







Uncovering What, Why and How: A Comprehensive Benchmark for Causation Understanding of Video 论文阅读
文章信息:

原文链接:https://arxiv.org/abs/2405.00181
源码:https://github.com/fesvhtr/CUVA
发表于:CVPR 2024
Abstract
视频异常理解(VAU)旨在自动理解视频中的异常事件,从而实现诸如交通监控和工业制造等各种应用。虽然现有的VAU基准主要集中在异常检测和定位上,但我们的重点是更加实用性,促使我们提出以下关键问题:“发生了什么异常?”,“为什么会发生?”,以及“这种异常事件有多严重?”为了追求这些答案,我们提出了一个全面的视频异常因果理解(CUVA)基准。具体而言,所提出的基准的每个实例都涉及三组人类注释,以指示异常事件的“发生了什么”,“为什么会发生”,以及“如何严重”,包括
1)异常类型、开始和结束时间以及事件描述,
2)异常发生原因的自然语言解释,以及
3)反映异常影响的自由文本。
此外,我们还引入了MMEval,一种新颖的评估指标,旨在更好地与人类对CUVA的偏好相一致,有助于度量现有LLMs对视频异常的根本原因和相应效应的理解。最后,我们提出了一种新颖的基于提示的方法,可以作为CUVA的挑战性基线方法。我们进行了大量实验,展示了我们的评估指标和基于提示的方法的优越性。
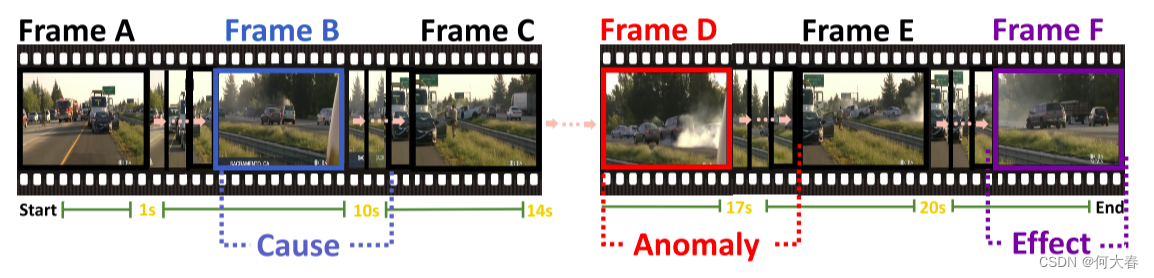
图1. 视频异常的因果关系示意图。从帧D开始的剪辑涉及交通事故,这是由在帧B指示的事件引起的,发生在事故之前的7秒钟。帧F中的剪辑展示了这种异常的效果。模型需要理解视频中这种长距离的关系,以产生正确的基于文本的解释。
1. Introduction
异常代表偏离常态的事件或情景,违背预期并偏离日常条件。这些事件通常以其独特、突然或不经常的特性为特征,需要特别关注或干预。
最近兴起的视频异常理解(VAU)旨在自动理解视频中的异常事件,从而促进各种应用,如交通监控、环境监测和工业制造。在这个方向上,视频异常检测和定位,即识别异常事件并在时间或空间上定位异常事件在视频中的位置,已经引起了极大关注。
现有的视频异常理解(VAU)基准和方法主要关注上述异常检测和定位任务,而这些事件的潜在原因及其对应的效应仍然大部分未被充分探索。这些线索对于感知异常性并基于人类可解释的解释做出决策至关重要。图1展示了一个涉及多辆车辆的交通事故场景。“事故发生的原因是一辆白色的车停在路边,一辆深灰色的车高速行驶以躲避并追尾了它旁边的黑色车。”理解这种事故原因的挑战包括:1)捕捉长视频中的关键线索:模型需要在Frame B所示的时刻识别出白色车,这是在Frame D所示的片段中事故发生前7秒。对于模型来说,捕捉这样的长期关系是具有挑战性的。2)建立因果关系的逻辑链:模型需要进一步学习视频中片段之间的丰富交互作用,由Frame B、Frame C和Frame D所示,以建立异常的因果关系的逻辑链,从而促进解释和结果的生成。上述两个挑战需要开发特定考虑这些视频异常特性的因果理解方法。
先前的研究已经证明,利用大规模、高质量和具有挑战性的基准对于开发和评估VAU任务的最新深度学习方法至关重要。沿着这条线路,现有的基准显示出了它们的潜力。然而,针对更实际的现实场景中的VAU,它们存在一些限制:
1)缺乏因果关系解释。现有的注释涉及异常发生时段,但没有提供潜在原因和效果的解释,以及针对异常的描述。
2)缺乏适当的评估指标。一些与文本解释或描述视频异常相关的指标,如BLEU和ROUGE,不能直接应用于测量多模态VAU任务,因为它们仅针对文本模态设计。
3)视频长度有限。在现实场景中,一段视频可能超过1.5分钟。然而,现有VAU中的样本通常少于30秒,这极大地简化了VAU在实际情况下的挑战。
现有数据集的上述限制呼唤着一个视频异常因果理解基准。为此,我们提出了CUVA,这是一个包含来自现实世界的1,000个视频的高质量注释的综合基准,涵盖了10个主要类别和42个不同异常类型的子类别,每个视频长117秒,平均每个视频包含65.7个token和4.3个句子。具体来说,我们手动编写自由文本解释以详细说明潜在的原因和相应的效果,以及这些事件的描述和它们之间的关系。此外,我们提出了一种新颖的评估指标来衡量方法在具有挑战性的CUVA上的能力。我们还提出了一种基于视频大型语言模型(VLM)的新型提示式方法。实验证明了该指标和所提出方法的优越性。我们工作的主要贡献可以总结如下:
- 我们开发了CUVA,这是一个关于视频异常因果理解的新基准。据我们所知,CUVA是第一个专注于视频异常因果关系的大规模基准。与现有数据集相比,我们的数据集更为全面,注释质量更高,挑战性更大。
- 我们提出了一种新颖的度量标准,以人类可解释的方式衡量具有挑战性的CUVA,并引入了基于提示的方法,以捕捉异常的关键线索并建立因果关系的逻辑链条。
- 我们在提出的CUVA上进行了大量实验。结果表明,CUVA使我们能够开发和评估各种VLM方法,以更贴近于真实世界情况的视频异常因果理解。
2. Related Work
Anomaly Datasets:现有的VAU数据集主要集中在异常检测和定位上,可以广泛分为弱监督数据集和半监督数据集。这些数据集侧重于基于帧级或像素级注释的异常事件的时间点或时间段。我们的CUVA在这些方面与现有数据集显著不同。更详细的比较请参见表1。
Evaluation Metrics:VAU评估指标包括基于参考的指标,如ROUGE和BLEURT,基于答案的指标,如BLEU、Rankgen和QAFactEval,以及其他指标,如Longformer、UniEval和MoverScore。最近,各种基于GPT的指标已经被开发出来。我们提出的MMEval与上述指标的关键区别在于:MMEval旨在基于大型语言模型评估视频和文本异常理解,而现有的指标则侧重于单一模态。
Methods:视频大型语言模型(VLM)已被广泛用于基于视频的文本生成,探索提示以释放VLM的能力。基于提示的方法可分为“硬提示”和“软提示”。针对具有挑战性的CUVA任务,我们提出了一种新方法,利用硬提示和软提示来解决在任务开始时提出的两个挑战,即捕捉关键线索和建立异常因果逻辑链。
3. The Proposed CUVA Benchmark
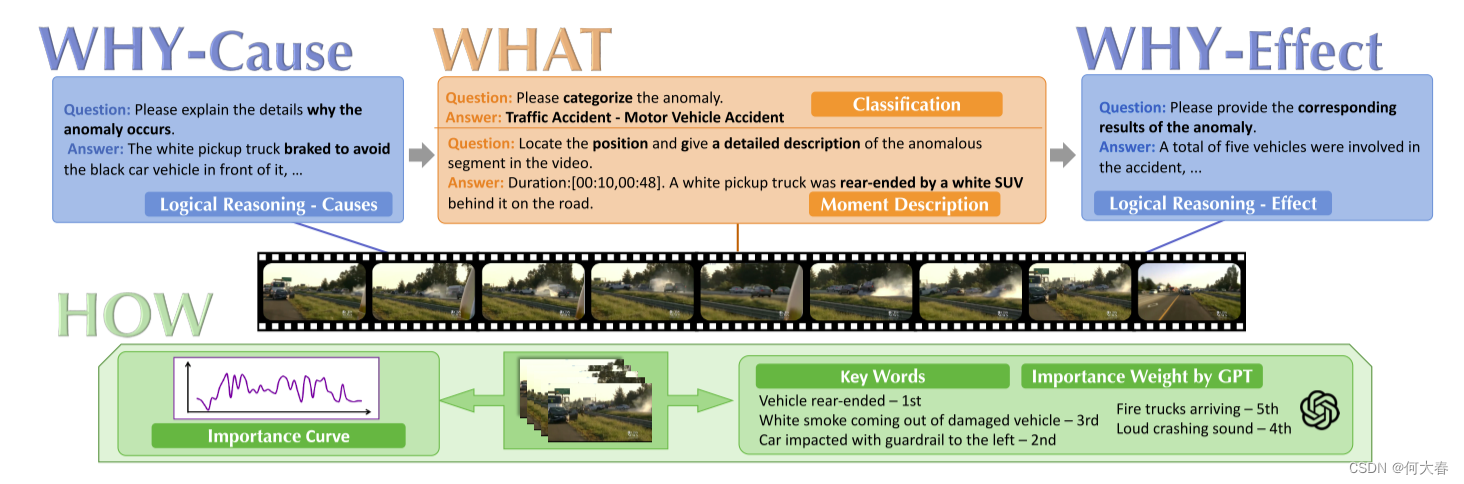
图2. 提出的CUVA基准测试概述。我们的CUVA基准测试包括手动文本注释,包括对原因(为什么)和效果(为什么)的详细解释,异常类型(是什么),详细事件描述(是什么),以及可以形成事件曲线的重要性分数(如何)。
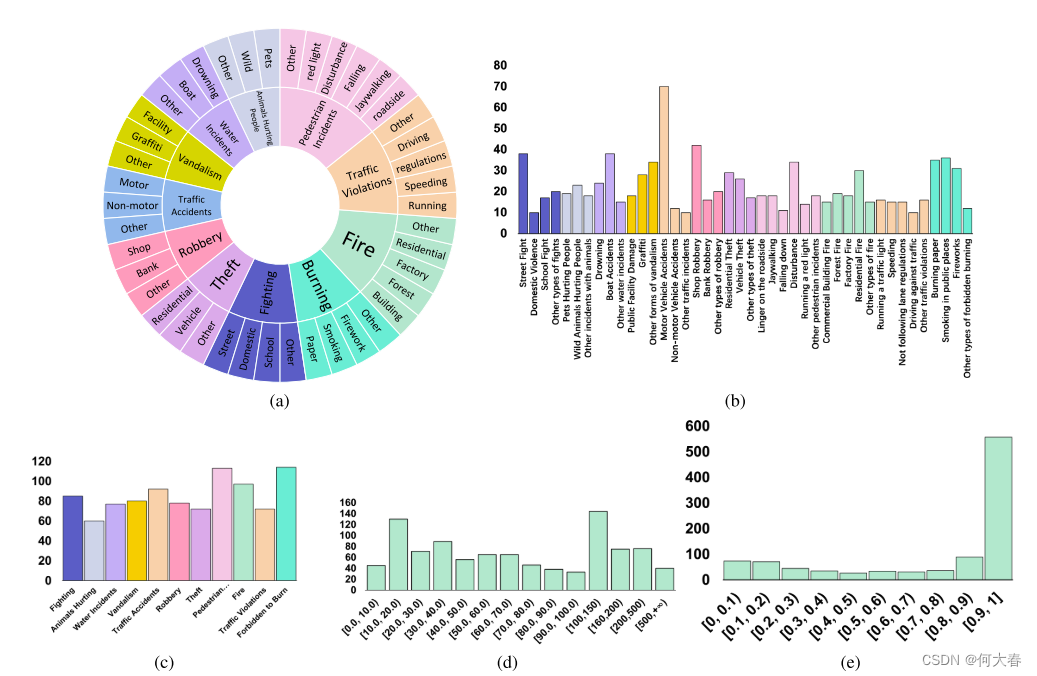
图4. 我们CUVA数据集的统计数据。图(a)显示了CUVA中的所有异常类型。图(b)和©显示了每种异常类型中视频的数量。图(d)显示了视频长度的分布。图(e)显示了异常片段的时间分布。
在本节中,我们首先介绍一些CUVA子任务。然后,我们展示数据的收集和注释方式。我们还提供了对基准测试的定量分析。我们的CUVA概述如图2所示。
3.1. Task Definition
What anomaly occurred:这个任务包括两个目标:异常分类和异常描述。异常分类涵盖了视频中存在的所有异常类别,这些类别来自我们预定义的异常类别数据库,如图4(a)所示。每个视频在不同层次上都具有多个异常类别,该任务将挑战模型在多个粒度级别上检测异常类别的能力。异常时刻描述包括异常发生的时间戳以及异常事件的详细描述。
Why this anomaly happened:该任务旨在描述视频中的因果关系。异常推理描述了视频中异常发生的原因。该任务要求模型基于视频内容推断异常的原因,并用自然语言描述,从而挑战模型的视频理解和推理能力。异常结果主要描述了视频中异常事件造成的影响。它主要测试了模型处理视频中异常事件细节的能力。
How severe this anomaly:该任务旨在反映视频中异常严重程度的变化趋势。因此,我们提出了一种称为重要性曲线的新的注释方法。我们的重要性曲线的流程细节可以在图3中找到。这种方法具有三个优点:1) 它提供了对视频中异常严重程度的时间变化的直观表示。2) 它提供了对视频中异常事件之间固有因果关系的更直观描述。3) 这种方法使我们能够在相同的框架下统一各种视频时间定位标签和任务(例如时刻检索、重点检测、视频摘要)。
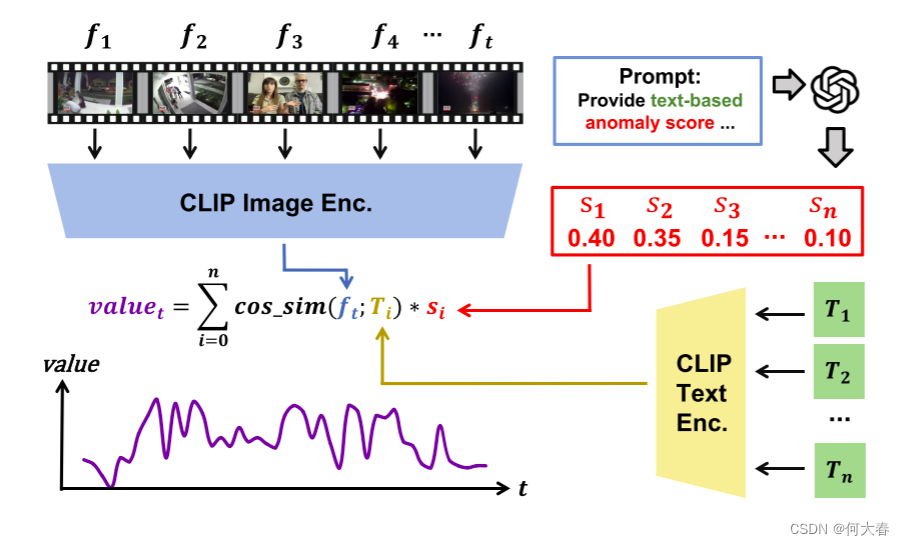
图3. 生成重要性曲线的流程。注释者需要考虑之前的任务(例如,逻辑描述、时刻描述)和视频内容,创建3到6个短句 T i T_i Ti来描述视频中的所有事件。我们利用ChatGPT [40]对这些句子的异常程度进行排序,并获得异常分数 s s s。同时,我们从视频中采样帧 f t f_t ft,并使用CLIP [43]来衡量句子和帧之间的相似性。得到的相似性分数与每个句子的异常分数相乘,以获得每个帧的 v a l u e t value_t valuet。
3.2. Dataset Collection
我们从知名的视频平台(如哔哩哔哩和YouTube)抓取数据。我们丢弃了涉及色情和政治等敏感主题的视频。在整个数据收集过程中,我们彻底分析了每个类别中视频的数量和质量,从而最终选择了最终的11个异常视频类别。然后,这些视频被分为11个主要类别,如“抢劫”、“交通事故”和“火灾”。每个主要类别进一步分为子类别。例如,我们将“火灾”类别分为“商业建筑火灾”、“森林火灾”、“工厂火灾”和“住宅火灾”子类别。通过这种方式,我们总共获得了42个子类别。
3.3. Annotation Pipeline
我们的数据集构建流程包括三个阶段:预处理、手动标注和重要性曲线处理。整个过程大约需要150个小时,涉及20多名标注者。
3.3.1 Pre-processing
首先,我们从哔哩哔哩和YouTube上爬取视频。然后,我们通过手动筛选,手动剪辑收集到的视频,以确保视频内容的质量,并排除非道德内容和敏感信息。在整个数据集收集和标注过程中,我们严格遵循网站的道德要求。最终,我们获得了1,000个异常视频剪辑。
3.3.2 Manual Annotation
我们根据设计的注释文件对视频进行英文注释,注释分为两轮进行。我们采用类似于kappa [60]的机制来筛选和培训注释者,确保他们的注释内容一致。在第一轮中,我们要求注释者根据任务定义对所有视频进行注释。在第二轮中,我们要求这些注释者审查和补充第一轮的注释结果。
3.3.3 Post-processing of Importance Curve
由于 CLIP 模型和采样间隔的能力有限,初始曲线可能无法准确反映异常的时间段,这会严重影响下游任务的有效性。因此,我们引入以下三个任务来优化重要性曲线,包括视频字幕生成 [24]、视频蕴含性判断 [67] 和视频定位 [27]。基于这些任务,我们采用投票机制来精确识别视频中与给定关键句子对应的时间段。
3.4. Dataset Statistics
我们的CUVA数据集包含1,000个视频片段和6,000个问答对,这些视频的总长度为32.46小时,平均每个视频包含3,345帧。视频的帧是以60 FPS的速率从原始视频中提取的。这些视频涵盖了广泛的领域。然后,我们将异常事件分为11种情景,总共有42种异常类型,如图4(a)所示。视频类别的分布如图4(b)和4( c)所示。视频长度的分布可以在图4(d)中找到,以及视频时间比例的百分比显示在图4(e)中。
4. The Proposed Method: Anomaly Guardian
在本节中,我们介绍了一种名为异常守护者(A-Guardian)的新型基于提示的方法,该方法旨在解决我们数据集提出的两个挑战。通过利用VLM出色的逻辑推理能力,我们将其选为我们方法的基础,以建立因果关系的逻辑链。为了有效捕获漫长视频中的关键线索,我们提出了一种新颖的提示机制,旨在引导VLM集中注意提供的问题相关的视频中的关键线索。
4.1. Design of Hard Prompts
我们首先使用ChatGPT [40]来协助确认和补充用户提示,从而使VLM更好地理解用户的意图。具体来说,我们首先利用一个包含示例的指示提示来纠正误导性的指导,并规范输出格式。由于长视频中存在许多事件,我们采用了多轮对话机制来帮助VLM识别与视频中异常事件相关的事件。经过多轮后,VLM可以更专注于与异常相关的片段,从而提供更准确的答案。
4.2. Design of Soft Prompts
我们利用MIST中的选择器来更好地捕获与ChatGPT处理的给定问题相关的时空特征。我们首先将视频分成
N
N
N个等长的段,每个段包含
T
T
T帧。为了更好地捕获不同粒度的视觉概念之间的交互作用,我们将每一帧分成
M
M
M个补丁。此外,我们利用
[
C
L
S
]
[CLS]
[CLS]标记来表示每个段和帧。具体来说,我们首先使用冻结参数的CLIP来提取补丁级别的特征,表示为
P
=
{
p
1
,
p
2
,
.
.
.
,
p
m
}
\mathbf{P}=\{p^{1},p^{2},...,p^{m}\}
P={p1,p2,...,pm},其中
p
m
∈
R
T
×
M
×
D
p^m\in\mathbb{R}^{T\times M\times D}
pm∈RT×M×D,
D
D
D是每个补丁级别特征的维度。然后,我们对补丁特征的空间维度进行池化操作,以获得帧特征。
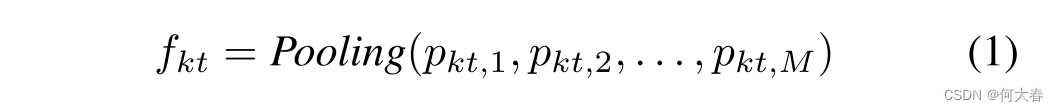
其中
p
k
t
,
m
p_{kt,m}
pkt,m表示第
k
k
k个段的第
t
t
t帧中的第
m
m
m个补丁。然后,通过沿着时间维度对帧特征进行池化,得到段特征,其中
f
k
t
∈
R
T
×
D
f_{kt}\in\mathbb{R}^{T\times D}
fkt∈RT×D.
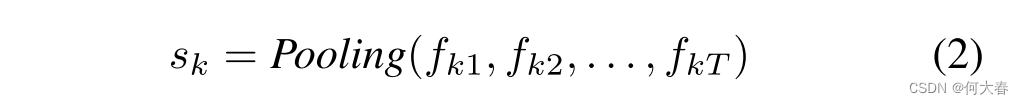
同样,问题特征通过对单词特征进行池化得到,其中
w
z
∈
R
Z
×
D
w_z\in\mathbb{R}^{Z\times D}
wz∈RZ×D且
q
∈
R
D
q\in\mathbb{R}^D
q∈RD.
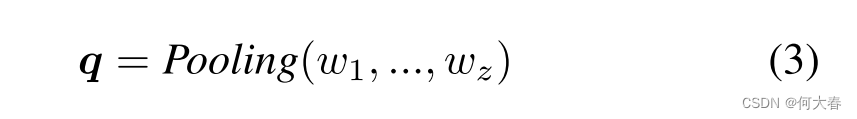
接下来,我们使用跨模态时间注意力和来自MIST [17]的前 k 个选择,根据以下公式选择前 k 个段的补丁特征。术语“”selector””对应于一种
T
o
p
k
Top_k
Topk选择函数,用于从考虑问题的
T
o
p
k
Top_k
Topk 段中挑选视频段特征。
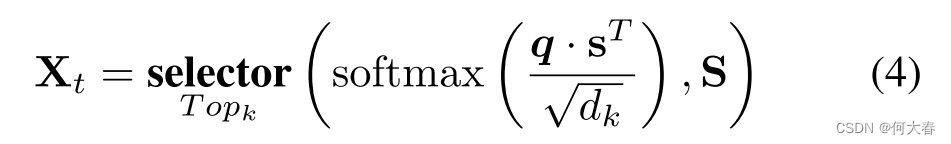
4.3. Answer Prediction
最后,我们遵循先前的工作 [21],将硬提示和软提示连接起来,并将它们输入到 VLM 进行推断。在训练阶段,我们使用 GPT 生成候选答案和数据增强。我们只对选择器进行微调,通过优化 softmax 交叉熵损失,将预测的相似度分数与基准值对齐。
5. Experiment
5.1. The Proposed MMEval Metric
考虑到我们的数据集广泛使用自由文本描述来描述异常事件及其因果关系,并且认识到CUVA是一个多模态数据集(整合了视频、文本和附加评论),这需要从仅依赖自然语言生成(NLG)度量转变为更广泛的考虑,涵盖丰富的多模态输入信息。因此,我们引入了一种新的评估指标,即图6所示的MMEval。为了从多模态的角度评估模型的性能,并将人类式的推理能力融入评估指标,我们选择了Video-ChatGPT [36]作为我们的基础模型。我们利用自然语言提示来指导MMEval指定要评估的任务类型,并设计了三个自然语言提示,分别对应数据集中的三种自由文本描述。为了增强模型的鲁棒性,我们利用曲线标签来帮助VLM更加关注视频中的异常段。具体来说,通过设置阈值来提取曲线中的重要事件段,我们对该视频段进行密集采样,帮助VLM更多地关注视频的关键部分。我们的MMEval指标可用于评分、排名和提供理由解释。
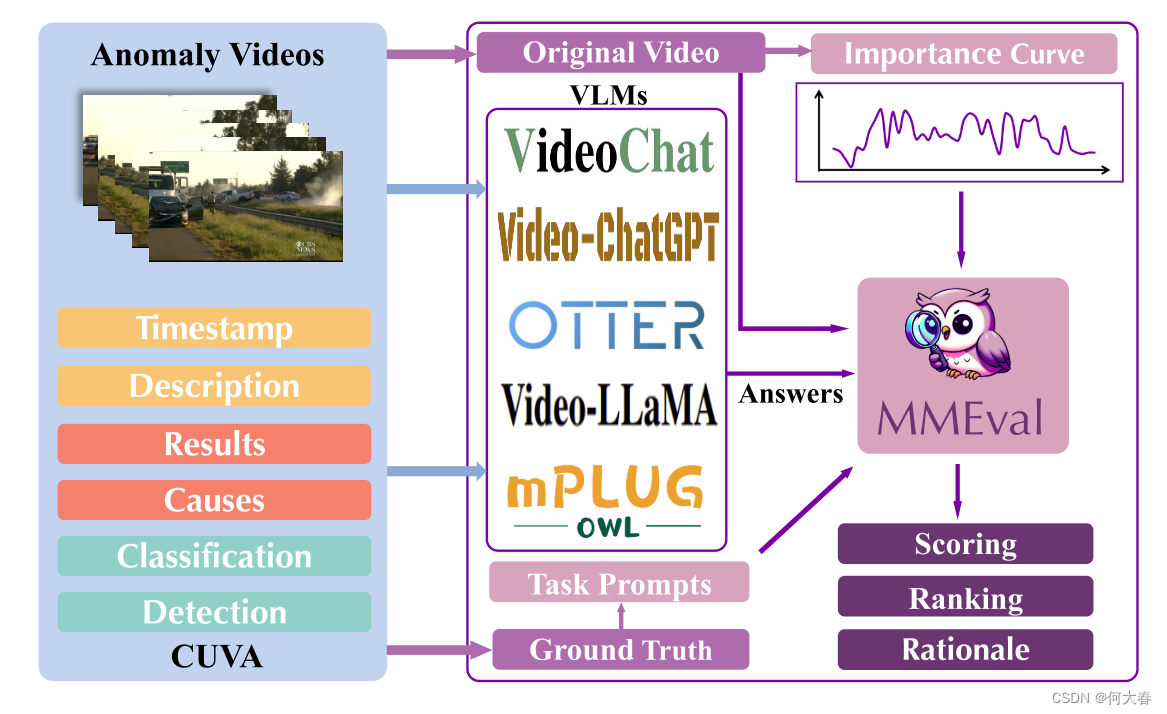
图 6. 我们的 MMEval 指标概述。
5.2. Implementation Details
我们遵循 Video-ChatGPT [36],采用 CLIP-L/14 视觉编码器来提取视频的空间和时间特征。在我们的方法中,我们利用 Vicuna-v1.1 模型,该模型包含 7B 个参数,并使用 LLaVA [28] 的权重进行初始化。所有实验都在四块 NVIDIA A40 GPU 上进行,每个任务大约需要 8 小时。
5.3. Consistency evaluation of MMEval
我们的 MMEval 指标可以更好地与人类对视频异常因果理解的偏好相一致。为了验证我们的评估指标与人类判断的一致性,我们进行了一项人类一致性实验。使用第一轮注释、第二轮注释和 GPT 生成的答案的排名作为基准(1. 第二轮 2. 第一轮 3. ChatGPT),我们采用各种评估指标和观看视频的人类来根据相应的问题对这些答案进行排名,如表 4 所示。
5.4. Quantitative evaluation of A-Guardian
我们的 A-Guardian 模型在描述和因果任务中实现了最先进的性能。我们对数据集中涉及的所有任务进行了实验,结果总结在表 2 中。对于自由文本任务(例如因果、效果、描述),我们评估了不同 VLM 和我们模型在不同评估指标下的性能。我们的模型在效果任务中也优于大多数模型。对于其他任务(例如检测、分类、时间戳),我们设置了统一的提示,并使用字符串匹配从 VLM 的推断结果中提取与问题相关的答案。表 3 显示了这些任务的结果。
6. Conclusion
本文介绍了 CUVA,这是一个用于视频异常因果理解的新型基准。据我们所知,我们的 CUVA 是该领域的第一个基准。与现有数据集相比,CUVA 更加全面、更具挑战性,并且具有更高质量的注释。我们相信所提出的 CUVA 将鼓励对各种下游任务的探索和发展,例如异常检测、异常预测、异常推理等。我们还提出了 MMEval,这是一种新颖的评估方法,可以以人类可解释的方式衡量 CUVA 的挑战性。此外,我们提出了一种基于提示的方法,可以作为 CUVA 的基线方法。这种方法可以捕捉异常的关键线索,并建立起因果关系的逻辑链条。实验结果表明,CUVA 使我们能够开发和评估各种 VLM 方法。未来,我们计划将我们的 CUVA 应用到更多的实际场景中,用于异常理解和其他基于 VLM 的任务。
总结
感觉很乱,不想看


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









