






智能计算系统深度学习处理器设计实验
一、串行内积运算器
1、代码补全
乘法器需计算神经元与权重乘积。
wire signed [31:0] mult_res = neuron * weight;
加法器对暂存结果与刚刚完成运算的乘法结果进行累加。
wire [31:0] psum_d = psum_r + mult_res;
对输出信号置高电平需满足已经完成最后一个输入数据的运算,此时 ctl[1]为 1。
else if(ctl[1]) begin
vld_o <= 1'b1;
end
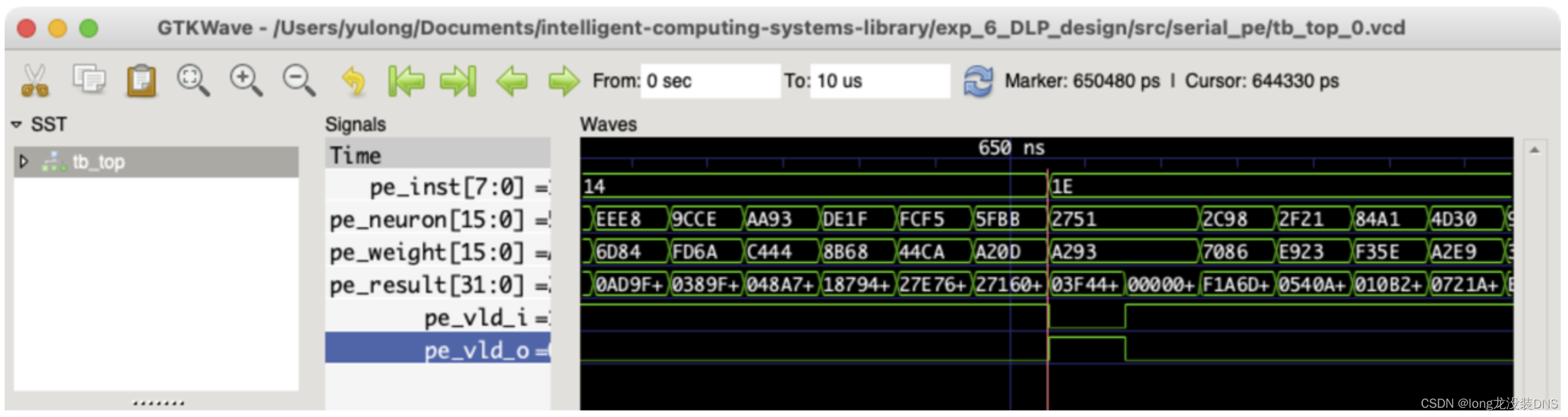
2、波形图
二、并行内积运算器
1、乘法器pe_mult.v 代码补全
并行运算器输入端为 512 位,即存储了 32 个神经元数值,故对每一次参数处理要进行 32 次运算,并得出 32 个乘法运算结果。
for(i=0; i<32; i=i+1)
begin:int16_mult /* TODO */
assign int16_neuron[i] = mult_neuron[(i*16+15):(i*16)];
assign int16_weight[i] = mult_weight[(i*16+15):(i*16)];
assign int16_mult_result[i] = int16_neuron[i] * int16_weight[i];
end
在完成并行运算后,需要将 32 个结果拼接传入到加法器中。
assign mult_result = {int16_mult_result[31],int16_mult_result[30], ... ,int16_mult_res ult[0]};
2、加法器pe_acc.v 代码补全
加法器将乘法器的拼接结果拆开并进行加法运算,运算方式是每两个数进行相加,逐次减半,最终加至一个数。由于乘法器共输入 32 个乘法结果,故第一次加法运算结束后为 16 个结果,以此类推。
for(j=0; j<(32/(2**i)); j=j+1)
begin:int16_adder
if(i==0) begin /* TODO */
assign int16_result[0][j] = mult_result[(j*32+31):(j*32)];
end else begin /* TODO */
assign int16_result[i][j] = int16_result[i-1][j*2] + int16_result[i-1][j*2+1];
end
end
程序主入口对与串行运算器方法相同
3、波形图

三、矩阵运算单元
1、代码补全
对输入规模的存储,复位时至 0,处理器运行时将规模输入参数与信号进行存储。
/* TODO: inst_vld & inst */
if (!rst_n) begin
inst_vld <= 0;
inst <= 0;
end else begin
inst_vld <= ib_ctl_uop_valid;
inst <= ib_ctl_uop;
end
对迭代器设置。迭代器负责对并行运算器进行参数更新,在正常运算(pe_vld_i 置 1) 的情况下迭代器进行迭代,当运算完成(pe_ctl[1]置 1)时,迭代器复位。
/* TODO: iter */
if(!rst_n) begin
iter <= 8'b0;
end else if(pe_ctl[1]) begin
iter <= 8'b0;
end else if(pe_vld_i) begin
iter <= iter + 1'b1;
end
在此处对 pe_vld_i 进行调整,除了输入的神经元数据、权值数据和控制信号都有效外,
保证运算完成控制信号 ib_ctl_uop_ready 置 1(单元要向外层单元传递运算结果)时单元停
止运算。
wire pe_vld_i = ib_ctl_uop_valid && wram_mpe_weight_valid && nram_mpe_neuron_valid && !ib_ctl_uop_ready;
对运算完成控制信号处理,当运算完成(pe_ctl[1]置 1)时将控制信号置 1,使上层单元获取运算结果,并将神经元和权值控制信号置 1,此刻不再接收新的数据。
if (!rst_n) begin
ib_ctl_uop_ready <= 0;
end else if (pe_ctl[1]) begin
ib_ctl_uop_ready <= 1;
end else begin
ib_ctl_uop_ready <= 0;
end
assign nram_mpe_neuron_ready = ib_ctl_uop_ready; assign wram_mpe_weight_ready = ib_ctl_uop_ready;
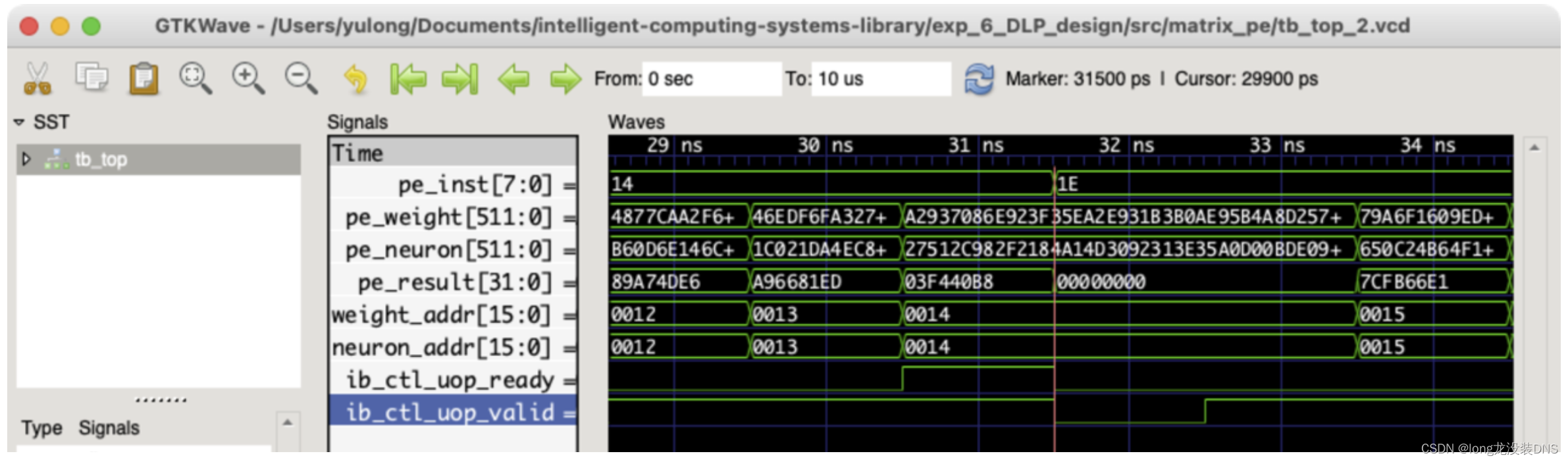
2、波形图















 1435
1435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









