







1、方法
基于subword的切分粒度是目前主流的token切分方式
subword的基本切分原则是:
高频词依旧切分成完整的整词
低频词被切分成有意义的子词,例如 cats => [cat, ##s]
基于subword的切分可以实现:
词表规模适中,解码效率较高
不存在UNK,信息不丢失
能学习到词缀之间的关系
2、切分流程
Tokenizer包括训练和推理两个环节。训练阶段指得是从语料中获取一个分词器模型。推理阶段指的是给定一个句子,基于分词模型切分成一连串的token。基本的流程如图所示,包括归一化,预分词,基于分词模型的切分,后处理4个步骤。
2.1 归一化
最基础的文本清洗,包括删除多余的换行和空格,转小写,移除音调等
# 从huggingface加载对应的分词器
tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
# 下载的tokenizer模型保存到本地
tokenizer.save_pretrained("./roberta_tokenizer")
# 从本地加载tokenizer
tokenizer = AutoTokenizer.from_pretrained("./roberta tokenizer/")
2.2 预分词
预分词阶段会把句子切分成更小的“词”单元
sen = "今天天气真不错!"
tokens = tokenizer.tokenize(sen)
2.3 基于分词模型切分
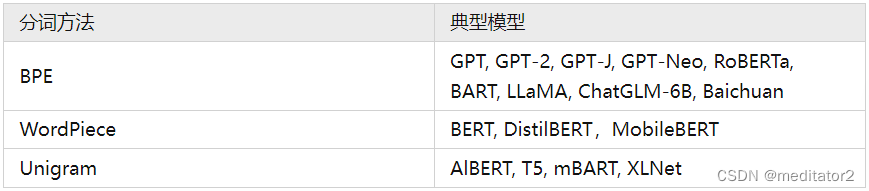
基于subword的切分包括:BPE,WordPiece 和 Unigram 三种分词模型。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









