







"""
机器学习领域中的降维指在某些限定条件下,降低随机变量个数,得到一组相关性不强的
主变量的过程。降维采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中,
在原始的高维空间中,包含有冗余信息以及噪音信息,将会降低模型的识别精度,机器
学习算法的复杂度和数据的维数有着密切关系,甚至与维数呈指数级关联,通过降维能
在一定程度上减少冗余信息,从而提高模型的识别精度,提高模型的运行效率,且高维
数据无法通过作图可视化,降维后可通过图形可视化寻找数据内部的结构特征
降维可分为特征选择和特征提取两种方法。特征选择嘉定数据中包含大量冗余或无关变量
(又称特征、属性、指标),旨在从原有变量中找出主要变量,特征提取是将高维数据转化
为低维数据过程。在此过程中可能舍弃原有数据、创造新的变量
"""
#PCA
#特征提取的一个典型代表方法为主成分分析,PCA基于特征之间的关系识别出数据内在模式
#通过计算协方差矩阵的特征值和相应的特征向量,在高维数据中找到最大方差的方向,并将
#数据映射到一个维度不大于原始数据的新的子空间上
#导入iris数据集,该数据集包含4个特征、150条记录,标签分为3类
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
print('iris数据集前10行为:\n',x[:10])
print('iris数据集的维度为:',x.shape)

#通过三种方式构建并训练模型
from sklearn.decomposition import PCA
#指定保留的特征为3
pca = PCA(n_components =3).fit(x)
print('指定特征数的PCA模型为:\n',pca)

#指定降维后保留的方差百分比0.95
pcal = PCA(n_components = 0.95).fit(x)
print('指定方差百分比的PCA模型为:\n',pcal)

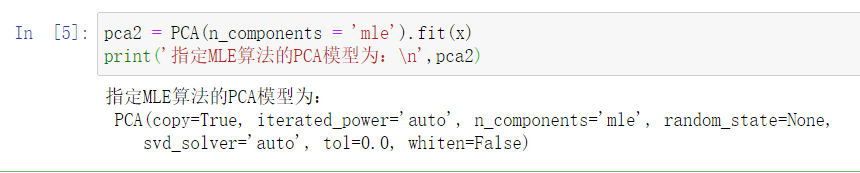
#指定使用MLE最大似然算法自动降维
pca2 = PCA(n_components = 'mle').fit(x)
print('指定MLE算法的PCA模型为:\n',pca2)
#查看特征方差和方差占比
#查看模型训练后各项特征的方差
print('各项特征的方差为:',pca.explained_variance_)

#查看降维后的特征占所有特征的方差百分比
print('降维后的特征的方差占比为:',pca.explained_variance_ratio_)

#使用fit_transform方法输出降维后的结果
#查看指定特征数的结果
x_pca = pca.transform(x)
print('指定特征数的降维结果前10行数据为:\n',x_pca[:10])

#查看指定方差百分比的降维结果
x_pcal = pcal.transform(x)
print('指定方差百分比的降维结果前10行数据为:\n',x_pcal[:10])

#查看MLE算法降维结果
x_pca2 = pca2.transform(x)
print('MLE算法的降维结果前10行数据为:\n',x_pca2[:10])

#随机投影
"""
随机投影可使得数据在投影后的数据点之间的距离信息变化不大,前提为需要将维度
降到一个合适的范围内,但并非所有的样本都适合使用随机投影进行降维,对于部分
非均匀分布的高维数据,使用随机投影后会使得样本混杂在一起
高斯随机投影:高斯分布产生的每个投射点的概率都一样,即均匀分布,对于低维度
高斯来说,其概率质量主要集中在均值附近,在高维情况下也同样成立
通常使用高斯随机投影降维需要保证欧几里得空间距离的离散容忍度即eps参数至少为0.1
以上,
"""
#使用GaussianRandomProjection
构建并训练模型
from sklearn import datasets
from sklearn.random_projection import GaussianRandomProjection
#加载iris数据集
iris = datasets.load_iris()
x = iris.data
print('iris数据集前10行:\n',x[:10])

#构建并训练模型
grp = GaussianRandomProjection(n_components = 3).fit(x)
print('高斯随机投影:',grp)

#查看降维维度和高斯随机投影矩阵
#查看模型选择的降维维度
print('降维维度:',grp.n_components_)

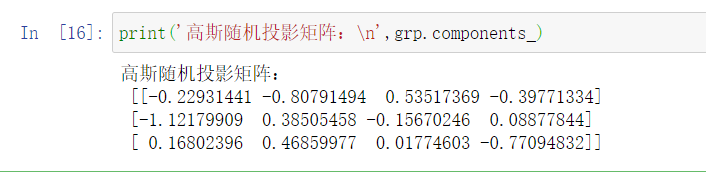
#查看模型使用的高斯随机投影矩阵
print('高斯随机投影矩阵:\n',grp.components_)
#调用模型对生成的数据进行降维
trans_x = grp.transform(x)
print('降维后的数据前10行为:\n',trans_x[:10])

#稀疏随机矩阵
"""
另一种随机投影的降维方法为稀疏随机矩阵,通过投影原始输入空间来降低维度,稀疏矩阵可以
代替高斯随机投影矩阵来保证相似的嵌入质量,且内存利用率更高,投影数据的计算更快
"""
#使用SparesRandomProjection函数构建并训练模型
from sklearn import datasets
from sklearn.random_projection import SparseRandomProjection
#加载iris数据集
iris = datasets.load_iris()
x = iris.data
print('iris数据集前10行:\n',x[:10])

#构建并训练模型
srp = SparseRandomProjection(n_components = 2).fit(x)
print('稀疏随机矩阵:\n',srp)

















 3203
3203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









