









 Grad-CAM是一种用于理解深度学习模型决策过程的可视化技术。通过计算特定层的特征图与目标类别的权重,Grad-CAM能生成高分辨率的热力图,突出显示模型关注的输入区域。这一过程涉及权重计算、线性组合以及ReLU激活,最终生成的CAM图可放大并与原始图像叠加,提供直观的解释。
Grad-CAM是一种用于理解深度学习模型决策过程的可视化技术。通过计算特定层的特征图与目标类别的权重,Grad-CAM能生成高分辨率的热力图,突出显示模型关注的输入区域。这一过程涉及权重计算、线性组合以及ReLU激活,最终生成的CAM图可放大并与原始图像叠加,提供直观的解释。
CNN卷积一直都是一个神秘的过程
过去一直被以黑盒来形容
能够窥探CNN是一件很有趣的事情, 特别是还能够帮助我们在进行一些任务的时候
了解模型判别目标物的过程是不是出了什么问题
而Grad-CAM就是一个很好的可视化选择
因为能够生成高分辨率的图并叠加在原图上, 让我们在研究一些模型判别错误的时候, 有个更直观的了解
那么具体是如何生成Grad CAM的呢?
老规矩先上图, 说明流程一定要配图
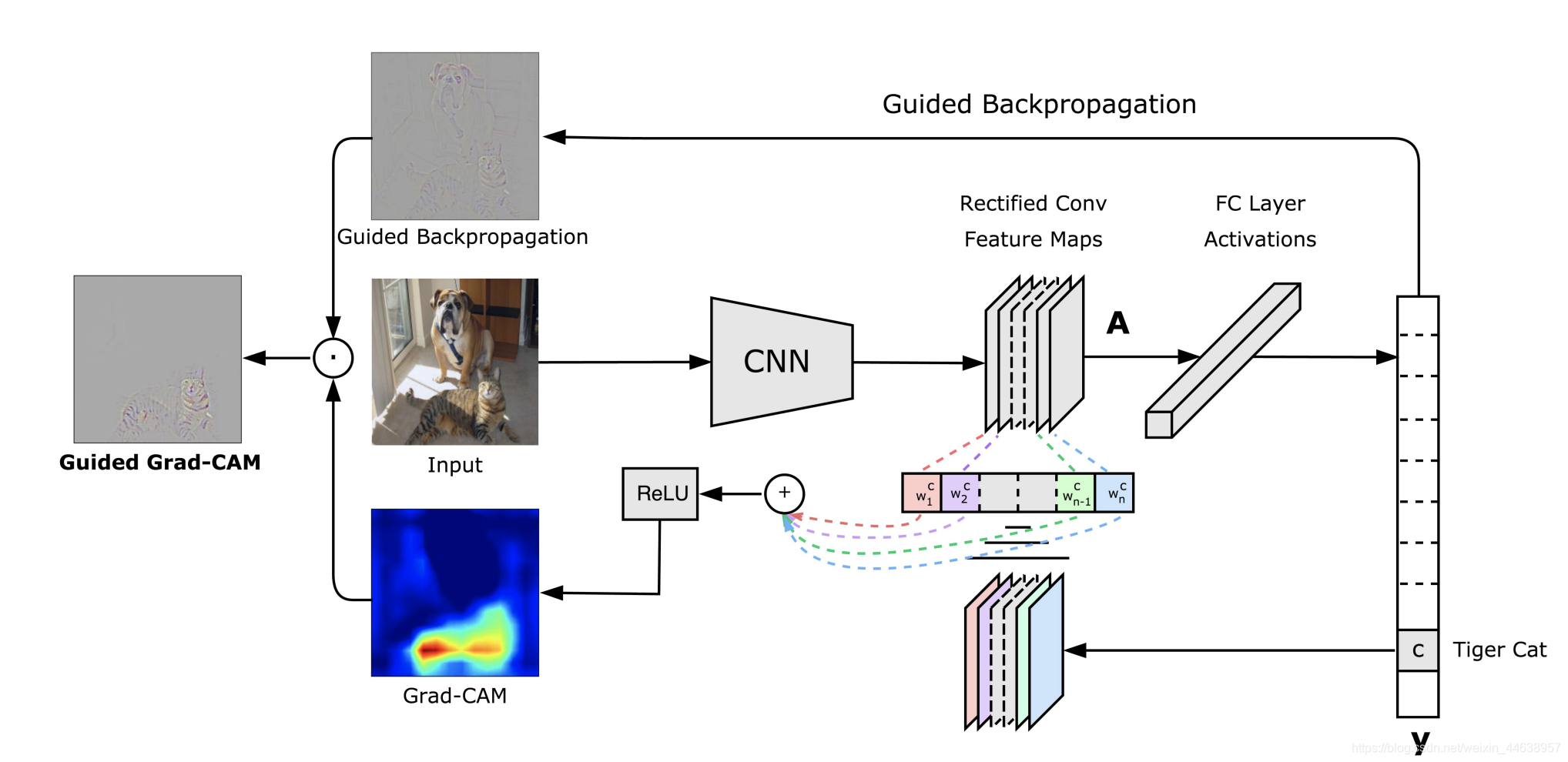
借用一下论文作者的图
我们能看到Input的地方就是我们要输入进网络进行判别的
假设这里输入的input 类别是 Tiger cat
一如往常的进入CNN提取特征
现在看到图中央的Rectified Conv Feature Maps 这个层就是我们要的目标层, 而这个层通常会是整个网路特征提取的最后一层, 为什么呢? 因为通常越深层的网络越能提取到越关键的特征, 这个是不变的
如果你这边可以理解了就继续往下看呗
我们能看到目标层下面有一排的
w
1
c
w
2
c
.
.
.
.
w_1^c w_2^c....
w1cw2c....等等的
这里的w就是权重, 也就是我们需要的目标层512维 每一维对类别Tiger cat的重要程度
这里的权重不要理解为前向传播的 每个节点的权重, 两者是不同的
而这些权重就是能够让模型判别为Tiger cat的最重要的依据 我们要这些权重与目标层的feature map进行linear combination并提取出来
那么该怎么求出这些权重呢?
该是上公式的时候了, 公式由论文提出
L G r a d − C A M c = R e L U ( ∑ k α k c A k ) L_{Grad-CAM}^c = ReLU(\sum_k\alpha^c_kA^k) LGrad−CAMc=ReLU(∑kαkcAk)
α k c \alpha_k^c αkc 就是我们上面说的权重
怎么求?摆出论文公式
α k c = 1 Z ∑ i ∑ j \alpha_k^c = \frac{1}{Z} \sum_i \sum_j αkc=Z1∑i∑j ∂ y c ∂ A i j k \frac{\partial y^c}{\partial A^k_{ij}} ∂Aijk∂yc
1 Z ∑ i ∑ j \frac{1}{Z} \sum_i \sum_j Z1∑i∑j 表示进行全局池化,也就是求feature map的平均值
∂ y c ∂ A i j k \frac{\partial y^c}{\partial A^k_{ij}} ∂Aijk∂yc 表示最终类别对我们要的目标层求梯度
所有我们第一步先求出
A
k
A^k
Ak 的梯度之后, 在进行全局池化求得每一个feature map的平均梯度值就会是我们要的
α
k
c
\alpha_k^c
αkc , 整个池化过程可以是下图红框处
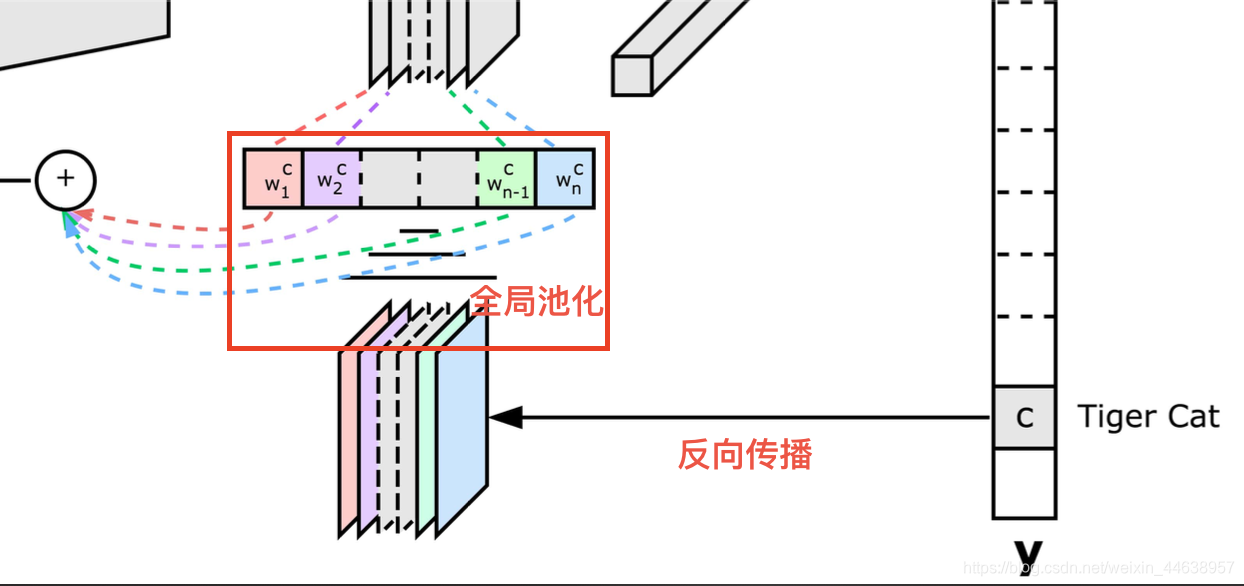
这个
α
k
c
\alpha_k^c
αkc 代表的就是 经过全局池化求出梯度平均值
w
1
c
w
2
c
.
.
.
.
w_1^c w_2^c....
w1cw2c....
也就是我们前面所说的目标层的512维 每一维对类别Tiger cat的重要程度
这边很好理解, 就是把512层feature map分别取平均值, 就取出512个均值, 这512个均值就能分别表示每层的重要程度, 有的值高就显得重要, 有的低就不重要
好的 回到 L G r a d − C A M c = R e L U ( ∑ k α k c A k ) L_{Grad-CAM}^c = ReLU(\sum_k\alpha^c_kA^k) LGrad−CAMc=ReLU(∑kαkcAk)
现在 α k c \alpha_k^c αkc 我们有了
A k A^k Ak 表示feature map A 然后深度是k, 如果网络是vgg16, 那么k就是512
把我们求得的 α k c \alpha_k^c αkc 与 A k A^k Ak两者进行相乘(这里做的就是线性相乘), k如果是512, 那么将512张feature map都与权重进行相乘然后加总 ∑ k \sum_k ∑k
好,最终在经过Relu进行过滤
我们回想一下Relu的作用是什么?
是不是就是让大于0的参数原值输出,小于0的参数就直接等于0 相当于舍弃
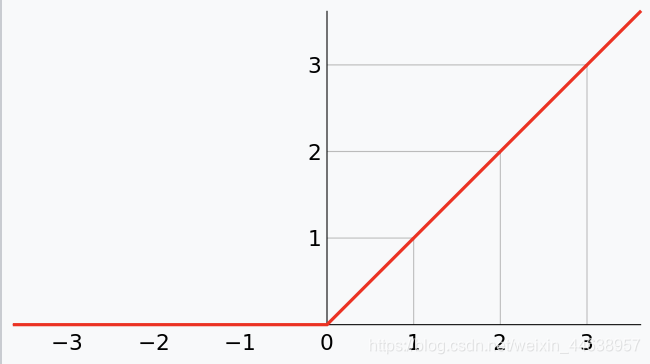
其实Relu在这里扮演很重要的角色, 因为我们真正感兴趣的就是哪些能够代表Tiger Cat这个类别的特征, 而那些小于0被舍弃的就是属于其他类别的, 在这里用不上, 所有经过relu的参数能有更好的表达能力
于是 我们就提取出来这个Tiger Cat类别的CAM图啦
那么要注意一下, 这个提取出来的CAM 大小以vgg16来说是14*14像素
因为经过了很多层的卷积
我们要将这个图进行放大到与原输入的尺寸一样大在进行叠加才能展现GradCAM容易分析的优势
当然中间有很多实现的细节包含利用openCV将色彩空间转换
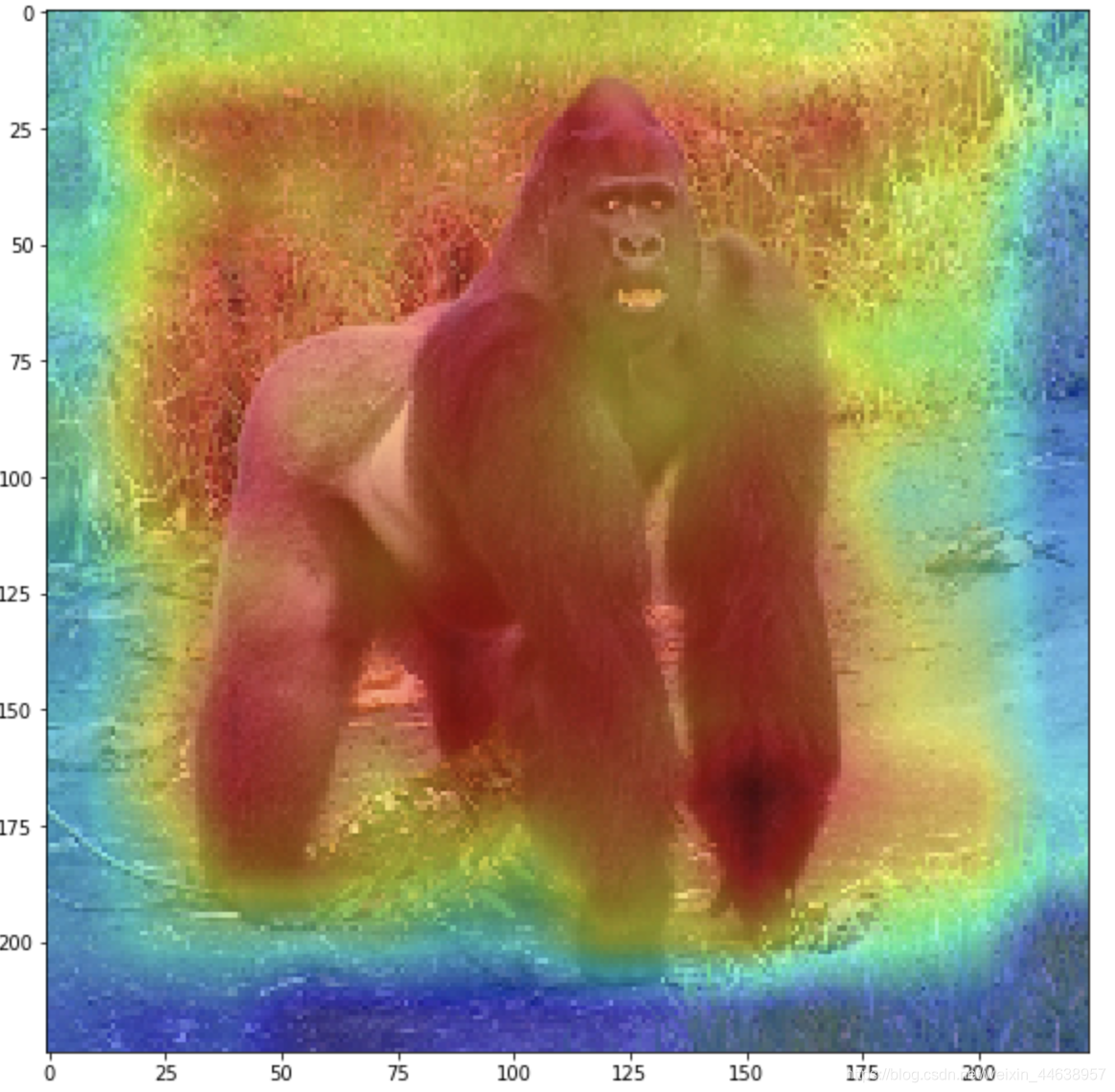
就如下图是我做的一个范例

那么是不是就很容易理解网络参数对于黑猩猩面部的权重被激活的比较多,白话的说就是网络是靠猩猩脸部来判别 哦 原来这是黑猩猩啊 !
当然这样的效果是在预训练网络上(vgg16 imagenet 1000类 包含黑猩猩类)才会有的, 预训练好的参数早就可以轻易的判别黑猩猩了
如果只是单纯的丢到不是预训练的网络会是下面这样子
所以网络需要进行训练, 随着训练, 权重会越能突显这个类别的特征
最后透过某些特定的纹路就能进行判别
好了, 需要代码自己玩一下的自取了
论文地址:https://arxiv.org/pdf/1610.02391v1.pdf
Pytorch代码实现:https://github.com/Stephenfang51/Grad_CAM_Pytorch-1.01


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









