






文章目录
一、前言
随着 DeepSeek AI 大模型的崛起,近期私有化部署逐渐成为行业趋势。常见的部署方式之一是使用 Ollama,这对于个人用户具非常友好无需复杂的配置就能够启动。然而,相比于专业的推理引擎,如 SGLang、vLLM,Ollama 在性能上存在一定差距。
今天带大家部署的是企业级满血版的Deepseek-R1 671B,不量化,不蒸馏版。将结合 vLLM + Ray 技术来高效部署分布式 DeepSeek-r1 满血版推理集群。
**简介:**vLLM 是一个高效的大语言模型(LLM)推理和服务库,它通过
PagedAttention等优化技术提高了吞吐量。Ray 是一个分布式计算框架,可以轻松扩展计算密集型应用程序。结合这两种技术,可以创建高效的分布式 LLM 部署解决方案。
二、环境准备
模型下载
在Linux环境下载后的完整
DeepSeek-R1模型大小为640G左右,请确保你有1T的文件存储空间
1.使用魔搭SDK下载DeepSeek-R1模型
# 安装ModelScope
pip3 install modelscope
# 下载模型
mkdir -p /models/deepseek-r1
nohup modelscope download --model deepseek-ai/DeepSeek-R1 --local_dir /models/deepseek-r1 &
2.查看模型使用磁盘空间
root@notebook-8c6b949f-6kgwn:~# du -sh --block-size=G /models/deepseek-r1/
642G /models/deepseek-r1/

三、软硬件环境介绍
1.硬件配置
| 服务器 | 卡数 | 数量(台) | CPU(核) | 内存 | 系统版本 |
|---|---|---|---|---|---|
| NVIDIA H100 80GB HBM3 | 8卡 | 2 | 160/台 | 1760.00G/台 | Ubuntu 22.04.5 LTS |
2.软件工具
| 软件 | 版本 | 备注 |
|---|---|---|
| CUDA | 12.2 | |
| MLNX_OFED | 24.10-0.7.0.0 | IB驱动 |
| NCCL | 2.21.5 | GPU多卡通信 |
| vllm | 0.7.2 | LLM推理引擎 |
| ray | 2.42.0 | 分布式计算框架 |
四、检查机器互通
- 请一定要保证这几台机器网络是互通的,并记录IP地址。
安装依赖
如果你使用的是vllm+Ray的Docker镜像,则不需要安装以下依赖,如果不是,就需要安装如下依赖:
pip install vllm ray[default] openai transformers tqdm
五、基本部署流程
1. 启动Ray集群
首先,选择一台机器作为主节点,在主节点上启动Ray集群的head节点:
# 在主节点上执行
nohup ray start --block --head --port=6379 > ray.log &
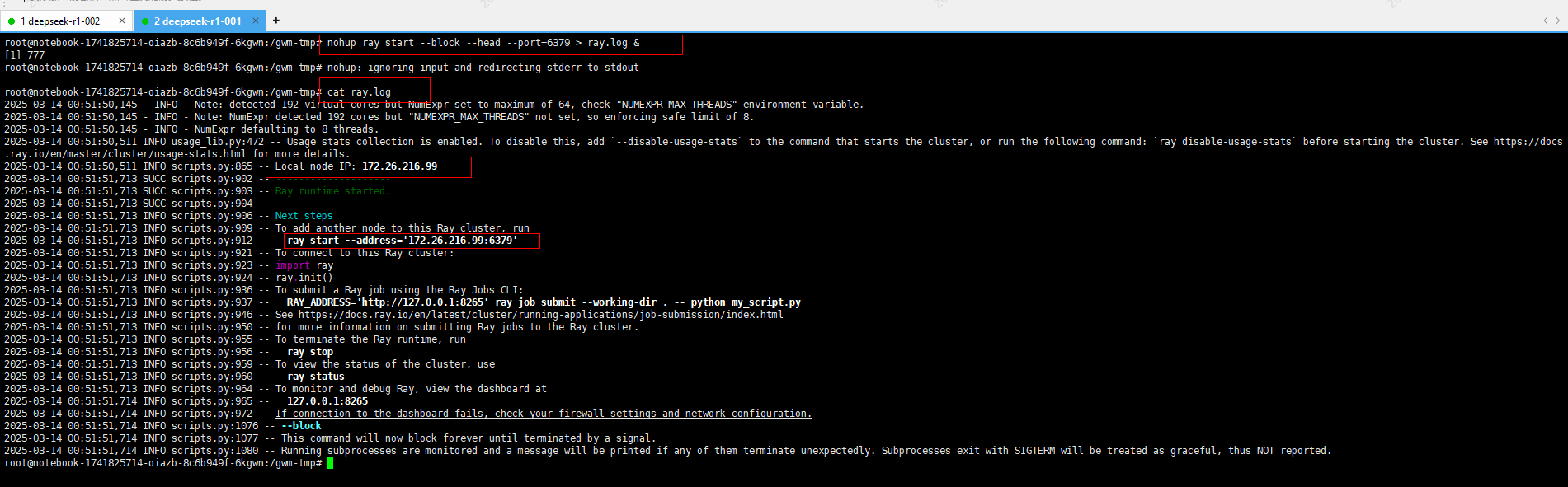
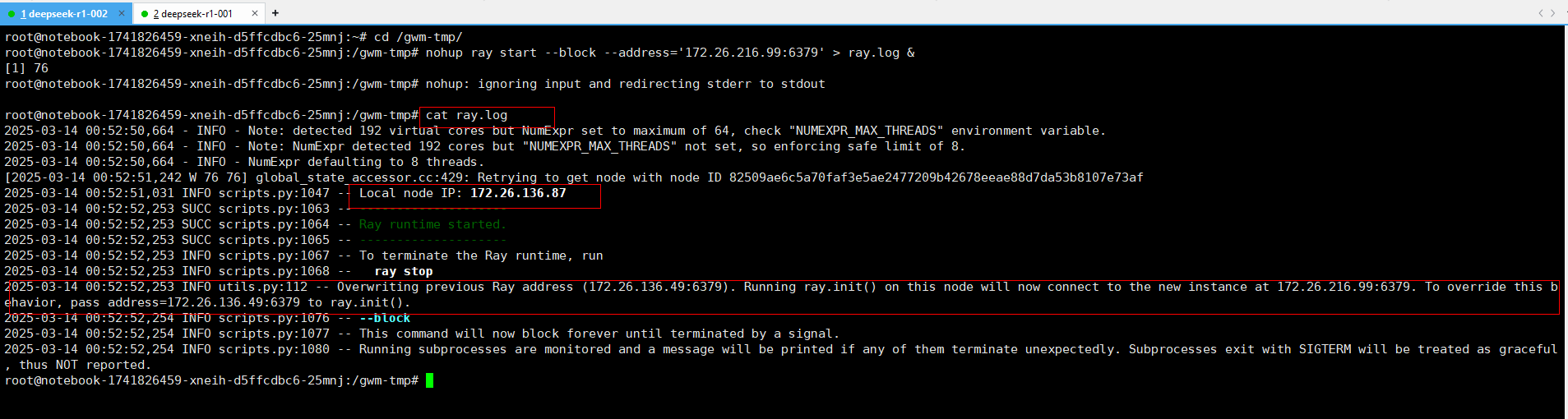
其他都是worker,在其他工作节点上执行以下命令加入集群:
# 在每个工作节点上执行(替换<master IP>为主节点IP地址)
nohup ray start --block --address='<master IP>:6379' > ray.log &
2. 使用vLLM的分布式推理服务
vLLM提供了vllm命令行工具,可直接启动分布式推理服务。以下是启动服务命令:
# 在集群head节点上执行
nohup bash -c 'NCCL_NVLS_ENABLE=0 vllm serve /models/deepseek-r1/DeepSeek-R1/ --enable-reasoning --reasoning-parser deepseek_r1 --trust-remote-code --tensor-parallel-size 16 --host 0.0.0.0 --port=9001 --served-model-name DeepSeek-R1 --gpu-memory-utilization 0.8 --max-model-len 32768 --max-num-batched-tokens 32768 --quantization fp8' > vllm_deepseek_r1.log 2>&1 &
参数说明:
-
NCCL_NVLS_ENABLE=0: 禁用NVIDIA集合通信库(NCCL)的NVLS功能。NVLS是NVIDIA Library Services的缩写,禁用它可以解决某些集群环境中的通信问题。 -
vllm serve: 启动vLLM的服务模式,使模型作为API服务持续运行,而非一次性推理。 -
/models/deepseek-r1/DeepSeek-R1/: 模型的本地路径,指向存储DeepSeek-R1模型权重和配置文件的目录。 -
--enable-reasoning: 启用vLLM的推理功能,允许模型执行更复杂的推理任务,如分步骤解决问题。 -
--reasoning-parser deepseek_r1: 指定使用DeepSeek-R1模型特定的推理结果解析器。该解析器负责处理模型输出中的推理步骤和中间结果。 -
--trust-remote-code: 允许加载和执行模型中包含的自定义代码。这对于使用自定义模块的模型(如DeepSeek)很重要,但需要确保模型来源可信。 -
--tensor-parallel-size 16: 设置张量并行度为16,意味着模型将被分割到16个GPU上运行。这种拆分方式使得超大模型能够在多个GPU上高效运行,每个GPU仅存储并计算模型的一部分。 -
--host 0.0.0.0: 服务绑定到所有网络接口,允许从外部网络访问服务。如果只想本地访问,可以设置为127.0.0.1。 -
--port=9001: 设置服务监听的TCP端口为9001。客户端将通过此端口连接到vLLM服务。 -
--served-model-name DeepSeek-R1: 在API中暴露的模型名称,客户端可以通过这个名称请求模型服务。这在服务多个模型时特别有用,可以区分不同模型实例。 -
--gpu-memory-utilization 0.8: 设置GPU内存使用率上限为80%。这为系统操作和可能的波动留出了20%的缓冲空间,避免内存溢出错误。 -
--max-model-len 92768: 设置模型能处理的最大序列长度(token数)为92,768。这是一个非常大的上下文窗口,允许处理极长的输入文本。 -
--max-num-batched-tokens 92768: 设置单个批次中允许的最大token数量,这里也设置为92,768。这影响服务处理多个并发请求的能力,更大的值允许更多并发,但需要更多内存。 -
--quantization fp8: 使用FP8(8位浮点)量化技术来减少模型内存需求。FP8是NVIDIA近期支持的高效量化格式,可以在保持较好性能的同时显著减少内存占用(相比FP16或FP32)。
六、小结
好啦,今天的分享就到这里啦! 🎉
感谢大家陪伴我一起探索如何利用 vLLM 和 Ray 技术,高效部署企业级的 DeepSeek-R1 671B 模型,打造一个性能炸裂的分布式推理集群。这篇实战指南希望能为你的AI部署之旅带来一些灵感和帮助!💡
如果你觉得这篇文章对你有启发,麻烦动动小手 点赞、分享 给更多的小伙伴,让我们一起学习、一起进步!🚀 你的支持是我持续创作的最大动力!💪
再次感谢大家的阅读! 下期见,期待下次为大家带来更多干货和精彩内容!👋
七、参考文献
- K8S部署分布式DeepSeek-r1:671b推理集群
- VLLM 本地部署 DeepSeek-R1 671B FP8
https://docs.vllm.ai/en/stable/serving/distributed_serving.html



















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











