式行为影响”等方面进行了探索。
3.2 架构篇
(1)Online Learning 如何更快地捕获用户的数据分布?如何让模型更具有实效性?Online Learning一直是学术界和工业界非常热门的话题。工业界模型往往要经历日志回流、特征拼接、模型训练、模型校验、模型上线服务等流程,在一些时效性比较重要的APP(如Youtube、抖音等),实时捕获用户的兴趣是非常重要的议题,加速模型的train、serve流程,对最新样本的处理策略等等。
(2)大模型 从BERT到GPT-3,学术界已经验证了更多的模型参数大概率能带来更好的效果,工业界的embedding&mlp同样可以通过维度扩展、结构拓宽拓深带来一定程度的提升,但是在内存、CPU、RT等在线计算资源的约束下,如何能够更好地做大模型,是工业界比较典型的一类问题。
4 CTR预估评价
Logloss: 在CTR预估里常见的loss函数为Logloss,针对点击正负样本loss=-sum(label*log(pred))。
AUC:AUC是一种用于评价排序能力好坏的标准,AUC的计算与绝对值尺度无关,会计算在不同的threshold下,正样本(y坐标)以及负样本(x坐标)的值,并统计整体的面积。深入理解AUC推荐阅读:https://tracholar.github.io/machine-learning/2018/01/26/auc.html。
GAUC:即Group AUC,AUC并不完全对应线上一条请求的实际serve情况,互联网APP是以用户请求为初始单位的业务场景,因此,比起整体数据集合的AUC,在每个用户粒度,我们对候选集物品进行打分排序,带来AUC的提升,就会更接近于真实线上效果的提升。

















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









