







基于Scrapy-redis实现分布式爬虫
Scrapy是一个通用的爬虫框架,但其框架本身不支持分布式,为了提高爬取效率
① 充分利用多台机器的带宽速度爬取数据
② 充分利用多台机器的IP爬取
Python包要求:pymysql、redis、scrapy、re、urllib、json
Github地址:Lianjia_spider
Scrapy-Redis原理图
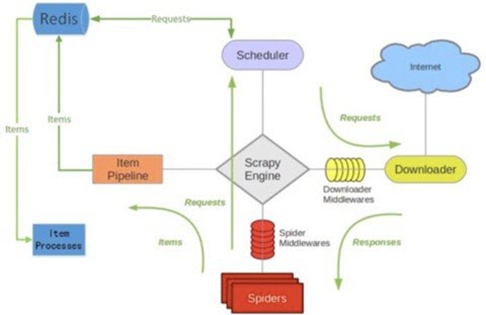
整体框架及逻辑
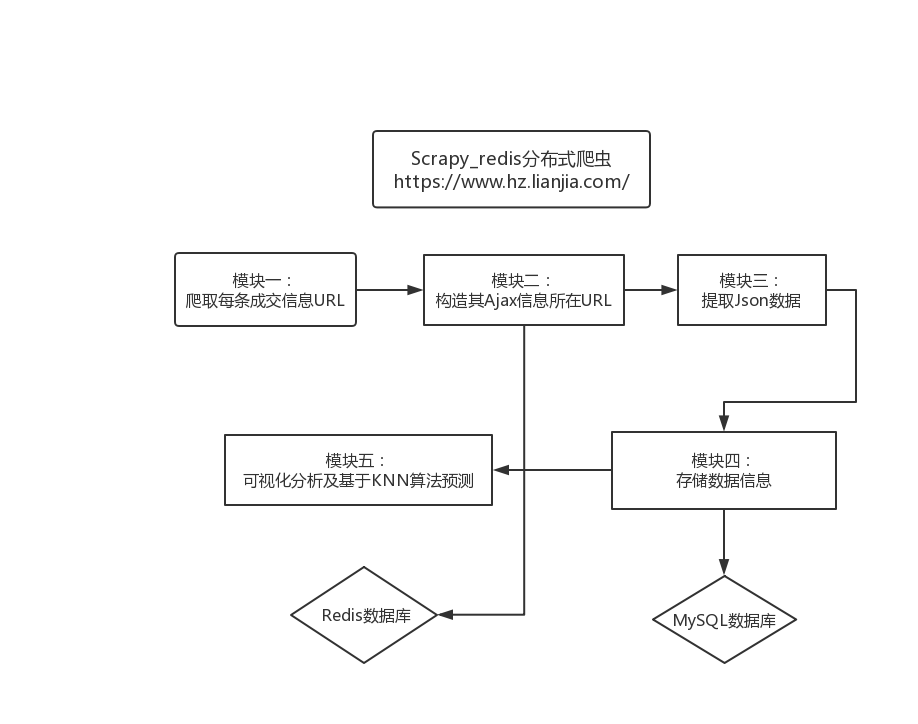
爬虫及数据可视化分析及预测
1.Lianjia_spider文件夹
- Lianjia_spider:scrapy-redis爬虫
- spiders文件夹:爬虫主体
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 778
778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









