







文章信息:

发表于:www 2025
原文链接:https://arxiv.org/abs/2502.18863
源码:无
Abstract
先前关于视频异常检测(VAD)的研究主要集中在检测视频中每一帧是否异常,而很大程度上忽略了结构化的视频语义信息(即异常事件发生的内容、时间和地点)。基于此,我们提出了一种新的聊天范式多场景视频异常事件提取与定位(M-VAE)任务,旨在提取异常事件四元组(即主体、事件类型、对象、场景)并定位此类事件。此外,本文认为这项新任务面临两个关键挑战,即全局-局部空间建模和全局-局部空间平衡。为此,本文提出了一个名为Sherlock的全局-局部空间敏感大语言模型(LLM),即像夏洛克·福尔摩斯一样追踪犯罪事件,用于解决这一M-VAE任务。具体来说,该模型设计了一个全局-局部空间增强MoE(GSM)模块和一个空间不平衡调节器(SIR),分别用于解决这两个挑战。在我们构建的M-VAE指令数据集上进行的广泛实验表明,Sherlock相较于几种先进的视频LLM具有显著优势。这证明了全局-局部空间信息对M-VAE任务的重要性,以及Sherlock在捕获此类信息方面的有效性。
1 Introduction
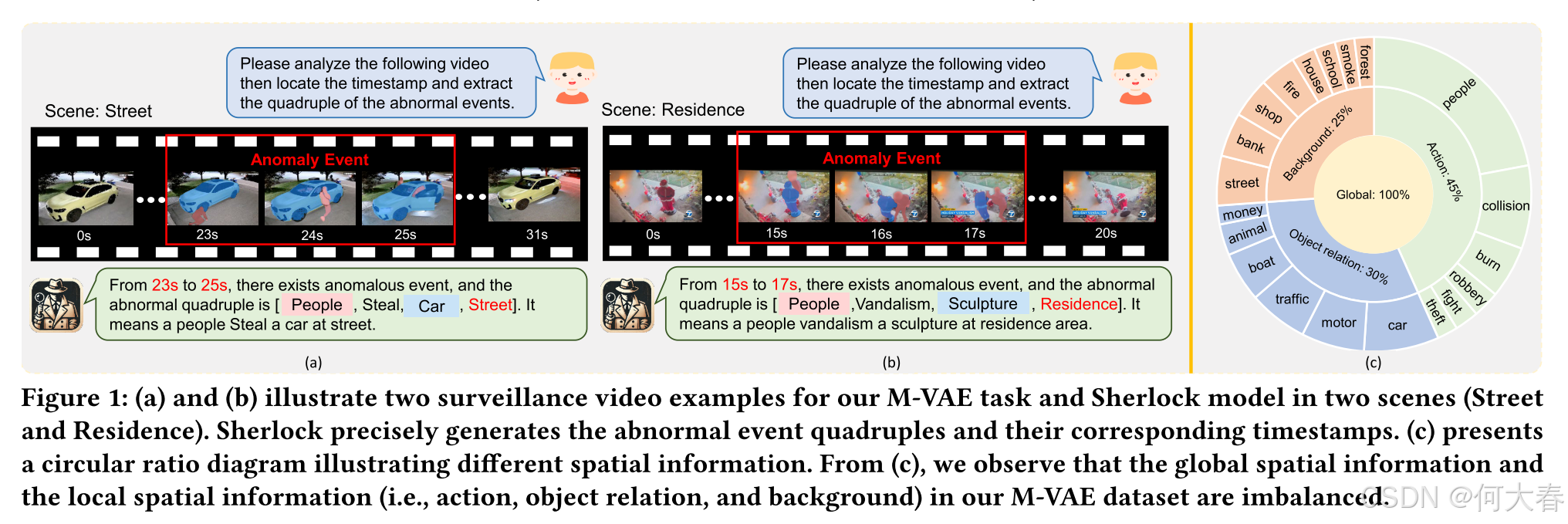
视频理解是人工智能中的一项基础任务,其核心在于分析和解释视频内容,以实现视频分类、活动识别和场景理解等多种应用[40, 58, 59]。作为视频理解的一个重要分支,视频异常检测(Video Anomaly Detection, VAD)[20]旨在自动检测异常视频,并因其在犯罪活动检测和灾难响应等领域的广泛应用而受到广泛关注[56]。以往的研究主要集中在检测视频中每一帧是否异常[20, 29, 41, 56],但这些研究忽视了更深层次的视频语义结构,即“异常类型是什么、异常发生在哪里、涉及哪些人或事物”等问题。
受此启发,本文提出了一种新颖的多场景视频异常事件提取与定位(M-VAE)任务,旨在通过聊天范式定位异常事件(即异常的开始和结束时间)并提取事件四元组(即[事件主体、事件类型、事件对象、事件场景])。以图1(a)中的街道场景为例,在23秒到25秒之间,一名男子弯腰撬锁,然后驾车离开街道,异常事件四元组为[人,偷窃,汽车,街道]。图1(b)中还展示了不同的场景(即住宅场景)。在15秒到17秒之间,一名男子在住宅中破坏雕塑,四元组为[人,破坏,雕塑,住宅]。这种对异常视频的结构化处理可以显著提高视频异常定位系统的实用性和效率。在需要高可靠性和精确监控的实时异常事件监控等领域,使用这种结构化处理可以快速搜索和筛选所需的异常元素,从而为进一步处理提供更便捷和直观的证据。因此,解决这一新任务是非常有价值的。然而,我们认为这一新任务面临两个关键挑战。
一方面,建模全局-局部空间信息(称为全局-局部空间建模挑战)具有挑战性。现有的视频理解模型[34, 38, 54]主要侧重于建模一般的全局信息。然而,在我们的M-VAE任务中,局部空间信息通常比一般的全局信息更为关键,这些信息具有高度区分性,对于精确识别至关重要。以图1(a)为例,局部空间信息,如动作(弯腰)、对象关系(<人,靠近,车>)和背景(街道),可以帮助更好地识别异常事件。然而,这些局部空间信息(例如,动作、对象关系、背景)具有不同的异构表示(即不同的模型结构和编码器)。因此,单一的、固定容量的基于Transformer的模型通常难以捕捉视频中这些关键的局部空间信息。最近,混合专家(Mixture of Expert, MoE)[18, 23]范式在多模态异构表示融合任务中展示了可扩展性[18, 23, 24]。受此启发,我们任务中的一个表现良好的模型应该采用MoE范式,不仅要考虑全局空间信息,还要强调局部空间信息的重要性。
另一种直接的方法是使用基本的混合专家(Mixture of Experts, MoE)机制,将全局空间信息(即视频的通用表示)和局部空间信息(例如动作)分别视为全局专家和局部专家,以整合这些信息。然而,局部空间信息之间的数据不平衡问题可能导致基本的MoE专家偏向于数据集中更频繁出现的空间信息。图1(c)中的统计数据可以说明这种不平衡。某些频繁出现的局部信息(例如动作占45%)可能会导致相应专家的权重更高。然而,在图1(a)中,对象关系信息虽然占比最小(25%),但在提取和定位盗窃事件时最具区分性。更严重的是,全局空间信息出现频率最高,并且我们在图7(a)中的初步实验表明,全局专家通常训练得更充分,且往往具有最高的权重。因此,一个表现更好的MoE专家融合机制应该缓解这种数据不平衡(称为全局-局部空间平衡挑战),确保所有专家都得到充分训练,以突出它们的重要性。
为了应对上述挑战,我们提出了一种名为Sherlock的全局-局部空间敏感大语言模型(LLM),即像夏洛克·福尔摩斯一样追踪犯罪事件,用于多场景视频异常事件提取和定位(M-VAE)任务。具体来说,该模型设计了一个全局-局部空间增强的混合专家(GSM)模块,以解决全局-局部空间建模的挑战。该模块包括四个空间专家,用于提取空间信息,以及一个专家门,用于权衡全局和局部空间信息。此外,该模型还设计了一个空间不平衡调节器(SIR),以解决全局-局部空间平衡的挑战。该调节器包括一个门控空间平衡损失(GSB),以进一步平衡全局和局部专家。特别地,我们构建了一个M-VAE指令数据集,以更好地评估模型的有效性。详细的实验表明,Sherlock能够有效地提取和定位异常事件,并在多个评估指标上超越了先进的视频大语言模型(Video-LLMs)。
2 Related Work
Video Anomaly Detection.
视频理解是一个快速发展的研究领域,涵盖了视频定位[40, 58, 59]、时空检测[13]等多个任务。作为视频理解的一个重要分支,以往关于视频异常检测(VAD)的研究可以分为无监督、弱监督和全监督三类。无监督方法侧重于利用重建技术来识别异常[15, 20, 62, 64]。弱监督方法在识别异常帧方面表现出色[11, 36, 57, 60, 72]。全监督方法由于需要昂贵的帧级标注而较为稀缺[7, 10, 12, 19, 53, 55, 70]。与上述研究不同,我们的Sherlock模型旨在确定视频的底层语义结构,提供一种结构化的四元组,超越了以往的方法,有助于实时异常事件的快速检测和预警。
Event Extraction
事件抽取(Event Extraction, EE)专注于从给定类型的信息中提取结构化信息。传统的EE方法主要从文本文档中提取信息[21, 25, 35, 37, 52]。最近,许多研究[2, 44, 66–68]从视觉图像数据中生成类似的事件结构。与上述所有研究不同,我们首次专注于从视频中提取异常事件并构建四元组数据集,整合了多种空间信息,丰富了事件抽取任务,使其更适用于现实世界的应用。
Video-oriented Large Language Models.
ChatGPT[49]的兴起推动了视频大语言模型的繁荣,这些模型可分为四大类:首先,Video Chat[34]和Video LLaMA[69]利用BLIP-2[33]和Q-Former将视觉表示映射到Vicuna;其次,像Video ChatGPT[47]、Otter[31]、Valley[46]、mPLUGOwl[65]和Chat-UniVi[26]这样的模型,它们利用CLIP[51]对视觉特征进行编码;第三,PandaGPT[54]采用ImageBind[14]作为其核心架构进行视频理解;第四,VideoLLaVA[38]使用LanguageBind[73]将图像和视频特征对齐到语言特征空间。最近,一些研究[27, 63]考虑在模型中融入空间信息。此外,一些研究[18, 23, 24]将MoE的概念引入LLM,但它们只关注效率,没有考虑不同信息之间的平衡。与上述所有研究不同,我们设计了一个新的Sherlock模型,以解决我们的M-VAE任务,该模型包括一个全局-局部空间增强的MoE模块和一个空间不平衡调节器,以应对全局-局部建模和平衡的挑战。
3 Our Sherlock Model
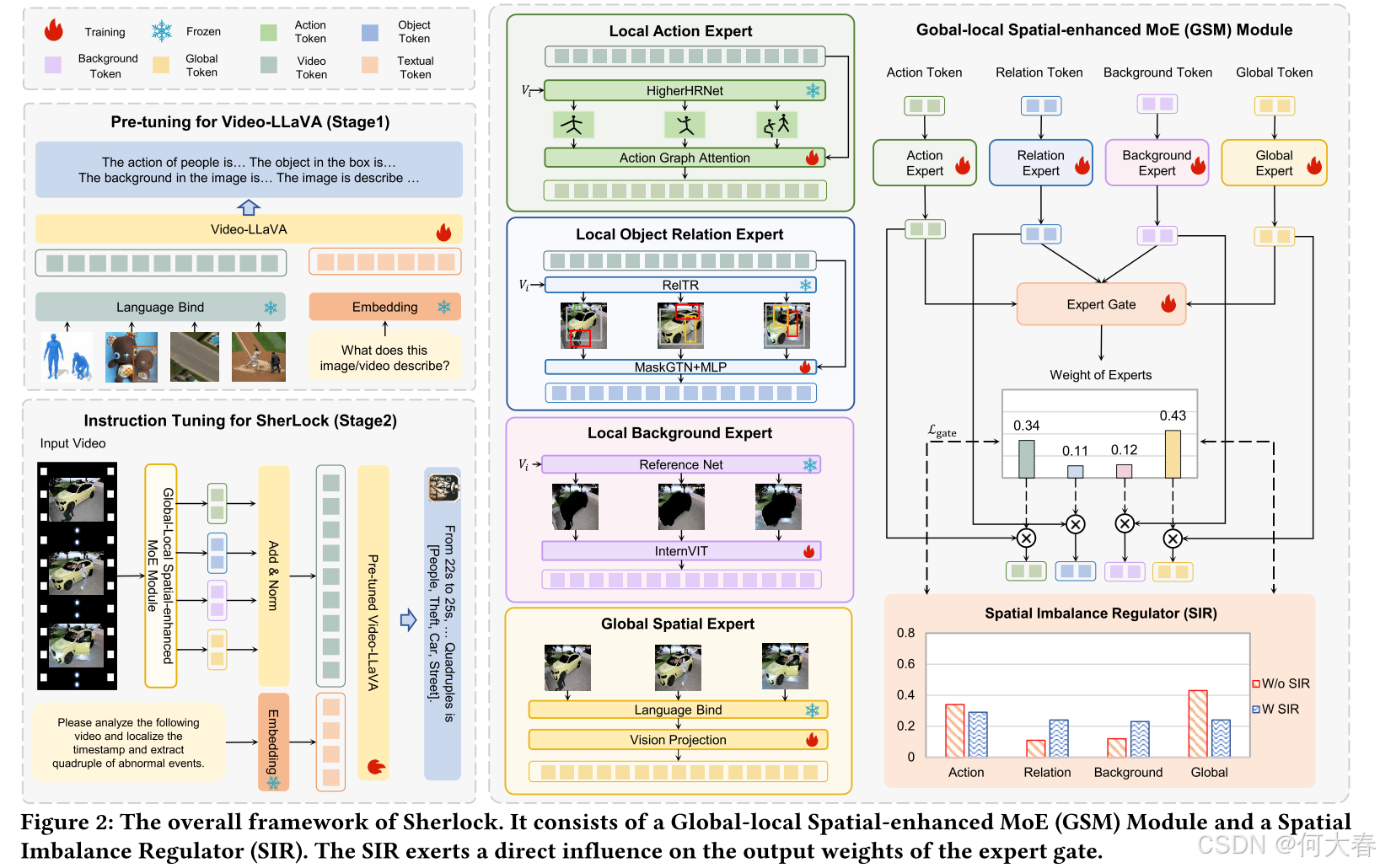
在本文中,我们提出了一个Sherlock模型来解决M-VAE任务。图2展示了Sherlock的框架,该框架由两个核心组件组成(即用于解决全局-局部空间建模挑战的全局-局部空间增强MoE(GSM)模块(第3.1节)和用于解决全局与局部空间平衡挑战的空间不平衡调节器(SIR)(第3.2节))。随后,我们介绍了用于增强空间信息理解能力的训练策略(第3.3节)。
Backbone.我们选择Video-LLaVA[38]及其视觉编码器LanguageBind[73]作为核心框架。Video-LLaVA通过混合图像和视频数据集进行优化,在大多数图像和视频基准测试中表现出领先的性能。我们采用Video-LLaVA作为骨干网络,以探索视频大语言模型在提取和定位异常事件方面的潜力。
Task Formulation.给定一个包含𝑀帧的视频𝑉,每一帧被标记为1或0,其中1和0分别表示该帧是否传达了异常事件。M-VAE的目标是交互式地为每个事件生成四元组(𝑠𝑢𝑏, 𝑡𝑦𝑝𝑒, 𝑜𝑏𝑗, 𝑠𝑐𝑒)以及相应的时间戳𝑠𝑡𝑎和𝑒𝑛𝑑,其中𝑠𝑢𝑏、𝑡𝑦𝑝𝑒、𝑜𝑏𝑗、𝑠𝑐𝑒、𝑠𝑡𝑎和𝑒𝑛𝑑分别表示异常事件的主体、事件类型、对象、场景、开始时间和结束时间。如图1(a)所示,一名男子在街道上从23秒到25秒偷了一辆车。因此,我们M-VAE任务的输出为{23s, 25s, (人, 偷窃, 车, 街道)}。
3.1 Global-local Spatial-enhanced MoE Module
如图2所示,我们设计了一个全局-局部空间增强MoE(GSM)模块,以应对全局-局部空间建模的挑战。受混合专家(Mixture-of-Experts, MoE)[24]的启发,我们设计了三个局部空间专家(即局部动作专家、局部对象关系专家和局部背景专家)以及一个全局空间专家来提取空间信息,具体如下。
Local Spatial Experts.
局部空间专家包含三个局部空间专家(即动作、对象关系和背景),具体如下。
∙ \bullet ∙ 局部动作专家(Action Expert, AE)。我们利用HigherHRNet [6],一种广泛采用的自下而上的人体姿态估计网络,来提取局部空间动作信息。HigherHRNet可以生成局部空间动作标记T a = { t 1 a , . . . , t i a , . . . , t m a } _a=\{t_1^a,...,t_i^a,...,t_m^a\} a={t1a,...,tia,...,tma},每个标记由视频序列中每一帧的个体的17个人体关节节点组成。这里, i i i表示第 i i i帧。接下来,我们应用动作图注意力机制将T a _a a与视频编码器在视频大语言模型中生成的视频标记T υ = { t 1 υ , . . . , t i υ , . . . , t m υ } _{\boldsymbol{\upsilon}}=\{t_1^{\boldsymbol{\upsilon}},...,t_{\boldsymbol{i}}^{\boldsymbol{\upsilon}},...,t_{\boldsymbol{m}}^{\boldsymbol{\upsilon}}\} υ={t1υ,...,tiυ,...,tmυ}进行整合。我们首先计算 t i a t_i^a tia中每个节点 e k e_k ek相对于其相邻节点 e j e_j ej的注意力权重 α k j \alpha_{kj} αkj:
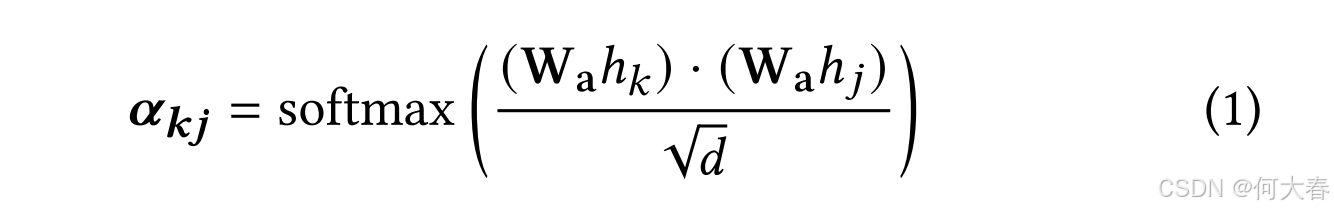
其中,
h
k
h_k
hk和
h
j
h_j
hj分别是
e
k
e_k
ek和
e
j
e_j
ej的特征,
W
a
\mathbf{W}_a
Wa表示可学习的权重矩阵,
d
d
d是特征维度。然后,我们聚合节点
e
k
e_k
ek的特征
h
^
k
\hat{h}_k
h^k:
h
^
k
=
∑
j
∈
N
(
e
k
)
α
k
j
⋅
h
j
\hat{h}_k=\sum_{j\in\mathcal{N}(e_k)}\alpha_{kj}\cdot h_j
h^k=∑j∈N(ek)αkj⋅hj,其中
N
(
e
k
)
\mathcal{N}(e_k)
N(ek)是
e
k
e_k
ek的相邻节点。最后,
e
k
e_k
ek的特征通过
h
k
′
=
ReLU
(
W
k
[
h
^
k
,
h
k
]
)
h_k^\prime=\operatorname{ReLU}(\mathbf{W}_\mathbf{k}[\hat{h}_k,h_k])
hk′=ReLU(Wk[h^k,hk])计算,其中
W
a
\mathbf{W}_\mathbf{a}
Wa表示权重矩阵,
[
h
^
k
,
h
k
]
[\hat{h}_k,h_k]
[h^k,hk]是
h
^
k
\hat{h}_k
h^k和
h
k
h_k
hk的拼接。
在图注意力操作之后,我们通过注意力机制对 T α \mathbf{T_{\boldsymbol{\alpha}}} Tα进行增强,使用查询 Q υ \mathbf{Q}_{\boldsymbol{\upsilon}} Qυ、键 K α \mathbf{K}_{\boldsymbol{\alpha}} Kα和值 V α \mathbf{V}_{\boldsymbol{\alpha}} Vα计算,最终得到动作标记: T ′ α = \mathbf{T'}_{\boldsymbol{\alpha}}= T′α=softmax ( Q υ T ⋅ K α ) ⋅ V α (\mathbf{Q}_{\boldsymbol{\upsilon}}^{\mathsf{T}}\cdot\mathbf{K}_{\boldsymbol{\alpha}})\cdot\mathbf{V}_{\boldsymbol{\alpha}} (QυT⋅Kα)⋅Vα。
∙ \bullet ∙ 局部对象关系专家(Object Relation Expert, ORE)。我们利用RelTR [9],一种经过深入研究的一阶段对象关系图生成方法,来提取局部空间对象关系信息。RelTR可以生成对象关系标记 t i o = ( R i , E i ) \boldsymbol{t}_i^o=(R_i,E_i) tio=(Ri,Ei),它表示第 i i i帧的对象关系图。其中, R i = { ( c i , 1 , b i , 1 ) , . . . , ( c i , k , b i , k ) } R_i=\left\{\left(c_{i,1},b_{i,1}\right),...,\left(c_{i,k},b_{i,k}\right)\right\} Ri={(ci,1,bi,1),...,(ci,k,bi,k)}是一组 k k k个检测到的对象,包含类别 c c c和对应的边界框 b b b。集合 E i = { c i , p , r i , ( p , q ) , c i , q } E_i=\{c_{i,p},r_{i,(p,q)},c_{i,q}\} Ei={ci,p,ri,(p,q),ci,q}由图中的有向边组成,表示从 c i , p c_{i,p} ci,p到 r i , ( p , q ) r_{i,(p,q)} ri,(p,q)以及从 r i , ( p , q ) r_{i,(p,q)} ri,(p,q)到 c i , q c_i,q ci,q的两条有向边,其中 r i , ( p , q ) r_i,(p,q) ri,(p,q)表示关系类别。例如,一个对象可能表示为 ( m a n , < 0.36 , 0.24 , 0.75 , 1.62 > ) (man,<0.36,0.24,0.75,1.62>) (man,<0.36,0.24,0.75,1.62>),一条边可能表示为 ( m a n , near, car ) (man, \textit{near, car}) (man,near, car)。随后,我们应用对象感知掩码与掩码图变换网络(MaskGTN),以充分利用对象关系。我们基于边界框信息掩码掉不相关的对象部分,并使用图变换层(GT)从邻居中聚合信息。给定区域类别和边的输入图,MaskGTN为每个区域和边计算更新后的向量。假设我们使用 L L L层GT,其中 H ( ℓ ) H^{(\ell)} H(ℓ)表示第 ℓ \ell ℓ层的特征,最终的前向传播定义如下:
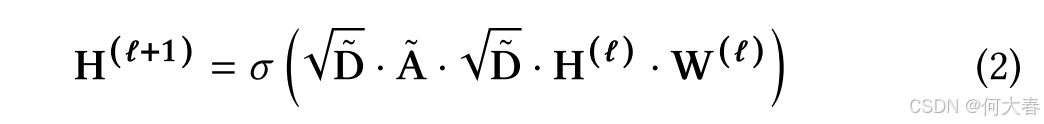
其中, σ \sigma σ是图上的激活函数。 A ~ \tilde{\mathbf{A}} A~是对象关系图的邻接矩阵,由 E i E_i Ei导出, D ~ \tilde{\mathbf{D}} D~是其度矩阵,其中 D i i = ∑ i A i j ~ \mathbf{D}_{ii}= \sum _i\tilde{\text{A}_{ij}} Dii=∑iAij~。 W ( ℓ ) \mathbf{W} ^{( \ell ) } W(ℓ)是一个可训练的权重矩阵。
∙ \bullet ∙ 局部背景专家(Background Expert, BE)。我们利用SAM2 [28],一种先进的视觉分割模型,从视频中提取局部空间背景信息。SAM2可以为视频的每一帧生成背景图像。然后,我们利用InternVit [5]对局部空间背景信息进行编码,InternVit是一种将视觉变换器(VIT)[4]参数扩展到6B的大型视觉编码器,形式化表示为:
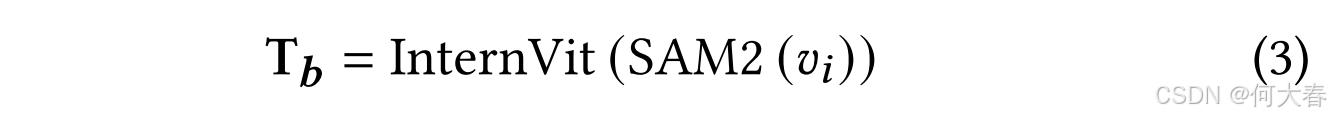
其中, v i v_i vi是视频 V V V的第 i i i帧。这一过程生成了整个视频序列的局部空间背景标记 T b = { t 1 b , . . . , t i b , . . . , t m b } \mathbf{T}_{\boldsymbol{b}}=\{\boldsymbol{t}_1^{\boldsymbol{b}},...,\boldsymbol{t}_i^{\boldsymbol{b}},...,\boldsymbol{t}_m^{\boldsymbol{b}}\} Tb={t1b,...,tib,...,tmb},其中 n n n表示帧的总数。
Global Spatial Expert
全局空间专家对训练数据具有全面的理解。它与局部空间专家协作,为M-VAE任务带来专业化和泛化能力。
∙ \bullet ∙ 全局空间专家(Global Expert, GE)。分配给全局空间专家的权重与局部空间专家的权重互补。因此,局部空间专家获得了特定任务的专门技能,而全局空间专家则对整个训练语料库有了全面的理解。这两类专家之间的协作为我们的M-VAE任务提供了专业化和泛化能力。通过这种方式,我们利用Video-LLaVA [38]中的LanguageBind [73],它继承了CLIP的ViT-L/14结构,并具备强大且通用的视觉编码能力,为我们的任务提取全局空间信息。随后,我们利用[38]预训练的FFN层来对齐维度与其他空间信息,形式化表示为:
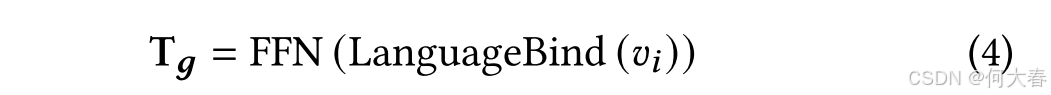
其中,
v
i
v_i
vi是视频
V
V
V的第
i
i
i帧。这一过程生成了整个视频序列的全局标记
T
g
=
{
t
1
g
,
.
.
.
,
t
i
g
,
.
.
.
,
t
m
g
}
\mathbf{T}_{\boldsymbol{g}}=\{t_1^{\boldsymbol{g}},...,t_{\boldsymbol{i}}^{\boldsymbol{g}},...,t_{\boldsymbol{m}}^{\boldsymbol{g}}\}
Tg={t1g,...,tig,...,tmg},其中
n
n
n表示帧的总数。
在设计完四个专家后,我们确保这四个空间专家能够基于混合专家(Mixture-of-Experts, MoE)[18]的启发,动态调整四种异构空间信息的权重。如图2所示,与在LLM内部嵌入多个FFN的方法不同,我们的GSM将四个专家放在LLM外部,以调整全局和局部空间信息的权重。在此基础上,我们引入了一个动态的专家门(Expert Gate, EG)[50],它通过计算门控权重作为软门来控制每个专家的贡献。最终,基于四个空间专家和EG的GSM输出 O \mathbf{O} O形式化表示为:
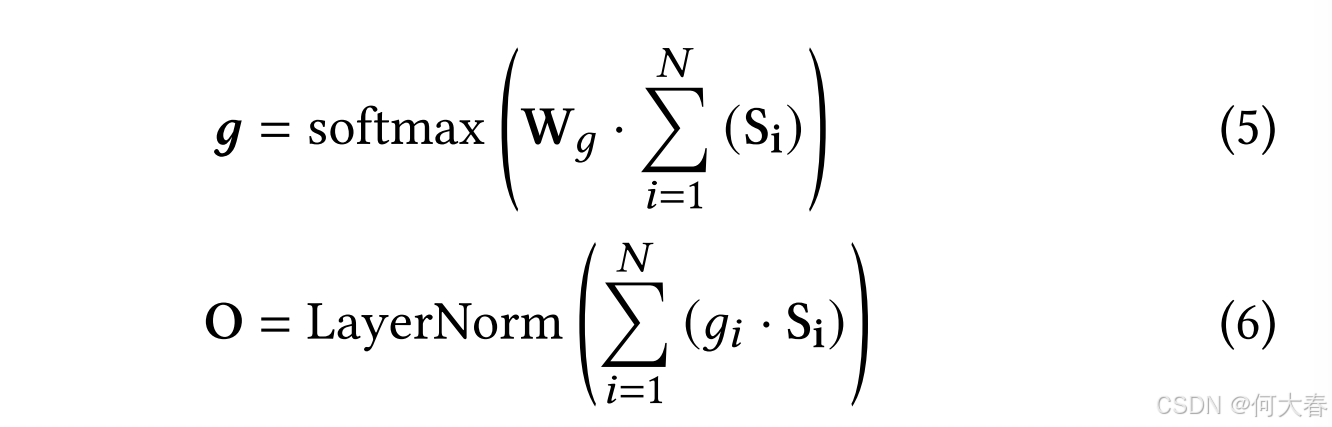
其中,LayerNorm
(
⋅
)
(\cdot)
(⋅)表示层归一化
[
1
]
[1]
[1],
g
i
g_i
gi(
g
g
g中的第
i
i
i个条目)表示第
i
i
i个专家的权重,
S
i
\mathbf{S}_\mathbf{i}
Si表示第
i
i
i个空间专家的输出,
N
N
N是空间专家的总数,
W
g
\textbf{W}_g
Wg是可训练的权重矩阵。
3.2 Spatial Imbalance Regulator
在建模空间信息之后,我们设计了一个空间不平衡调节器(SIR),其中包括一个门控空间平衡损失(GSB),以应对全局-局部空间平衡的挑战,具体如下。
Gated Spatial Balancing (GSB) Loss.
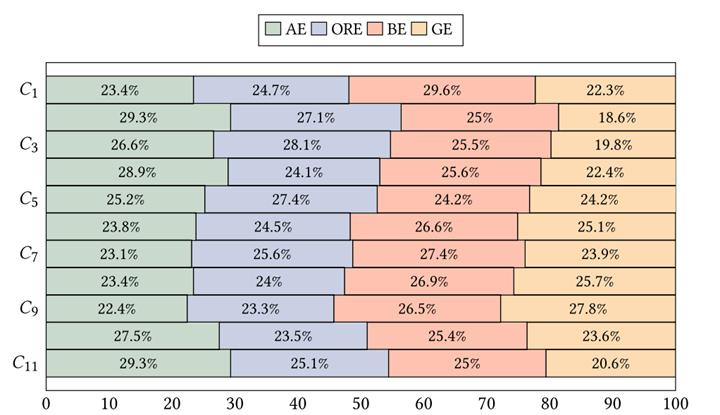
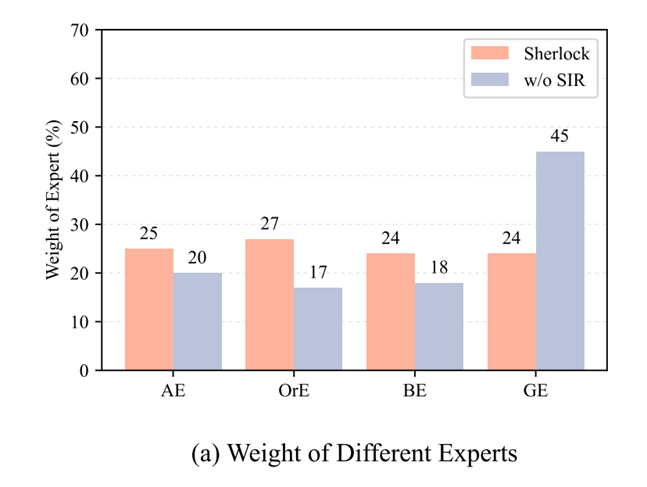
门控空间平衡(GSB)损失。先前的研究采用基本的混合专家(MoE)[18, 23]来建模全局和局部空间信息。当面对这两类信息之间的不平衡时,分配给专家的权重往往会偏向于出现频率更高的信息。如图1(c)所示,在事件四元组中,与局部空间动作信息相关的空间元素(例如人)最多。这意味着当面对未被动作专家处理(例如对象关系)的真实数据时,性能会下降。更严重的是,如图1(c)所示,全局信息在所有数据中占据重要权重,这将导致全局专家过度训练,并削弱权重较低的局部专家的能力。这种不平衡现象将极大地影响我们模型的性能。基于此,我们应保持所有空间专家的权重差异不大,并实现每个专家都充分训练的相对平衡的最佳状态。受MoELoRA [42]的启发,我们提出了一种门控空间平衡(GSB)损失来平衡空间权重,如下所示:
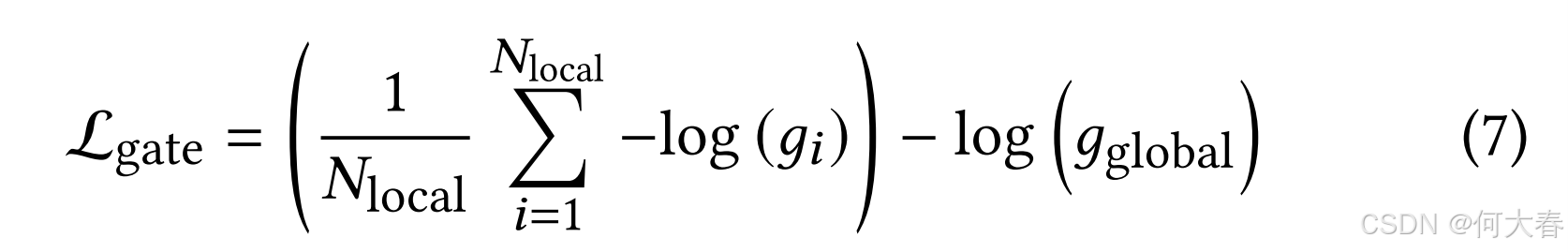
其中, N l o c a l N_\mathrm{local} Nlocal是局部专家的数量, g g l o b a l g_\mathrm{global} gglobal是全局专家的权重。公式(7)的第一项是局部专家之间的平衡,第二项是局部专家与全局专家之间的平衡。当损失优化到最小值时,四个专家的权重已经平衡。这种调节在所有专家之间实现了更好的平衡,减少了数据不平衡的影响,有效解决了全局-局部平衡的挑战。最终,Sherlock的总体损失可以表示为:
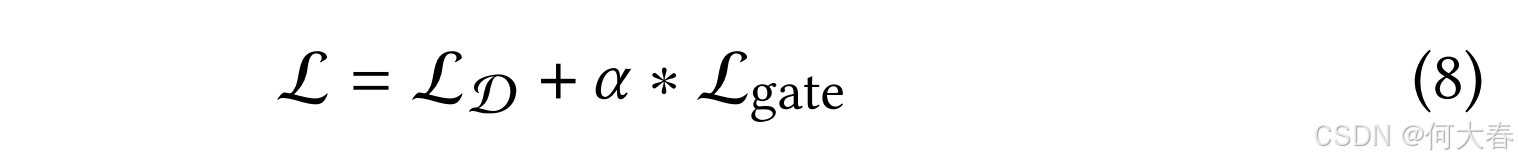
其中,
α
\alpha
α是控制
L
g
a
t
e
\mathcal{L}_{gate}
Lgate强度的超参数,
L
D
\mathcal{L}_D
LD是视频大语言模型的下一个标记预测损失。
3.3 Training Strategies for Sherlock
为了增强对空间信息的理解能力,我们设计了一个两阶段的训练过程。第一阶段旨在增强对空间信息的理解能力,第二阶段则专注于解决M-VAE任务,具体如下。
Stage 1. Pre-Tuning for spatial understanding.
如图4所示,我们首先使用四个高质量数据集对Video-LLaVA进行预调优。我们的目标是让Video-LLaVA具备良好的空间理解能力。具体来说,我们选择了四个高质量数据集:HumanML3D [16]、Ref-L4 [3]、RSI-CB [32]和COCO-Caption [39],如第4.1节所述。对于每个预调优数据集,我们使该数据集能够理解相应的空间信息。
Stage 2. Instruction Tuning for M-VAE task.
我们的目标是使模型能够通过聊天范式定位异常事件并提取四元组。我们构建了一个指令调优数据集(如第4.1节所述),并指导预调优的Video-LLaVA提取四元组并定位异常事件。四元组包括异常事件中的主体、事件类型、对象和场景。指令将经过文本嵌入以获得文本标记 T t \mathbf{T}_{\boldsymbol{t}} Tt。最终,LLM的输入为“来自公式(5)的 O \mathbf{O} O + T t \mathbf{T}_{\boldsymbol{t}} Tt”。
4 Experimental Settings
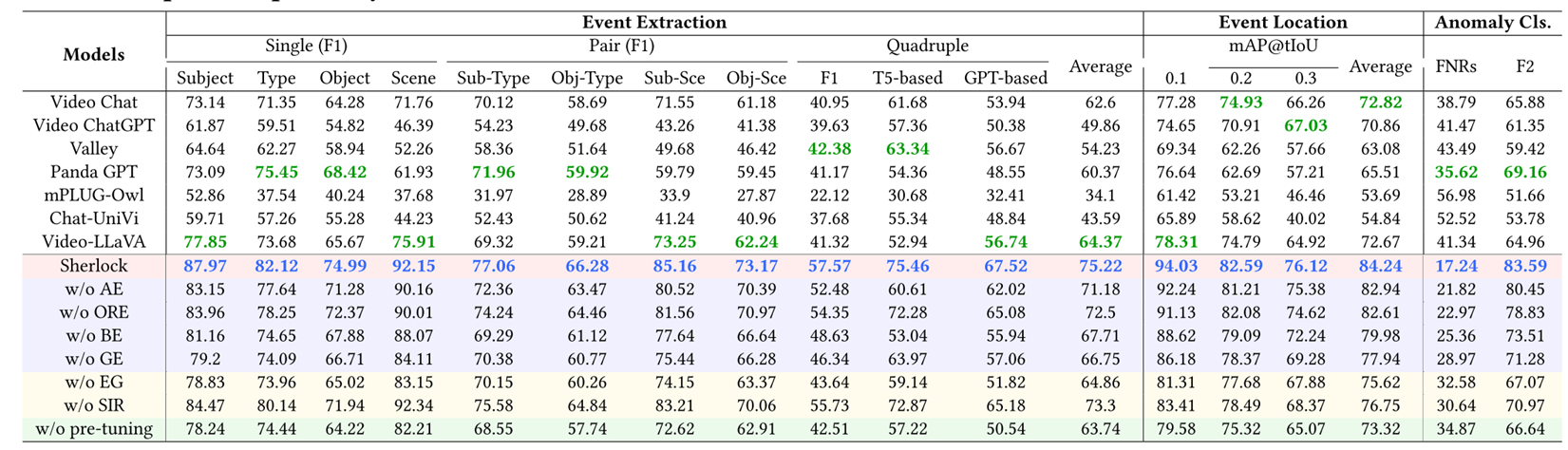

6 Conclusion
在本文中,我们首先提出了一种新的M-VAE任务并构建了一个指令数据集,为未来异常事件的研究做出了重要贡献。其次,我们提出了一种名为Sherlock的全局-局部空间敏感LLM(大语言模型),用于辅助定位和提取异常事件四元组。该模型包含一个全局-局部空间增强的MoE模块以及空间不平衡正则化机制,用于建模和平衡空间信息。最终,我们的实验结果证明了Sherlock的卓越性能。在未来的工作中,我们希望能够考虑事件之间的关系,并通过事件推理来丰富任务,以提升提取性能。此外,我们还希望通过为每个异常事件提供解释来提升模型的可解释性。

















 3581
3581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









