







系列文章
Cluster analysis :Basic Concepts and Algorithms – Part 1 Overview
Cluster analysis :Basic Concepts and Algorithms – Part 2 K-means
Cluster analysis :Basic Concepts and Algorithms – Part 3 Hierarchical Clustering
CONTENTS
1 前言
之前两节讲的K-means是基于原型的划分的聚类,Hierarchical Clustering是层次(嵌套)的聚类,而本本节主要学习基于密度的聚类:寻找被低密度区域分离的高密度区域。

DBSCAN是其中的一种简单有效的基于密度的聚类方法(Density-based clustering)。它采用的是基于中心的点密度:点的密度是指给定半径范围(Eps)内点的个数。因此点的密度取决于指定的半径。
使用这个方法对区域中的点进行分成三类:
- 稠密区域内部的点,即核心点(a core point)。根据点的个数是否超过给定的阀值(MinPts)来确定。
- 稠密区域边缘上的点,即边界点(a border point)。它不是核心点,但是与核心点邻近的点
- 稀疏区域中的点,即噪声或者背景点(a noise or background point)。它既不是核心点,又不是边界点。
如下图中,当阀值为7时,A是核心点,B是边界点,C是噪声点。
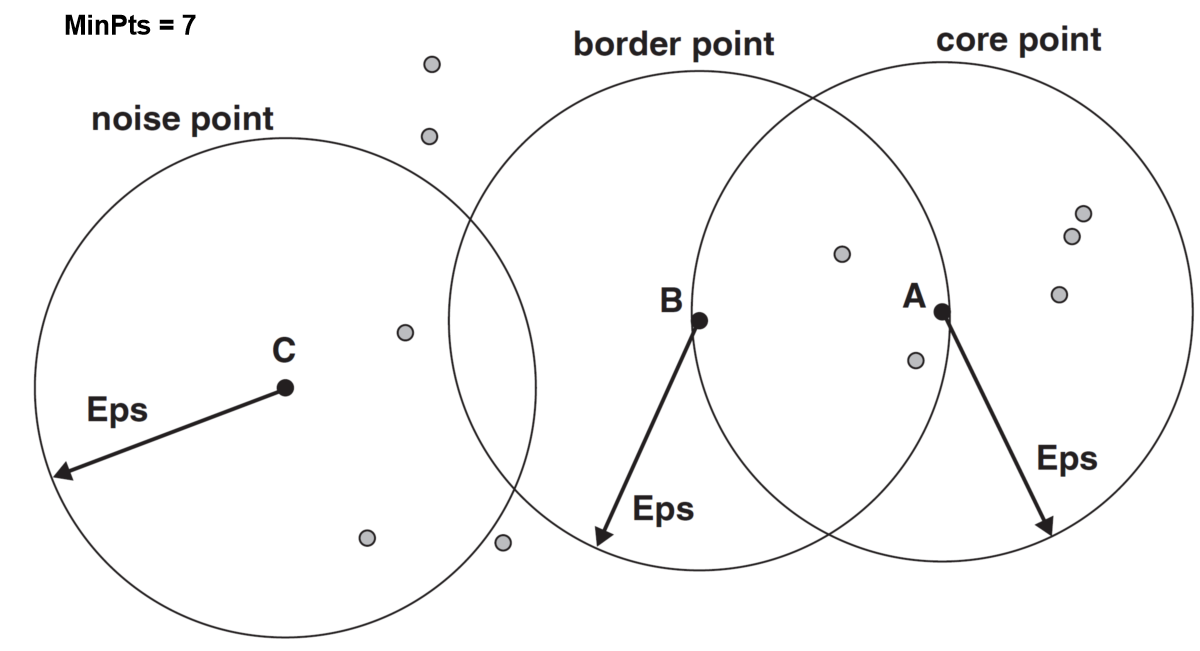
图1-1 DBSCAN 核心点、边界点和噪声点。
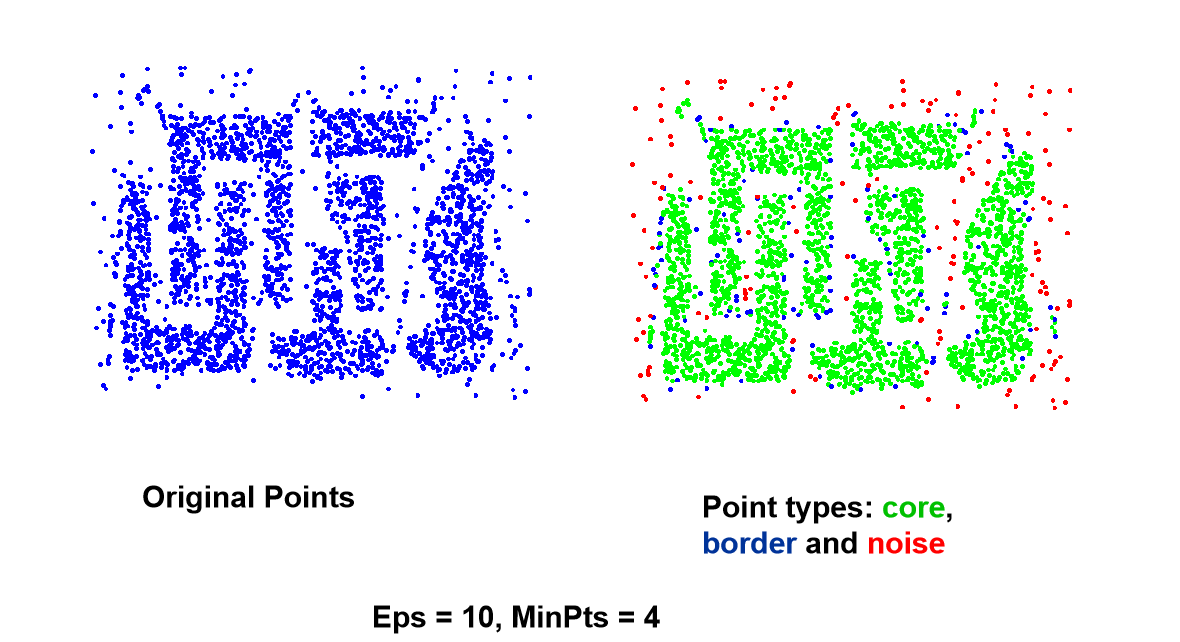
图1-2 DBSCAN 核心点、边界点和噪声点。
2 DBSCAN 聚类算法
简单来说就是: 先通过核心点来确定簇,然后把边界点分配到邻近的簇中。只要确定了核心点,边界点和噪声点,任何两个距离接近(即相互距离在Eps之内)的核心点都会被分到同一个簇。
2.1 DBSCAN 算法
- 将所有点分类并标记为核心点、边界点或噪声点
- 删除噪声点
- 为距离在密度半径Eps之内的所有核心点之间画一条边
- 将每组相互连接的核心点分到一个单独的簇
- 再将每个边界点指派到一个与之关联的核心点所在的簇中

2.2 时间复杂性和空间复杂性
-
时间复杂度:O(m x 找出Eps邻近域中的点所需的时间),m为点的个数。最坏的情况O(m^2)。通过有效的检索可以降低为O(mlogm)。
-
空间复杂度:O(m), 只需要存储簇标号和点的标识(每个点是核心点、边界点还是噪声点的标识)
2.3 DBSCAN算法的参数
确定半径Eps和阀值MinPts的基本方法:观察点到它的第K个最近邻点(kth nearest neighbor)的距离, 记作k-dist。思路是:对于簇中的点,它们距离其第 k 个最近邻距离很近,而噪声点距离其第 k 个最近邻较远。

图2-1 样本数据的k-dist图
-
计算每个点到其第 k 个最近邻居的距离(即k-dist)并递增排序,绘制出如上图
-
根据图中k-dist的急剧变化(shape change)的地方,选择合适的Eps值(如图中取Eps=10,取MinPts=k)
-
k-dist < Eps —— core points
k-dist = Eps —— border points
k-dist > Eps —— noise points -
虽然Eps的值取决于k, 但并不随k的变化急剧变化。如果k的值太小,则少量邻近的噪声或outlier将可能被错误地标记为cluster;如果k值太大,则小簇(点数小于k的簇) 可能被标记为噪声。一般把k取值4,对于大部分二维数据集是合理的。
3 DBSCAN 的优势和局限性
3.1 优势
- 相对比较抗噪声
- 能够处理任意形状和大小的簇,可以发现使用K-means不能发现的许多簇。

3.2 局限性
- 如果簇的密度变化很大,DBSCAN可能会出问题。
如下图如果Eps为9.75,则只有较高密度的三个簇被识别;如果Eps为9.92,最右边的几个簇会被分到同一个簇。
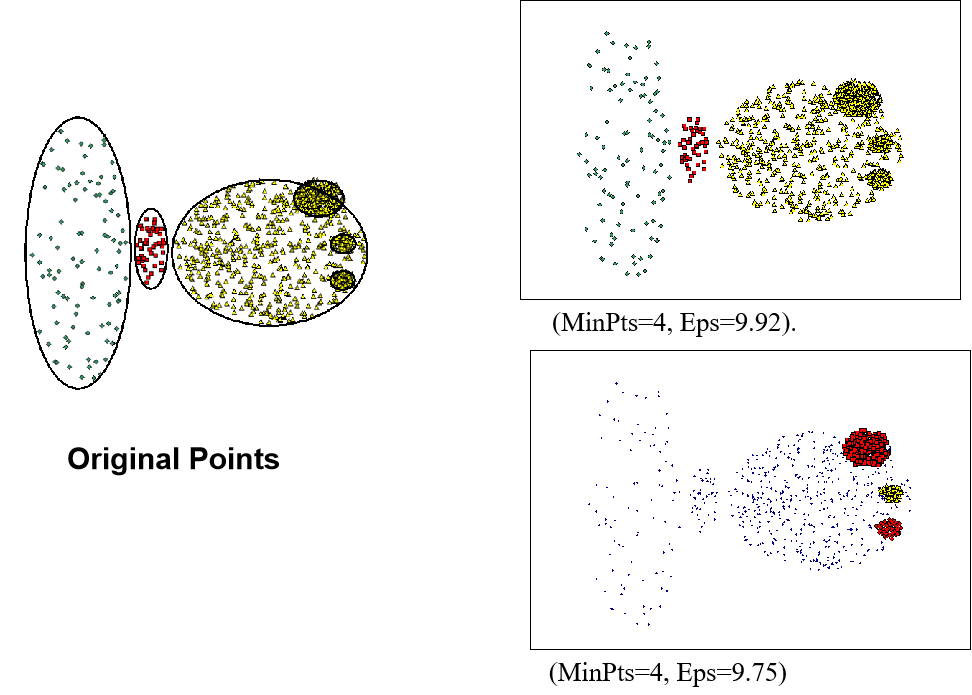
- 对于高维数据,密度的定义更加困难
- 需要计算所有点对的邻近度,开销比较大。
本节主要对基于密度的距离DBSCAN算法进行了初步的介绍,后期会再深入的探讨其他基于密度的距离方法,以及如何解决其局限性问题。














 2690
2690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









