







 该研究提出了一种基于卷积神经网络的语义分割方法,用于在全视野图像中识别和分类肾小球硬化。通过对比U-Net和SegNet,发现SegNet在两阶段分割和分类策略中表现最佳,达到98.16%的准确率。方法首先使用SegNet进行肾小球分割,随后通过AlexNet进行正常和硬化肾小球的区分,提高了诊断准确性。
该研究提出了一种基于卷积神经网络的语义分割方法,用于在全视野图像中识别和分类肾小球硬化。通过对比U-Net和SegNet,发现SegNet在两阶段分割和分类策略中表现最佳,达到98.16%的准确率。方法首先使用SegNet进行肾小球分割,随后通过AlexNet进行正常和硬化肾小球的区分,提高了诊断准确性。
肾小球分割-论文翻译1:利用语义分割在全视野图像中的肾小球硬化识别
(用于自己写毕业论文综述,机器翻译,自用)
英文题目:Glomerulosclerosis identification in whole slide images using semantic segmentation
论文地址:https://www.sciencedirect.com/science/article/abs/pii/S0169260719311381

目录结构:

摘要
背景和目的: 肾小球的鉴定,即检测和表征,是许多肾脏病理研究的关键步骤。本文提出了一种基于卷积神经网络(CNN)的语义分割方法,利用全幻灯片成像(WSI)检测肾小球,然后再用分类CNN将肾小球分为正常和硬化两个部分。
方法: 将U-Net和SegNet两种cnn的像素级分割进行比较,考虑到两类和三类问题,即a)非肾小球和肾小球结构,b)非肾小球正常结构和硬化结构。两类语义分割结果,然后用于CNN分类,其中肾小球区域分为正常和整体硬化肾小球。
结果: 这些方法在一个由47个WSIs组成的数据集上进行了测试,这些WSIs属于人类肾脏切片与周期酸希夫(PAS)染色。最好的方法是SegNet为两个类分割,然后通过一个微调AlexNet网络来描述肾小球。使用连续的CNNs (SegNet-AlexNet)进行分割和分类,获得了98.16%的准确率。
结论: 所获得的结果表明,序贯CNN分割分类策略获得了更高的准确性,减少了误分类病例,因此被提出的方法用于肾小球硬化检测。
1.介绍
肾小球是毛细血管簇,负责排出由废物和人体不需要的额外液体组成的物质。肾小球疾病可根据临床表现、词源、免疫病理或形态学改变进行分类。考虑到形态的改变,肾小球病变表现为所谓的肾小球硬化,其特征是肾小球的硬化程度取决于其是整体还是部分影响肾小球。图1所示标本为弥漫肾小球硬化,几乎所有的肾小球都完全硬化。在日常实践中,每次肾活检都应该对每次切口中发现的肾小球总数进行定量分析。每次肾活检大约需要20到30个切口。此外,还必须指出肾小球整体硬化(整个肾小球)。如果局灶性硬化症也被检测到(而不是整个肾小球),这将为病人可能患有的疾病提供线索。这应该反映在每个病理报告中,因为评估的肾小球数量必须具有足够的代表性来作出诊断。另一方面,它有助于提供充分的治疗,即如果样本有许多硬化性肾小球,则意味着有慢性肾损害,肾小球死亡,因此,患者不适合某些治疗[18]。此外,肾病学家还将这些数据纳入国家肾小球肾炎登记处。肾小球计数是非常繁琐和耗时的。因此,需要能够准确检测和分类肾小球的图像处理工具。人工智能为上述问题提供了有待探索的工具。这种被称为深度学习的新方法坚定地出现了,为病理学带来了新的视野。本文提出了一种基于深度学习的方法,更具体地说,在语义分割上,用于检测和分类的肾小球条件。
表1:
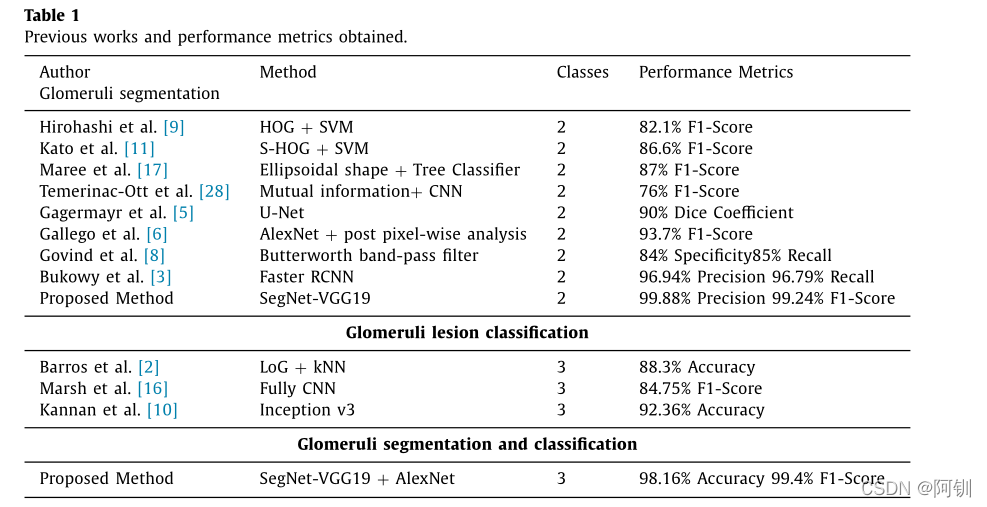
表2:
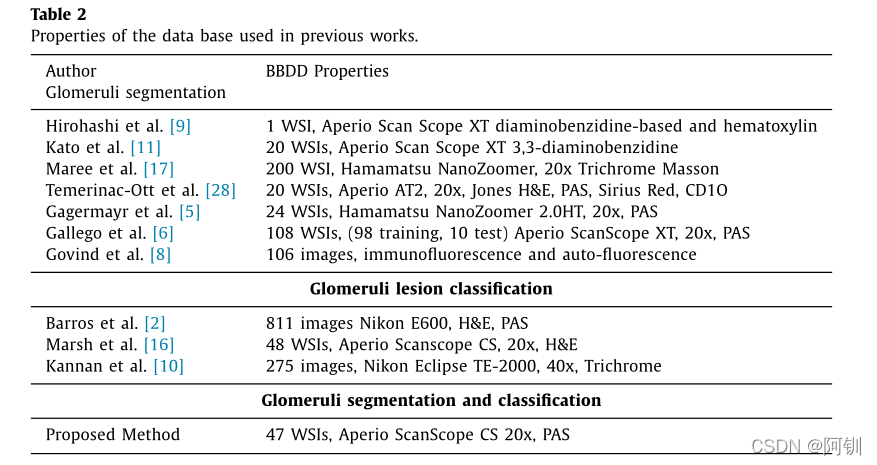
语义分割网络已经被用于组织病理学图像[14,30],但尚未用于肾小球的分割。已有的基于人工特征提取技术的图像分割准确率高达87%,分类准确率达88%。使用卷积神经网络(CNN)深度学习技术,在不同的数据集和染色上,这些值分别提高了96%和92%。表1和表2显示了所有以前的方法,获得的结果和用于将肾小球分为两类(非肾小球和肾小球)和三类(非肾小球、肾小球、硬化)的数据集。所提出的方法也包含在表格中作比较。
这篇论文的目的是双重的:
(a)进行肾小球分割
(b)对正常和硬化肾小球进行分类。
分类是利用了我们之前的研究[6,19,27]。在这方面,两种强大的语义分割方法,SegNet和U-Net已经比较了逐像素分割。U-Net已经被应用于医学图像分割,甚至在肾小球分割任务中,如表1所示。然而,这是第一次SegNet架构被应用于肾小球分割提出了一种新的策略来完成这项任务。考虑到这两个体系结构,我们进行了两个不同的实验:
- 三类语义切分。本文比较了SegNet和U-Net方法对非肾小球结构、正常肾小球和完全硬化肾小球的分割。
- 两类语义切分,然后进行分类。基于[6],提出了一种分类CNN,将语义分割得到的肾小球区域划分为正常和完整的硬化肾小球。
2.材料
2.1 AIDPATH肾脏数据库:
本研究中使用的数字组织图像来自AIDPATH肾脏数据库(见致谢)。该数据集由5个不同的人类儿童组织序列WSI数据集组成,这些数据集来自三个欧洲机构:Castilla-La Mancha的卫生保健服务(西班牙)、安达卢西亚卫生服务(西班牙)和维尔纽斯大学Hos- pital Santaros Klinikos(立陶宛)。采用外径10 ~ 300 μm的活检针采集组织标本。然后用4μm组织切片制备石蜡块,用PAS染色。PAS染色能有效染色肾脏组织中的多糖,并能突出肾小球基底膜[22]。使用徕卡Aperio ScanScope CS扫描仪进行数字WSI采集,并提取成SVS文件格式。结果,获得了47个肾脏WSIs的数据集。图像在20倍放大选择,因为这种放大保持图像质量和信息在同一al- low,以获得有价值的结果,减少计算时间sig-显着。较小的分辨率的缺点是图像质量下降,因此无法获得肾小球的信息。另一方面,像40倍的放大意味着更高的图像尺寸,增加了模型的尺寸,减慢了训练。
2.2肾脏数据库处理
一旦收集到20倍放大的WSIs,它们被分割成20个2000x2000像素的patch,只选择那些包含组织的patch。这组切片被检查并标记为三类(见图2):
(i)非肾小球结构:肾组织结构,如近端和远端小管、血管、结缔组织间质或炎症细胞;
(ii)正常肾小球,特点是肾小球毛细血管袢薄,有一定数量的内皮细胞和系膜细胞。
iii)硬化性肾小球:整个(或几乎整个)肾小球出现硬化。
经过以上步骤,最终得到了1055张肾脏组织图像的数据集。对肾小球轮廓图进行标注,为每幅图像生成一个掩模。1245个肾小球结构被注释,其中303个为硬化肾小球,其余942个为正常肾小球。CNN架构通常需要大量的图像数据集来获得有价值的结果。为此,采用了数据扩充的方法来增加样本的数量。颜色不清晰化是数字化病理中最常用的数据增强方法之一。虽然免疫组化过程使用相同的染色标记物,但组织中可能出现一些颜色变化。它主要依赖于商业提供商,但它直接影响到图像分析。颜色归一化方法通过在图像之间进行颜色转移来克服这个问题。颜色归一化采用Reinhard’s method (RM)[20]。为了支持这一决定,我们将重点放在[4]中进行的研究,其中使用了四种不同的颜色标准化方法:his- togram matching (HM)[26]、Macenko’s method (MM)[15]、RM和非线性样条映射方法(SM)[12]。颜色转移应用于5个不同的参考,因此将数据集扩展到5275张图像。另一种广泛用于数据增强的技术是在图像上计算较小的仿射变换,如翻转、镜像、平移和旋转。因此,与RM一起,旋转90◦和270◦,以及垂直翻转进行。最后,考虑到这些图像变换,该数据集由25,320张图像组成。
图3:
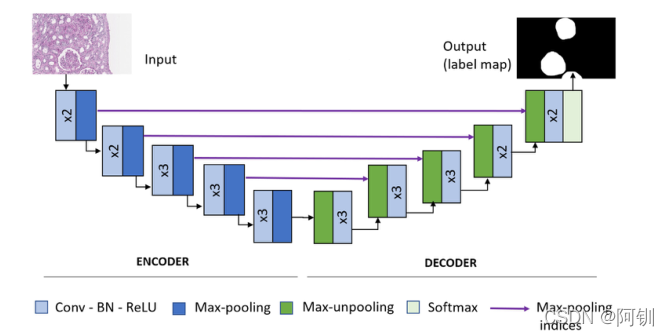
图3所示。SegNet-VGG16架构。编解码器网络由26个卷积层组成,其中编码器层13个,解码器层13个。解码器输入依赖于编码器的池索引。
3.方法
语义切分是最近才出现的一种深度学习方法。这种分割也称为密集预测,其主要特征是对图像中的像素标签进行分类,而不是对图像中的物体进行分类。为此目的,对输入标签图像执行一次热编码,为每个类[7]创建一个独特的图像。语义分割的原生表示使用卷积层(通过网络层保持相同的填充和相同的大小)生成,并以分割图作为输出。众所周知,CNN的第一层学习输入图像的低级特征,而最后一层学习高级概念。因此,许多cnn执行下采样操作,如池化和大步卷积,以减少计算工作量。然而,语义分割的最终目标是生成与输入图像以某种方式相关的全分辨率标记图像。因此,语义分割过程通常被认为是一种编码器-解码器的方法,其中编码器学习通过执行下采样操作来区分类,解码器负责通过上采样操作来反转这一过程,最终获得一个全分辨率分割图。根据所选择的策略,下采样和上采样操作应用不同的方法。
本文重点研究了两种不同的语义分割方法,这取决于所选择的CNN来构建内部网络结构。一方面,利用SegNet (VGG16和VGG19)的结构[1](也称为SegNet -VGG16和SegNet -VGG19)构建了一种编解码方法。另一方面,我们在使用U-Net架构[23]时,分别使用了4个(按照最初的U-Net实现)和5个编码器。在本作品中,它们被称为U-Net和U-Net-5,以区分它们的设计。下面提供了对这两个体系结构的简要描述。
编解码器SegNet架构[1]:
•5卷积块编码器输入层由几个3 x3卷积层,批量标准化层,ReLU层和2 x2 max-pooling层(步幅= 2)。
•5卷积块译码器组成的max-unpooling层和几个3 x3卷积层,批也没有malization层和ReLU层。
•Softmax层计算像素级分类分数
•输出层预测像素图
SegNet- vgg16和SegNet- VGG19的主要区别在于每个卷积块的卷积层数。基于SegNet-VGG16的卷积块根据块的深度由两层或三层卷积层组成,而SegNet-VGG19的卷积块由两层或四层卷积层组成。图3显示了基于VGG16网络的SegNet架构。
编解码器U-Net架构[23]:
输入层
•编码器4个卷积块,包括两个3x3卷积层、ReLU层、2x2 max-pooling层(stride = 2)和两个dropout层,以防止过拟合。
•4个卷积块用于解码器,包括上卷积(转置卷积)层、upReLU层和深度串联层,然后是两个3x3卷积层和ReLU层。
•1x1卷积层映射提取的64个特征图
•Softmax层计算像素级分类分数•输出层与预测像素图
U-Net-5具有与U-Net相同的结构,在编码器和解码器中都增加了一个卷积块。图4说明了原始的(4个编码器)U-Net架构。两种架构(SegNet和U- Net)的主要区别在于解码器上采样操作。SegNet应用了2x2 max-unpooling操作,其中每个最大激活值的前一个对应的max-unpooling索引被用来执行max-unpooling[29]。在U-Net体系结构中,解码器的特征是一个上卷积层,也称为转置卷积、分步卷积或反卷积。这一层使用之前的卷积核来进行卷积的逆运算。它后面是一个upReLU层和一个深度连接层,导致连接的特征图。由于这些类型的网络执行像素级分类,它们相对于其他网络有很大的优势。
3.1 语义分割肾小球病变检测:SegNet vs U-Net
如前所述,应用SegNet和U-Net架构对非肾小球结构、正常肾小球和硬化肾小球(三类)进行像素级分割。该方法遵循的工作流程如图5所示。放大20倍的图像被调整为400x400像素,以调整图像大小,减少网络计算而不损失精度。这种重采样是应用双三次插值和执行抗锯齿。75%的图像块用于训练。因此,总共训练18990幅图像,生成逐像素分割模型。SegNet的训练采用动量为0.9的随机梯度下降优化算法来加速梯度向量,L2正则化方法的值为1 e−4,初始学习率分别为0.1和0.05。步进衰减计划使学习速率每2个时代以0.1的倍数下降。使用4和2 epoch的小批处理大小共生成9801个训练迭代。对于U-Net方法,使用与Seg- Net方法相同的值建立网络参数。唯一的区别是被选择的时代的数量增加到4个。培训总共涉及19602个迭代。在这两种方法中,我们采用了一种迁移学习策略,使用了从ImageNet数据库[24]中预先训练的模型。
图4、图5:
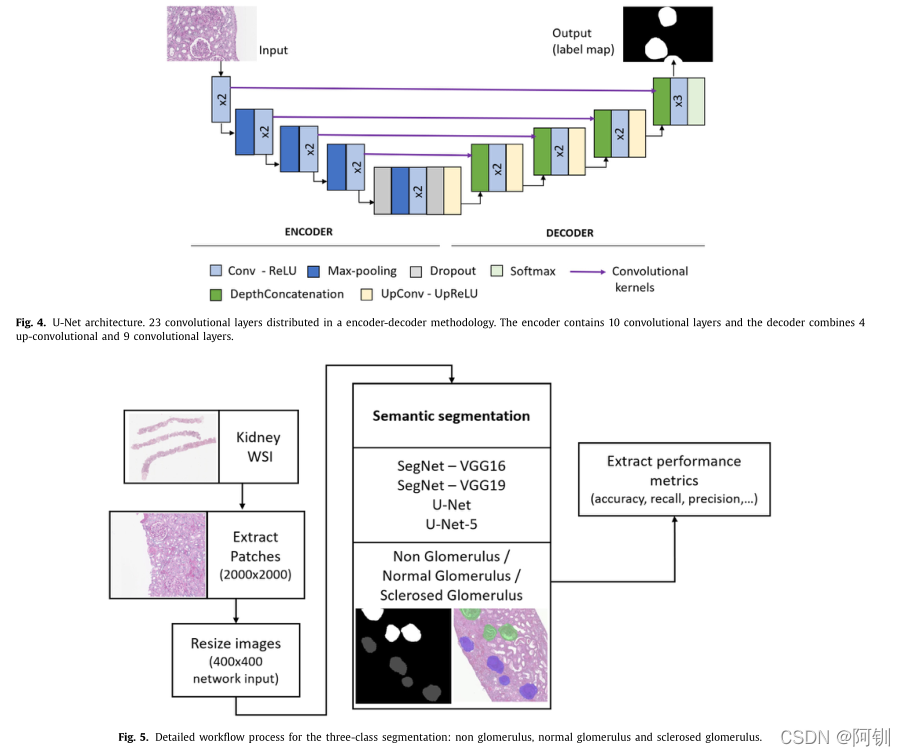
3.2 连续的CNNs分割和分类
这种方法提出使用连续的cnn进行分割和分类。因此,首先使用语义分割网络只检测肾小球结构(两类),然后使用获得的真正阳性的肾小球结构训练AlexNet网络[13],以便将它们分类为正常或硬化的肾小球。AlexNet是一个著名的CNN架构,已经被用于几个分类任务,并因其具有竞争力的准确性/计算时间比率而被选中。该体系结构主要包括3个卷积块,然后是全连接层,最后是软最大层,如图6所示。卷积块由卷积层、ReLU层和归一化层组成,然后是最大池化下采样层。此外,在一些完全连接的层之后,一个dropout层被应用,以关闭随机单位。softmax层返回预测分数,这些分数最终被识别为输出层中的预测类。SegNet和U-Net方法用于语义分割。第一步获得的最佳模型,在本例中,由SegNet-19获得的模型,用于训练AlexNet网络。图7显示了这种方法所遵循的检测和分类肾小球结构的方法。
因此,评估方法的目标是达到打赌- ter准确性:
a)语义分割为正常和硬化的肾小球或
b)的连续CNN执行segmenta,到non-glomerular和肾小球结构遵循一个AlexNet网络对肾小球硬化或正常的肾小球结构进行分类。
对于肾小球分割,除了SegNet epoch外,我们使用了与三级分割相同的参数,SegNet epoch以3为值递增,共产生1470 0个训练迭代。在AlexNet训练的情况下,我们使用了动量为0.9的随机梯度下降优化算法,L2正则化方法的值为1 e−4,初始学习速率为1 e−5。和以前的网络一样,步进衰减计划每2个时代使学习速率降低0.1倍。我们选择了40和60个epoch的小批量大小,总共有3120个迭代。使用2340张肾小球图像数据集来训练网络。
3.3验证指标
作出诊断时,适当的解释是必要的。在一个检测过程中,有两个可能的结果,阳性和阴性。然而,一些错误导致正的情况可能被归类为负的,反之亦然。这些情况通常分别称为假阳性和假阴性。因此,必须考虑真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)这四个可能的结果进行解释。基于这些值,表3中显示的性能指标已经计算出来。
4.结果
4.1 语义分词的性能
应用SegNet和U-Net方法进行语义分割,将肾脏组织分为非肾小球结构、正常肾小球和硬化肾小球(三类)。使用25%的原始数据集完成测试,共取6330个图像块进行像素预测。表4显示了得到的结果。总结、SegNet和U-Net cnn在肾WSI肾小球病变的分割和检测中具有重要的价值。在指标方面,全球准确度在92%以上,这表明该CNN在WSI中检测肾小球的适宜性。
表3、表4 :
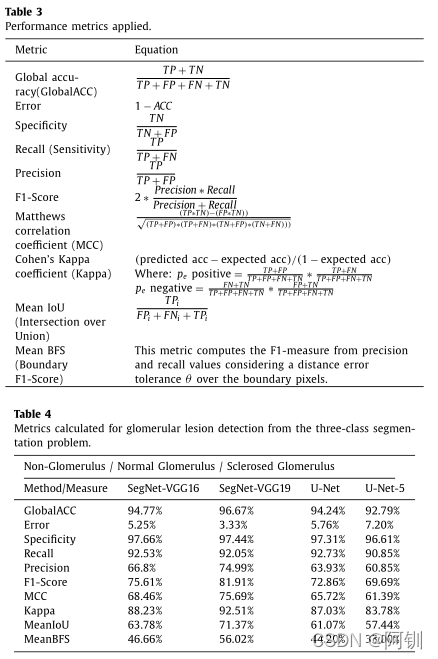
表5、表6:
然而,准确率下降,表明当区分正常和硬化肾小球时,假阳性病例增加。对其他区域指标如MeanIoU和MeanBFS进行了分析,结果不尽如人意。MeanIoU表示预测区域和预期区域之间的重叠,低值表示分割过度或不足。MeanBFS测量的是预测区域和预期区域的边界匹配,等高线的差异导致数值降低。对这些结果的可能解释将在稍后的手稿中提供。着重于分类的准确性(见表5),该方法获得了有价值的结果,非肾小球结构和正常肾小球的准确率约为94%和96%,硬化肾小球的准确率超过83%。根据结果,SegNet方法似乎利用了非肾小球和正常肾小球的分类和原始的U-Net版本的硬化肾小球分类。
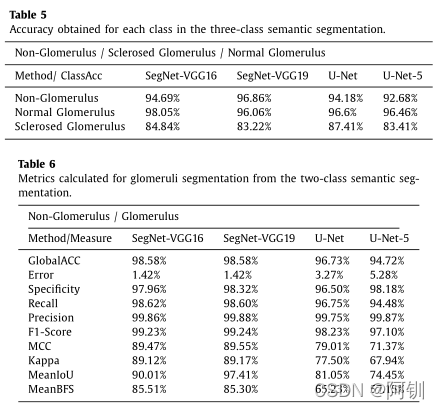
图八对采用重叠分割结果的方法对原始WSI块的分割结果进行了可视化分析。图8还对不同方法分割的相同WSI patch进行了比较。图示:紫色为硬化肾小球,绿色为正常肾小球。U-Net方法显示了一些两个肾小球类别都被打乱的病例,如上一个样本所示。数据特征和检测过程会导致检测结果存在一定的误差,可以直观地识别出来。分割结果显示了四个主要的错误:
i位于肾小球边界外区域的假阳性和假阴性像素。这些情况存在于所有的网络中。虽然这种情况被认为是一个像素分类错误,但它主要来自于标记过程。这就是平均BFS值低的原因,因为这个误差直接影响到这个测量。
ii肾脏组织结构与肾小球混淆。一些结构由于与肾小球结构相似而被错误分类。
iii部分局灶节段性肾小球硬化病例分为正常和硬化两种类型。U-Net方法产生的假阳性像素。U-Net方法也造成假阳性分布在整个图像,特别是与非肾小球区域相关的假阳性。
除了第一个问题,这些错误都是偶尔被检测到的,它们不会显著地影响整体性能。然而,为了调整语义分割训练的参数,需要进行分析。图9显示了每种方法错误的一个例子,其中洋红色、绿色、白色和黑色代表假阳性、假阴性、真阳性(正常和硬化肾小球)和真阴性(非肾小球结构)。
图8:

图9、图10:
4.2连续cnn性能
在顺序分割和分类过程中,首先将语义分割应用于肾小球分割。与三类方法一样,使用6534个图像块进行测试。表6显示了用Seg- Net和U-Net方法得到的结果。所有方法的平均准确率都在94%以上,SegNet体系结构的准确率达到了98.58%。SegNet-VGG19的特异性、精度和平均IoU的提高表明了相对于SegNet-VGG16更好的分割。
对于每类的准确率,如表7所示,当非肾小球和肾小球结构的分割值分别大于94%和96%时,得到了肾小球分割的相关百分比。SegNet-VGG19获得了每个类的最佳分割精度,两个类的值都大于98%。
表7:
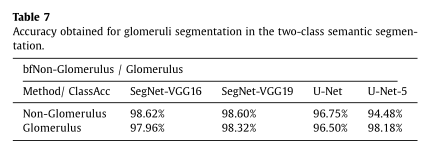
表8:
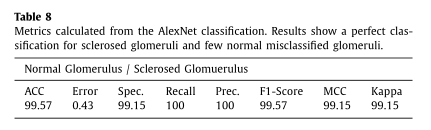
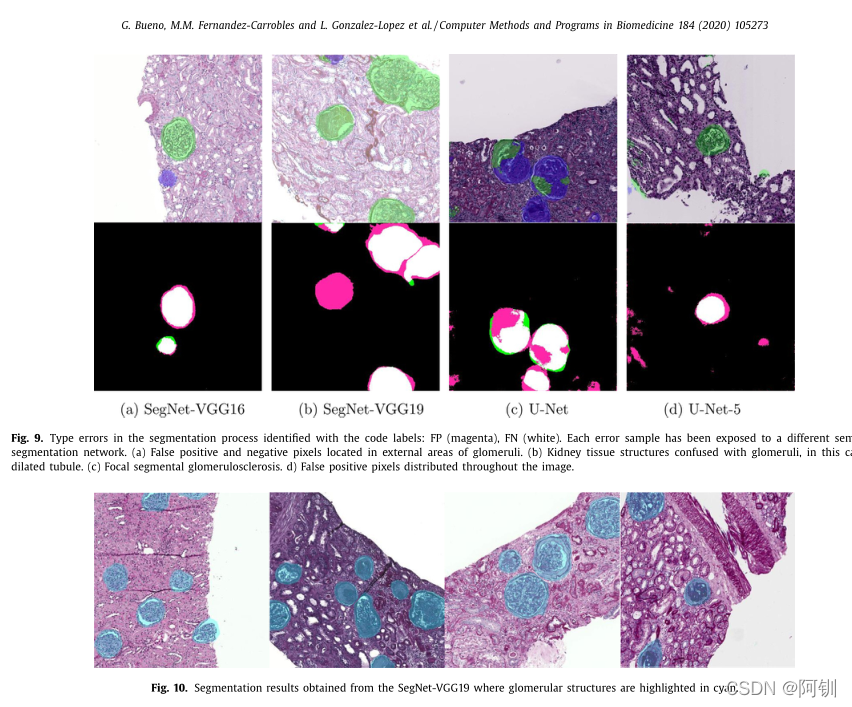
图10显示得到的分割结果,其中肾小球以青色突出显示。一旦使用SegNet-VGG19进行语义分割,检测到非肾小球和肾小球结构,真正的阳性区域就被划分为硬化的或正常的肾小球。为此目的采用AlexNet网络,达到了99.57%的正确率,显著改善了肾小球的分类过程。表8显示了使用对结果提取的混淆矩阵计算的度量。序列分割和分类的平均正确率为98.16%,语义分割的正确率为98.58%,AlexNet分类的正确率为99.57%。这一结果改进了之前使用三类分割得到的结果。
5.结论
本文提出了一种方法,以执行肾小球硬化检测手段的语义切分。之前的几项研究已经将深度学习方法应用于肾小球检测,但据作者所知,没有一项研究将重点放在语义分割技术上,更具体地说,是SegNet网络,这使得本文在这一领域做出了新的贡献。本研究比较了三类和两类问题的不同定义方法。四种不同的CNN网络被考虑建立SegNet和U-Net方法,即SegNet- vgg16, SegNet- vgg19, U-Net和U-Net-5。使用连续的cnn进行分割和分类获得了最好的结果。因此,我们首先使用SegNet-VGG19来检测非肾小球的肾小球结构,然后使用AlexNet进行分类,以区分正常或硬化的肾小球结构。两类分割的结果是98.16%,而三类分割问题的SegNet-VGG19的结果是96.67%。这主要是因为AlexNet分类法之前对肾小球结构进行了分割,减少了正常肾小球和硬化肾小球之间的预测混淆。因此,我们发现顺序的CNN分割分类策略- egy需要一个相关的解决方案来检测肾小球硬化,并区分整体硬化性肾小球和正常肾小球。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









