






一、循环神经网络与NLP
1. 序列模型
(1)分类问题与预测问题
图像分类:由当前输入得当前输出
时间序列预测:由当前与过去得输入预测当前输出
(2)自回归模型

2. 数据预处理
(1)特征编码

从上图中可以看到三种类别特征,年龄,性别,国籍,其中年龄可以用数字直接表示;性别只有两种,可以令男性为0,女性为1;国籍可以用一个整数来表示,或者用一个独热向量(One-Hot编码:对于颜色特征,如果可能的取值有红、绿、蓝三种,则红色可能表示为[1, 0, 0],绿色表示为[0, 1, 0],蓝色表示为[0, 0, 1])来表示,国家编码从1开始,1~197,因为实际国籍有可能不填(对应0),故可以使用199维特征向量表示一个人的特征:

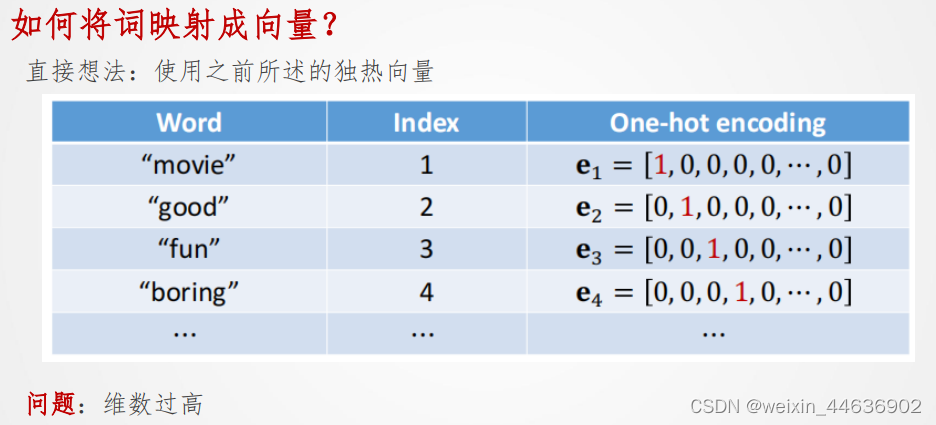
(2)文本处理
[a] 按字母处理

[b] 按单词处理

3. 文本处理与词嵌入
(1)文本预处理
- 将文本作为字符串加载到内存中;
- 将字符串切分为词元(如单词和字符);
- 建立一个字典,将拆分的词元映射到数字索引;
- 将文本转换为数字索引序列,方便模型操作。



(2)文本嵌入
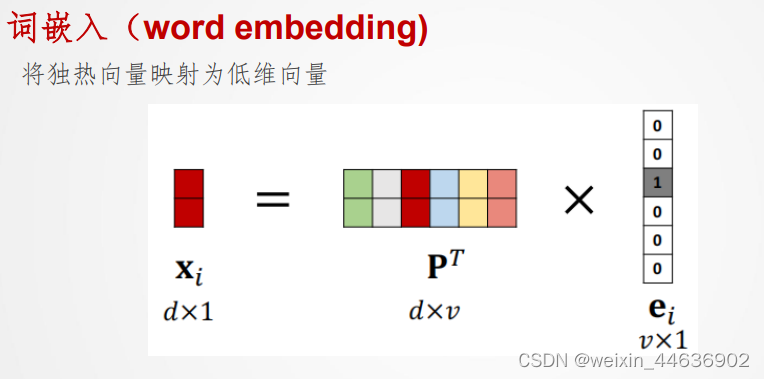
对于原始向量 为v维;经过映射矩阵(根据训练数据学习得到),得到映射后的d维向量,d<<v
4. RNN模型
(1)RNN概要
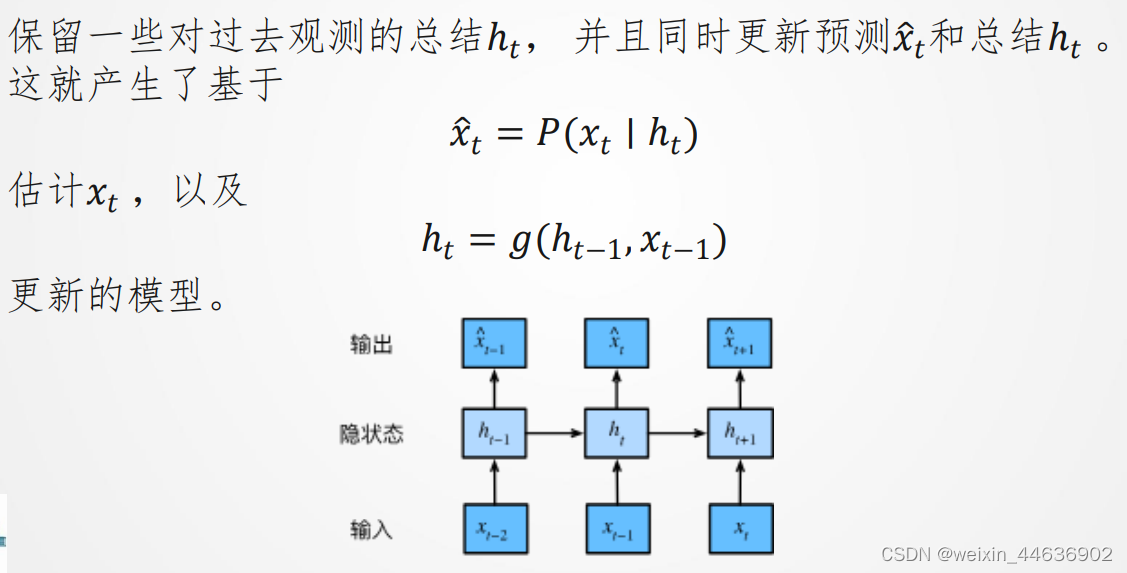
如何建模序列数据?
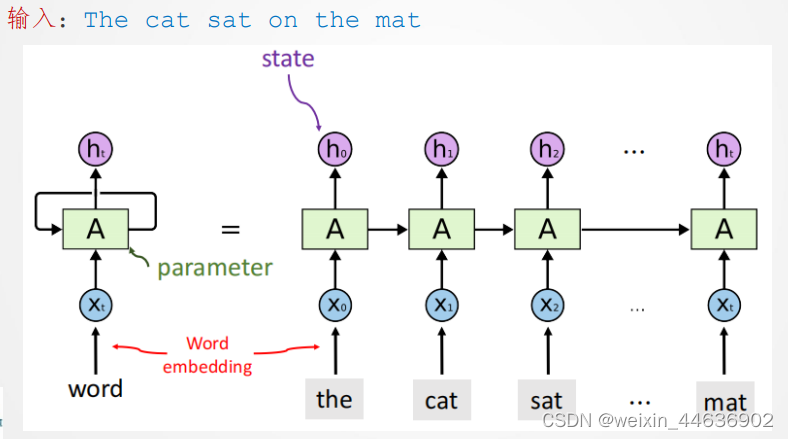
在每个时间步上,RNN接受输入序列中的一个元素和上一个时间步的隐藏状态,并输出当前时间步的隐藏状态。
(2)RNN模型
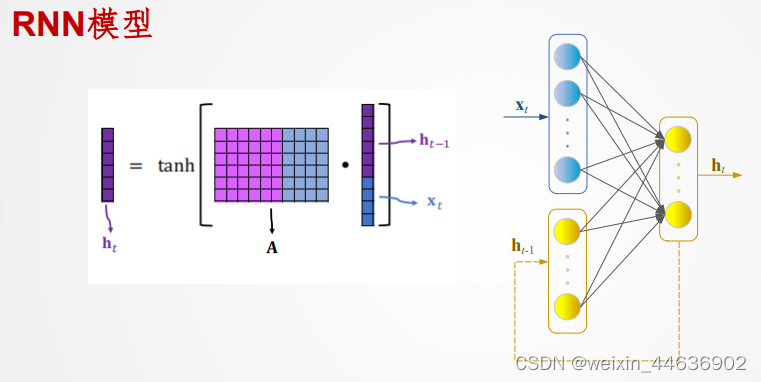
利用序列中的时间信息,并且可以通过保留隐藏状态来捕捉序列中的长期依赖关系。RNN模型由一个或多个循环单元组成,每个循环单元都有一个内部状态(隐藏状态),用于存储过去的信息,并在下一个时间步传递给自身。这种内部状态的反馈机制使得RNN能够处理任意长度的序列输入。
(3)RNN问题
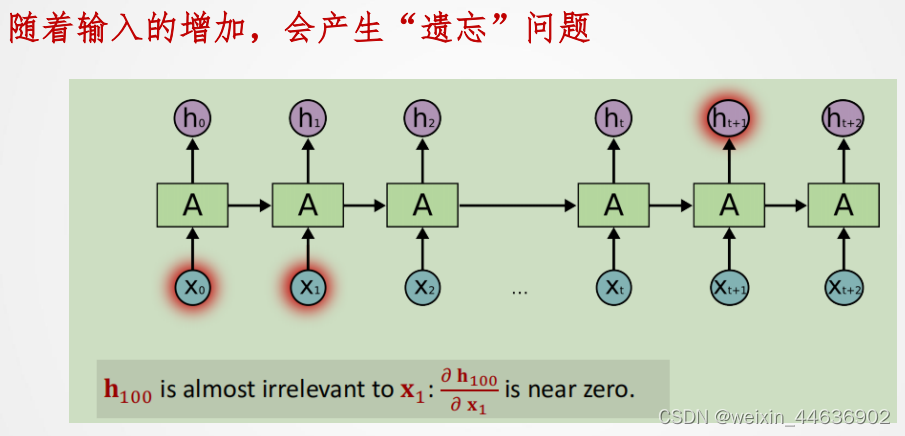
5. RNN误差反传


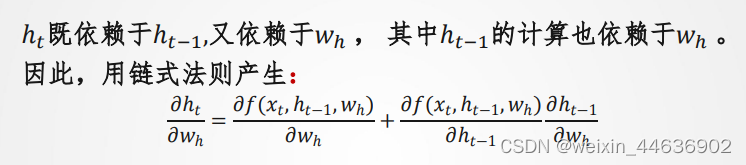


-
梯度消失和梯度爆炸:在训练过程中,RNN很容易遇到梯度消失或梯度爆炸的问题。这是由于反向传播过程中梯度在多个时间步长内连续相乘或相加,导致梯度指数级增加或减小。
-
长期依赖建模困难:简单的RNN很难有效地捕捉长期依赖关系,因为随着时间的增长,信息需要通过多个时间步长传播,容易出现梯度消失或信息遗忘的问题。
-
内部状态限制:RNN的内部状态大小是固定的,这限制了其对长序列的处理能力。当序列很长时,RNN可能会丢失关键信息或受限于固定大小的内部状态。
-
并行计算效率低:由于RNN模型的时间步骤之间存在依赖关系,导致难以有效地并行化计算,限制了其在大规模数据上的训练速度。
为了解决这些问题,研究人员提出了许多改进的RNN变体,如门控循环单元(GRU)、长短期记忆网络(LSTM)等,以及其他结构如Transformer等。这些变体通过引入门控机制、跳跃连接等方式来改善长期依赖建模能力,解决梯度消失问题,并提高并行计算效率。
6. 门控循环单元(GRU)
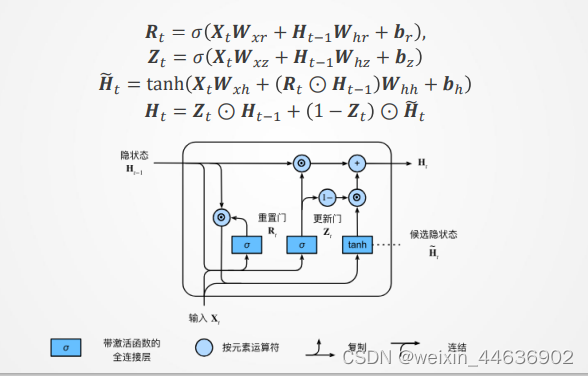
- 更新门(Update Gate): 决定了在当前时间步长,应该如何将过去的记忆信息与当前的输入进行结合。它控制了过去记忆信息的保留程度,以及新信息的重要程度。输出范围在0到1之间,表示需要保留的过去记忆信息的比例。
- 重置门(Reset Gate): 决定了在当前时间步长,应该如何考虑过去的记忆信息。它控制了过去记忆信息的遗忘程度,以及新信息的影响程度。输出范围在0到1之间,表示过去记忆信息的遗忘比例。
- 隐藏状态更新:基于更新门和重置门的输出,GRU根据当前输入和过去隐藏状态计算新的隐藏状态。更新门决定了过去记忆信息的保留程度,重置门决定了过去记忆信息的遗忘程度,二者结合起来影响了新的隐藏状态的生成。
- 门控机制:GRU利用门控机制来调节信息的流动,从而解决了长期依赖问题和梯度消失问题。通过更新门和重置门,GRU可以在不同的时间步长上自适应地调整过去信息的保留和遗忘程度,从而更有效地捕捉序列中的长期依赖关系。
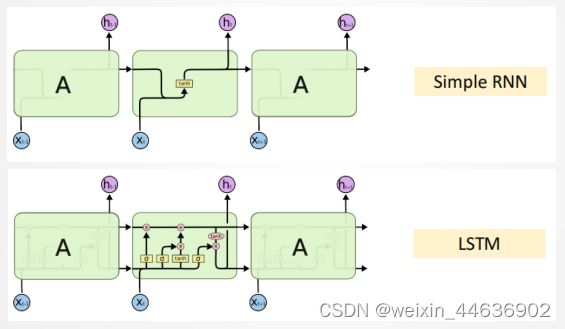
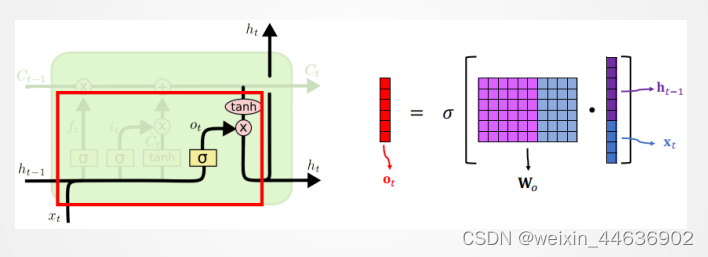
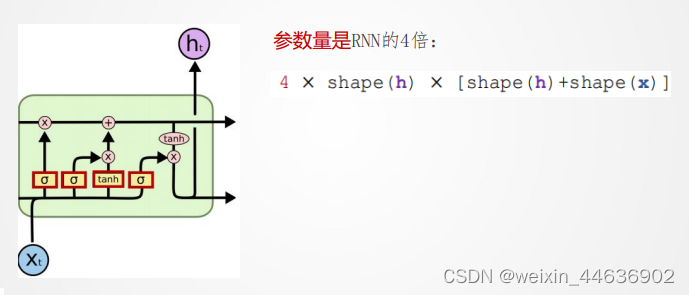
7. 长短期记忆网络(LSTM网络)
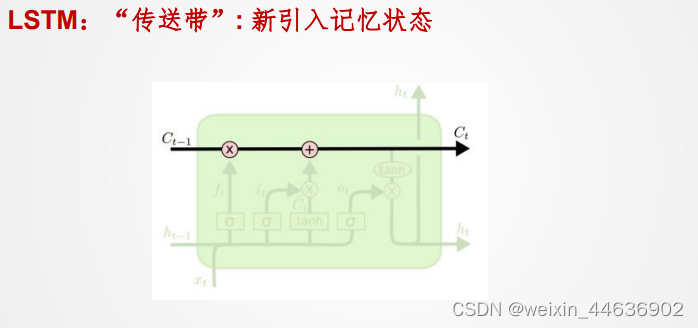
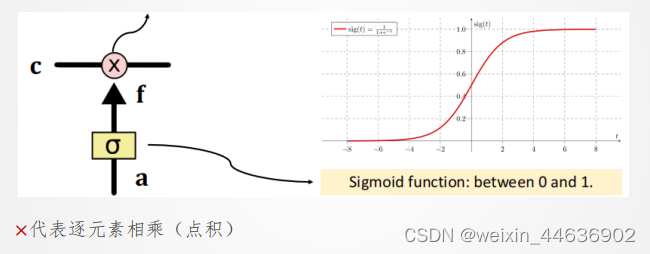
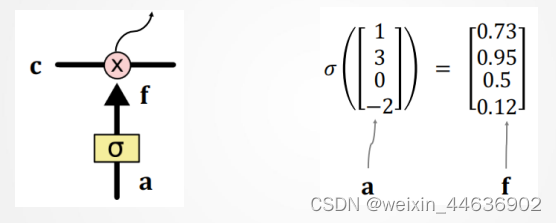
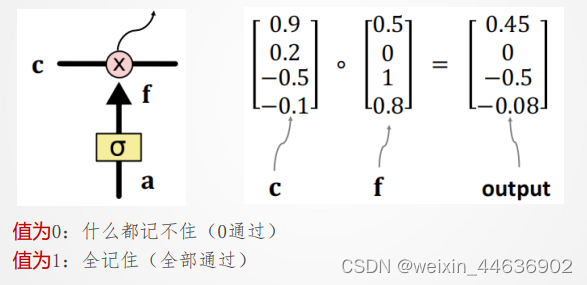
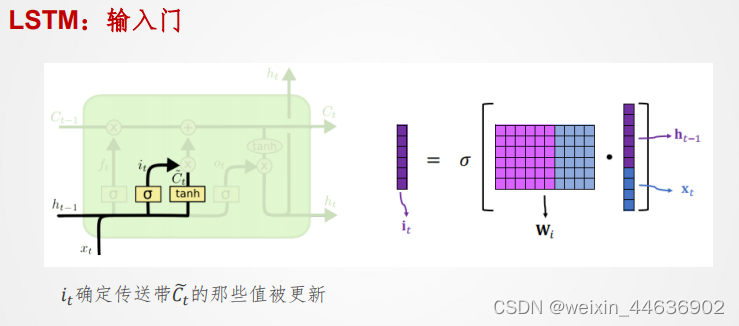
新值 加到
上
二、生成对抗网络
生成对抗网络其整体结构如下:
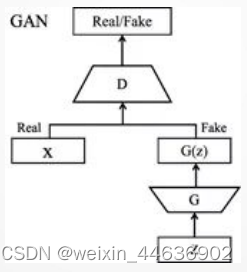
生成对抗网络(GAN)的初始原理十分容易理解,即构造两个神经网络,一个生成器,一个鉴别器,二者互相竞争训练,最后达到一种平衡(纳什平衡)。 GAN 启发自博弈论中的二人零和博弈(two-player game),GAN 模型中的两位博弈方分别由生成式模型(generativemodel,G)和判别式模型( discriminative model,D)充当。
生成模型 G 捕捉样本数据的分布,用服从某一分布(均匀分布,高斯 分布等)的噪声 z 生成一个类似真实训练数据的样本,追求效果是越 像真实样本越好。
判别模型 D 是一个二分类器,估计一个样本来自于训练数据(而非生 成数据)的概率,如果样本来自于真实的训练数据,D 输出大概率, 否则,D 输出小概率。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









