








加载方法





此数据集不自带,需要另行下载


今日内容:


可在线下载数据集:

第一个:20类新闻文本数据集
两个子集:训练集和测试集

20组文本数据集API用法详解:







第二部分:文本内容转换为特征向量

ctrl+左键可以查看语言含义
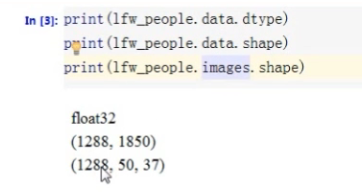
野外带标记人脸数据集



用于野外人脸识别的带标记人脸数据集详解



预测森林表面植被类型的数据集,是个多累分类任务数据集。来自美国的森林数据,UCI数据集。每个样本包含54个特征,其中含有布尔类型的特征。

计算机生成的数据集
类别:
用于分类任务的
用于回归任务的
用于聚类人物的
用于流行学习任务的
用于因子分解任务的

用于分类任务和聚类任务的:这些函数产生样本特征向量矩阵以及对应的类别标签集合
make_blobs:多类单标签数据集,为每个类分配一个或多个正态分布的点集,提供了控制每个数据点集的参数:中心点(均值),标准差,常用于聚类算法
make_classification:多类单标签数据集,为每个类分配一个或多个正态分布的点集。提供了为数据集添加噪声的方式,包括纬度相关性,无效特征以及冗余特征等。
make_gaussian_quantiles:将一个单高斯分布的点集划分为两个数量均等的点集,作为两类。
make_hastie_10_2:产生一个相似的二元分类数据集,有10个纬度。
make_circles和 make_moons产生二维二元分类数据集来测试某些算法(e.g.centroid-based clustering或linear classification)的性能。可以为数据集添加噪声。可以为二元分类器产生一些球形判决界面的数据。

make_blob
import numpy as np
import matplotlib.pyplot as plt
from sklearn. datasets.samples_generator import make_blobs
centers = [[1,1],[-1,-1],[1,-1]] #指定每个cluster的中心cluster_std = 0.3#每个cluster的标准差
X, labels = make_blobs(n_samples=200,centers=centers,n_features=2,
cluster_std=cluster_std,random_state=o)
print(' X.shape: ', X.shape)
print (’ 1abels: ', set(labels))
#将二维点集绘制出来
unique_labels = set(labels)
colors = plt.cm.Spectral (np.linspace(0, 1,len(unique_labels)))
for k, col in zip(unique_labels,colors):
x_k = X[labels == k]
plt.plot(X_k[:,o],X_k[:,1], 'o', markerfacecolor=col,
markeredgecolor='k', markersize=14)
plt.title(' dataset by make_blob()’)
plt.show)


用于多标签分类任务的
make_multilabel_classification:产生多标签随机样本。这些样本模拟了从很多话题的混合分布中抽取的词袋模型。每个文档的话题数量服从泊松分布,话题本身则从一个固定的随机分布中抽取出来。同样的,单词数量也是从泊松分布抽取,句子则是从多项式分布中抽取的。
与真实的词袋模型相比,做了一下简化操作:
1、每个话题的词汇分布是独立的,这在实际情形下通常不成立。
2、对于一个有多个话题产生的文档,所有话题在产生词袋模型时的权重是相同的。
3、没有标记词汇的文档是随机产生,而不是基于某个基础分布。

用于回归任务的
make_regression产生回归任务的数据集,期望目标输出是随机特征的稀疏随机线性组合,并且附带有噪声。它的有用特征可能是不相关的,或者低秩的(引起目标值的变动的只有少量的几个特征)。
make_sparse_uncorrelated :产生四个特征的线性组合(固定系数)作为期望目标输出。
下面的这几个采用了非线性相关的方式来组合特征:make_friedman1采用了多项式和正弦变换
make_friedman2包含了特征的乘积以及互换操作。make_friedman3类似于arctan变换.

用于流行学习的

用于因子分解的
















 398
398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









