




一、基本卷积神经网络
1. AlexNet

论文传送门:http://cs.toronto.edu/~fritz/absps/imagenet.pdf

AlexNet 的网络结构如上图所示,1个输入层(227*227*3),224据说是写论文时的笔误,5个卷积层(C1、C2、C3、C4、C5)、3个全连接层。AlexNet的出现,在深度学习的历史上具有里程碑的意义,其证实了深度学习在解决复杂模式识别问题上的巨大潜力,同时也促进了GPU等并行计算技术在AI领域的广泛应用。
主要创新点
(1)深层架构
AlexNet采用了比早期神经网络更深的结构,它包含8层(包括5个卷积层和3个全连接层),证明了通过增加网络层次可以提取更复杂、更高层次的特征表示,并显著提高了图像识别任务的性能。

如图1所示,其左侧为连接数,右侧为参数。
(2)输入样本
对图像数据采取水平翻转,随机裁剪,光照或彩色变换等操作,有效提升了模型的泛化能力。

但是如上图所示目标,其不采取上下翻转的方式,因上下翻转不符合物体在实际中存在的状态。
(3)激活函数
采取ReLU替代Tan Sigmoid;
用于卷积层与全连接之后;
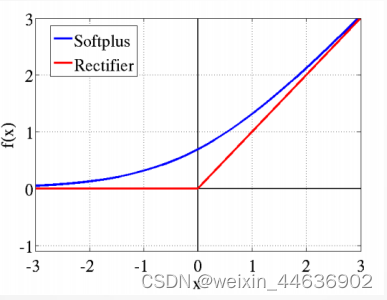
传统的神经网络普遍使用Sigmoid或者tanh等非线性函数作为激励函数,然而它们容易出现梯度弥散或梯度饱和的情况。以Sigmoid函数为例,如下图所示,当输入的值非常大或者非常小的时候,值域的变化范围非常小,使得这些神经元的梯度值接近于0(梯度饱和现象)。由于神经网络的计算本质上是矩阵的连乘,一些近乎于0的值在连乘计算中会越来越小,导致网络训练中梯度更新的弥散现象,即梯度消失。
而ReLU不存在这种缺陷,其不会出现值域变化小的问题。
(4)Dropout
在每个全连接层后面使用一个 Dropout 层,以概率 p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









