







Java多线程和并发
多进程
多进程概念
当前的操作系统都是多任务OS
每个独立执行的任务就是一个进程
OS将时间划分为多个时间片
每个时间片内将CPU分配给某一个任务,时间片结束,CPU将自动回收,再分配给另外任务。
从外部看,所有任务是同时在执行。但是在CPU上,任务是按照串行依次运行(单核CPU)。
如果是多核,多个进程任务可以并行。但是单个核上,多进程只能串行执行。
多进程优点
可以同时运行多个任务
程序因IO堵塞时,可以释放CPU,让CPU为其他程序服务
当系统有多个CPU时,可以为多个程序同时服务
我们的cpu不再提高频率,而是提高核数
2005年Herb Sutter的文章The free lunch is over,指明多核和并行程序才是提高程序性能的唯一办法
多进程缺点
笨重,不好管理,不好切换
多线程
一个程序可以包括多个子任务,可串/并行
每个子任务可以称为一个线程
如果一个子任务阻塞,程序可以将CPU调度另外一个子任务进行工作。这样CPU还是保留在本程序中,
而不是被调度到别的程序中去。这样提高本程序所获得CPU时间和利用率
多进程和多线程对比
线程共享数据
线程通讯更搞笑
线程更轻量级,更容易切换
多个线程更容易管理
多进程执行:启动多个Java.exe
多线程执行:只启动一个Java.exe
Java多线程创建
1.java.lang.Thread
-线程继承Thread类,实现run方法
public class Thread1 extends Thread{
public void run(){
System.out.println("hello");
}
}
2.java.lang.Runnable接口
-线程实现Runnable接口,实现run方法
public class Thread2 implements Runnable{
public void run(){
System.out.println("hello");
}
}
Java多线程启动
start方法,会自动以新进程调用run方法
直接调用run方法,将变成串行执行
同一个线程,多次start会报错,只执行第一次start方法
多个线程启动,其启动的先后顺序是随机的
线程无需关闭,只需要run方法执行结束后,自动关闭
main函数可能早于新线程结束,但整个程序并不终止
整个程序终止时等所有的线程都终止(包括主线程)
多线程实现对比
Thread vs Runnable
Thread占据了父类的名额,不如Runnable方便
Thread类实现Runnable
Runnable启动时需要Thread类的支持
Runnable更容易实现多线程中资源共享
多线程信息共享
线程类
通过集成Thread或实现RUnnable
通过start方法,调用run方法,run方法工作
线程run结束后,线程退出
通过共享变量在多个线程中共享消息
static 变量
class TestThread0 extends Thread{
//private int tickets = 100; //每个线程卖100张票,没有共享
private static int tickets = 100; //static变量是共享的,所有线程共享
public void run(){
while(true){
if(tickets>0){
System.out.println(Thread.currentThread().getName()+" is selling ticket "+ tickets);
tickets = tickets -1;
}else{
break;
}
}
}
}
同一个Runnable类的成员变量
public class ThreadDemo1{
public static void main(String[] args){
TestThread1 t = new TestThread1();
new Thread(t).start();
new Thread(t).start();
new Thread(t).start();
new Thread(t).start();
}
}
多线程信息共享问题
工作缓存副本
关键步骤缺乏加锁限制
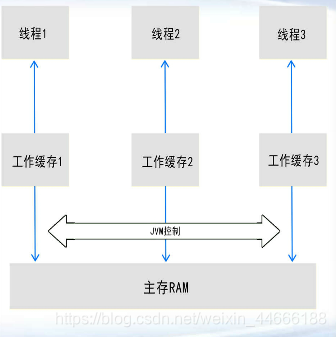
i++并非原子性操作
步骤:
读取主存i(正本)到工作缓存(副本)中
每个CPU执行(副本)i+1操作
CPU将结果写入到缓存(副本)中
数据从工作缓存(副本)刷到主存(正本)中
变量副本问题的解决方法
采用volatile关键字修饰变量
保证不同线程对共享变量操作时的可见性
class TestThread2 extends Thread{
volatile boolean flag = true;//用volatile修饰的变量可以及时在各线程里面通知
public void run(){
int i = 0;
while(flag){
i++;
}
System.out.println("test thread3 is exiting");
}
}
关键步骤加锁限制
互斥:某一个线程运行一个代码段(关键区),其他线程不能同时运行这个代码段
同步:多个线程的运行,必须按照某一种规定的先后顺序来运行
互斥是同步的一种特例
互斥的关键字是synchronized
synchronized代码块/函数,只能一个线程进入
synchronized加大性能负担,但是使用简便
多线程管理
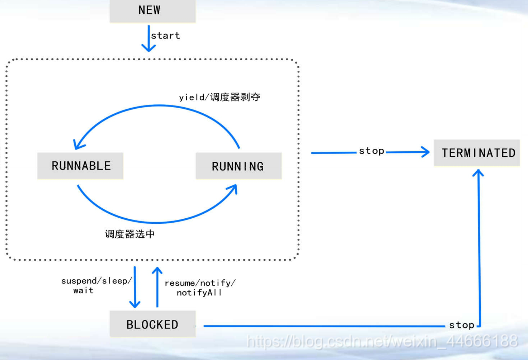
线程状态
NEW 刚创建(new)
RUNNABLE 就绪态(start)
RUNNING 运行中(run)
BLOCK 阻塞(sleep)
TERMINATED结束
Thread的部分API已经废弃
暂停和恢复 suspend/resume
消亡 stop/destroy
线程阻塞和唤醒
sleep()
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
sleep()是Thread类的静态方法,让调用的线程进入指定时间的睡眠状态,使得当前线程进入阻塞状态,系统在指定的时间段内不会为改线程分配执行时间片。需要注意的是如果线程处于上锁状态,sleep()方法不会释放对象锁,也就是说在睡眠时间内依然占用同步资源锁。sleep()时间到了的时候不代表会线程会立即运行,还是需要等待CPU分配时间片,CPU可能依旧被其他线程占用。sleep()使用的时候必须进行异常捕获。
wait()
wait()方法属于Object类,当一个线程执行wait()方法时,它就进入到一个和该对象相关的等待池中(进入等待队列,也就是阻塞的一种,叫等待阻塞),同时释放对象锁,并让出CPU资源,待指定时间结束后返还得到对象锁。
notify()/notifyAll()
notify()/notifyAll()同样属于Object类
该方法也要在同步方法或同步块中调用,即在调用前,线程也必须要获得该对象的对象级别锁,的如果调用 notify()时没有持有适当的锁,也会抛出 IllegalMonitorStateException。
该方法与 notify ()方法的工作方式相同,重要的一点差异是:
notifyAll 使所有原来在该对象上 wait 的线程统统退出 wait 的状态(即全部被唤醒,不再等待 notify 或 notifyAll,但由于此时还没有获取到该对象锁,因此还不能继续往下执行),变成等待获取该对象上的锁,一旦该对象锁被释放(notifyAll 线程退出调用了 notifyAll 的 synchronized 代码块的时候),他们就会去竞争。如果其中一个线程获得了该对象锁,它就会继续往下执行,在它退出 synchronized 代码块,释放锁后,其他的已经被唤醒的线程将会继续竞争获取该锁,一直进行下去,直到所有被唤醒的线程都执行完毕。
join()
join()方法使调用该方法的线程在此之前执行完毕,也就是等待该方法的线程执行完毕后再往下继续执行。注意该方法也需要捕捉异常。
yield()
该方法与sleep()类似,都是可以让当前正在运行的线程暂停,区别在于yield()方法不会阻塞该线程,它只是将线程转换成就绪状态,让系统的调度器重新调度一次,并且yield()方法只能让优先级相同或许更高的线程有执行的机会。
interrupt()
在一个线程中调用另一个线程的interrupt()方法,即会向那个线程发出信号——线程中断状态已被设置。至于那个线程何去何从,由具体的代码实现决定。
向另外一个线程发送中断信号,该线程接收到信号,会触发InterruptedException(可解除阻塞),并进行下一步处理
线程被动地暂停和终止
依靠别的线程来拯救自己
没有及时释放资源
class TestThread1 extends Thread{
public void run(){
while(!interrupted()){
//判断标志,当本线程被别人interrupt后,JVM会被本线程设置interrupted标记
System.out.println("test thread1 is running");
try{
Thread.sleep(1000);
}catch(InterruptedException e){
e.printStackTrace();
break;
}
}
System.out.println("test thread is exiting");
}
}
线程主动暂停和终止
定期检测共享变量
如果需要暂停或者终止,先释放资源,再主动动作
暂停:Thread.sleep(),休眠
终止:run方法结束,线程终止
class TestThread2 extends Thread {
public volatile boolean flag = true;
public void run(){
while(flag){
System.out.println("test thread2 is running");
try{
Thread.sleep(1000);
}catch(InterruptedException){
e.printStackTrace();
}
}
System.out.println("test thread2 is exiting");
}
}
多线程死锁
每个线程互相持有别人需要的锁
预防死锁,对资源进行等级排序
举例:
private static Integer r1 = 1;
private static Integer r2 = 2;
new Thread(new Runnable() {
@Override
public void run() {
synchronized (r1){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (r2){
Log.d("main","thread1 is running");
}
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
synchronized (r2){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (r1){
Log.d("main","thread2 is running");
}
}
}
}).start();
如代码所示,Thread1和Thread2各自持有r1,r2两个对象锁,又在等待对方释放锁,产生了死锁问题。
守护(后台)线程
是指在程序运行的时候在后台提供一种通用服务的线程。如gc。
其实守护线程和用户线程区别不大,可以理解为特殊的用户线程。特殊就特殊在如果程序中所有的用户线程都退出了,那么所有的守护线程就都会被杀死,很好理解,没有被守护的对象了,也不需要守护线程了。启动守护线程也有两种方法,先来看看怎么启动守护线程 。
普通线程的结束,是run方法运行结束
守护线程的结束,是run方法运行结束或者main函数结束
守护线程永远不要访问资源,如文件或者数据库
最常用的一种是通过将用户线程转换为守护线程来启动线程从而启动守护线程。
thread.setDaemon(true);
这样可以设置该线程为守护线程,值得注意的是必须在线程启动start()方法之前设置。
线程池
Executor
从JDK1.5开始提供Executor FrameWork
分离任务的创建和执行者的创建
线程重复利用(new 线程代价很大)
预设好多个Thread,可弹性增加
多次执行很多很小的任务
任务创建和执行过程解耦
程序员无需关心线程池执行任务过程
线程池创建
Executors的创建线程池的方法,创建出来的线程池都实现了ExecutorService接口。常用方法有以下几个:
newCachedThreadPool创建一个可缓存线程池程
创建一个可缓存的线程池,调用execute 将重用以前构造的线程(如果线程可用)。如果没有可用的线程,则创建一个新线程并添加到池中。终止并从缓存中移除那些已有 60 秒钟未被使用的线程。
newFixedThreadPool 创建一个定长线程池
创建固定数目线程的线程池。
newScheduledThreadPool 创建一个定长线程池
创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类。
newSingleThreadExecutor 创建一个单线程化的线程池
创建一个单线程化的Executor。
ExecutorService executor = Executors.newFixedThreadPool(nThreads) ;
但是以上创建线程池的方法并不推荐=。=
阿里巴巴Java开发手册中提到使用Executor创建线程池可能会导致OOM问题
有兴趣可以看这篇blog
推荐直接调用ThreadPoolExecutor的构造函数来自己创建线程池
private static ExecutorService executor = new ThreadPoolExecutor(10, 10,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue(10));
从上面的代码中可以确定,我们需要传的参数有corePoolSize、maximumPoolSize、keepAliveTime、unit、workQueue
下面对这几个参数进行说明
corePoolSize:线程池的核心线程数;
maximumPoolSize:线程池的最大线程数;
keepAliveTime:线程池空闲时线程的存活时长;
unit:线程存活时长大单位,结合上个参数使用;
workQueue:存放任务的队列,使用的是阻塞队列;
在这个方法中调用了另外的一个构造方法,即上图中四个构造方法中的第四个,从源码中得知,一个线程池包含的属性共有corePoolSize、maximumPoolSize、keepAliveTime、unit、workQueue、threadFactory、handler七个,上面说到了五个,下面是其他两个的含义,
threadFactory:线程池创建线程的工厂;
handler:在队列(workQueue)和线程池达到最大线程数(maximumPoolSize)均满时仍有任务的情况下的处理方式;
上面的七个参数,也即ThreadPoolExecutor的第四个构造方法需要的参数。
我们再来看中间的两个构造方法,和第一个的区别在于,第二个和第三个指定了创建线程的工厂和线程池满时的处理策略。
通过上面的方式便创建了线程池
不带返回值例子:
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class MyServer {
private ThreadPoolExecutor executor;
public MyServer() {
executor = new ThreadPoolExecutor(100,100,100L, TimeUnit.SECONDS,new ArrayBlockingQueue<Runnable>(10));
}
public void submitTask(Task task){
System.out.printf("Server : A new Task has arrived\n");
executor.execute(task);
System.out.printf("Server : Pool Size : %d\n",executor.getPoolSize());
System.out.printf("Server : Active count :%d\n",executor.getActiveCount());
System.out.printf("Server : Complete Tasks :%d\n ",executor.getCompletedTaskCount());
}
public void endServer(){
executor.shutdown();
}
}
public class Task implements Runnable{
private String name;
public Task(String name) {
this.name = name;
}
@Override
public void run() {
Long duration = (long)(Math.random()*1000);
System.out.printf("%s :Task %s :Doing a task during %d seconds\n",Thread.currentThread().getName(),name,duration);
try {
Thread.sleep(duration);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.printf("Task Finished\n");
}
}
MyServer server = new MyServer();
for (int i = 0;i<100;i++){
Task task = new Task("Task"+i);
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
server.submitTask(task);
}
server.endServer();
带计算返回值的例子
import android.util.Log;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class SumTest {
private ThreadPoolExecutor executor;
public SumTest() {
executor = new ThreadPoolExecutor(4, 4, 0L, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(10));
List<Future<Integer>> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
SumTask calculator = new SumTask(i*100+1,(i+1)*100);
Future<Integer> result = executor.submit(calculator);
list.add(result);
}
do {
System.out.printf("Main:已经完成多少个任务:%d\n ",executor.getCompletedTaskCount());
for (int i = 0;i<list.size();i++){
Future<Integer>result = list.get(i);
System.out.printf("Main: Task %d: %s\n",i,result.isDone());
}
try {
Thread.sleep(50);
}catch (Exception e){
e.printStackTrace();
}
}while (executor.getCompletedTaskCount()<list.size());
int total = 0;
for (int i = 0;i<list.size();i++){
Future<Integer> result = list.get(i);
try {
total = total + result.get();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
Log.d("test","addAll = "+total);
executor.shutdown();
}
}
import android.util.Log;
import java.util.Random;
import java.util.concurrent.Callable;
public class SumTask implements Callable<Integer> {
private int startNum,endNum;
public SumTask(int start, int end) {
this.startNum = start;
this.endNum = end;
}
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = startNum;i<=endNum;i++){
sum = sum+i;
}
Thread.sleep(new Random().nextInt(1000));
Log.d("test","start = "+startNum+" end = "+ endNum+" THread = "+Thread.currentThread().getName());
System.out.printf("%s:%d\n",Thread.currentThread().getName(),sum);
return sum;
}
}
Fork /Join框架
fork/join框架是java7开始提供的一种并发框架,它可以将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果,并进行输出。
import java.util.concurrent.RecursiveTask;
public class SumTask extends RecursiveTask<Long> {
private int start;
private int end;
public SumTask(int start, int end) {
this.start = start;
this.end = end;
}
public static final int threadHolder = 5;
@Override
protected Long compute() {
Long sum = 0L;
boolean canCompute = (end - start) <= threadHolder;
if (canCompute) {
for (int i = start; i < end; i++) {
sum = sum + i;
}
} else {
int middle = (start + end) / 2;
SumTask sumTask1 = new SumTask(start,middle);
SumTask sumTask2 = new SumTask(middle,end);
invokeAll(sumTask1,sumTask2);
Long sum1 = sumTask1.join();
Long sum2 = sumTask2.join();
sum = sum1+sum2;
}
return sum;
}
}
ForkJoinPool pool = new ForkJoinPool();
SumTask task = new SumTask(1,1000000);
ForkJoinTask<Long> result = pool.submit(task);
do {
try {
Thread.sleep(50);
}catch (Exception e){
e.printStackTrace();
}
}while (!task.isDone());
Log.d("test","result = "+result);
fork方法和join方法
Fork/Join框架中提供的fork方法和join方法,可以说是该框架中提供的最重要的两个方法,它们和parallelism“可并行任务数量”配合工作,可以导致拆分的子任务T1.1、T1.2甚至TX在Fork/Join框架中不同的运行效果。例如TX子任务或等待其它已存在的线程运行关联的子任务,或在运行TX的线程中“递归”执行其它任务,又或者启动一个新的线程运行子任务……
fork方法用于将新创建的子任务放入当前线程的work queue队列中,Fork/Join框架将根据当前正在并发执行ForkJoinTask任务的ForkJoinWorkerThread线程状态,决定是让这个任务在队列中等待,还是创建一个新的ForkJoinWorkerThread线程运行它,又或者是唤起其它正在等待任务的ForkJoinWorkerThread线程运行它。
这里面有几个元素概念需要注意,ForkJoinTask任务是一种能在Fork/Join框架中运行的特定任务,也只有这种类型的任务可以在Fork/Join框架中被拆分运行和合并运行。ForkJoinWorkerThread线程是一种在Fork/Join框架中运行的特性线程,它除了具有普通线程的特性外,最主要的特点是每一个ForkJoinWorkerThread线程都具有一个独立的任务等待队列(work queue),这个任务队列用于存储在本线程中被拆分的若干子任务。
join方法用于让当前线程阻塞,直到对应的子任务完成运行并返回执行结果。或者,如果这个子任务存在于当前线程的任务等待队列(work queue)中,则取出这个子任务进行“递归”执行。其目的是尽快得到当前子任务的运行结果,然后继续执行。
并发数据结构
常用的数据结构是线程不安全的
ArrayList,HashMap,HashSet非同步
多个线程同时读写操作,可能会抛出异常或者数据错误
传统Vector,Hashtable等同步集合性能差
List<String> unsafeList = new ArrayList<>();
List<String> safeList1 = Collections.synchronizedList(new ArrayList<String>());
CopyOnWriteArrayList<String>safeList2 = new CopyOnWriteArrayList<>();
ListThread t1 = new ListThread(unsafeList);
ListThread t2 = new ListThread(safeList1);
ListThread t3 = new ListThread(safeList2);
for (int i = 0;i<10;i++){
Thread t = new Thread(t1,String.valueOf(i));
t.start();
}
for (int i = 0;i<10;i++){
Thread t = new Thread(t2,String.valueOf(i));
t.start();
}
for (int i = 0;i<10;i++){
Thread t = new Thread(t3,String.valueOf(i));
t.start();
}
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
Log.d("test","listThread1.list.size()="+t1.list.size());
Log.d("test","listThread1.list.size()="+t2.list.size());
Log.d("test","listThread1.list.size()="+t3.list.size());
Log.d("test","unsafeList:");
for (String s : t1.list){
if (s == null){
Log.d("test","null");
}else {
Log.d("test",s+ " ");
}
}
Log.d("test","safeList1:");
for (String s : t2.list){
if (s == null){
Log.d("test","null");
}else {
Log.d("test",s+" ");
}
}
Log.d("test","safeList2:");
for (String s : t3.list){
if (s == null){
Log.d("test","null");
}else {
Log.d("test",s+" ");
}
}
import java.util.List;
class ListThread implements Runnable{
public List<String> list;
public ListThread(List<String> list) {
this.list = list;
}
@Override
public void run() {
int i = 0;
while(i<10){
try {
Thread.sleep(10);
}catch (Exception e){
e.printStackTrace();
}
list.add(Thread.currentThread().getName());
i++;
}
}
}
2019-10-27 21:19:51.294 26100-26100/com.bai.psychedelic.forstudy D/test: listThread1.list.size()=97
2019-10-27 21:19:51.295 26100-26100/com.bai.psychedelic.forstudy D/test: listThread1.list.size()=100
2019-10-27 21:19:51.295 26100-26100/com.bai.psychedelic.forstudy D/test: listThread1.list.size()=100
List
Vector 同步安全,写多读少
ArrayList 不安全
Collections.synchronizedList(List list)基于synchronized,效率差
CopyOnWriteArrayList 读多写少,基于复制机制,非阻塞
Set
HashSet 不安全
Collections.synchronizedSet(Set set)基于synchronized,效率差
CopyOnWriteArraySet(基于CopyOnWriteArrayList实现)读多写少,非阻塞
Map
Hashtable 同步安全,写多读少
HashMap 不安全
Collections.synchronizedMap(Map map)基于synchronize,效率差
ConcurrentHashMap 读多写少,非阻塞
Queue&Deque
ConcurrentLinkedQueue 非阻塞
ArrayBlockingQueue/LinkedBlockingQueue阻塞
并发协作控制
Lock
Lock和Synchronized一样可以实现同步的效果
对比:
实现更复杂的临界区结构
tryLock方法可以预判锁是否空闲
允许分离读写操作,多个读,一个写
更好的性能
ReentrantLock 可重入的互斥锁
jdk中独占锁的实现除了使用关键字synchronized外,还可以使用ReentrantLock。虽然在性能上ReentrantLock和synchronized没有什么区别,但ReentrantLock相比synchronized而言功能更加丰富,使用起来更为灵活,也更适合复杂的并发场景。
ReentrantLock lock = new ReentrantLock();
lock.lock();
lock.unlock();
1.ReentrantLock和synchronized都是独占锁,只允许线程互斥的访问临界区。但是实现上两者不同:synchronized加锁解锁的过程是隐式的,用户不用手动操作,优点是操作简单,但显得不够灵活。一般并发场景使用synchronized的就够了;ReentrantLock需要手动加锁和解锁,且解锁的操作尽量要放在finally代码块中,保证线程正确释放锁。ReentrantLock操作较为复杂,但是因为可以手动控制加锁和解锁过程,在复杂的并发场景中能派上用场。
2.ReentrantLock和synchronized都是可重入的。synchronized因为可重入因此可以放在被递归执行的方法上,且不用担心线程最后能否正确释放锁;而ReentrantLock在重入时要却确保重复获取锁的次数必须和重复释放锁的次数一样,否则可能导致其他线程无法获得该锁。
公平锁是指当锁可用时,在锁上等待时间最长的线程将获得锁的使用权。而非公平锁则随机分配这种使用权。和synchronized一样,默认的ReentrantLock实现是非公平锁,因为相比公平锁,非公平锁性能更好。当然公平锁能防止饥饿,某些情况下也很有用。在创建ReentrantLock的时候通过传进参数true创建公平锁,如果传入的是false或没传参数则创建的是非公平锁
ReentrantLock lock = new ReentrantLock(true);
ReentrantReadWriteLock 可重入的读写锁
ReentrantReadWriteLock是Lock的另一种实现方式,我们已经知道了ReentrantLock是一个排他锁,同一时间只允许一个线程访问,而ReentrantReadWriteLock允许多个读线程同时访问,但不允许写线程和读线程、写线程和写线程同时访问。相对于排他锁,提高了并发性。在实际应用中,大部分情况下对共享数据(如缓存)的访问都是读操作远多于写操作,这时ReentrantReadWriteLock能够提供比排他锁更好的并发性和吞吐量。
读写锁内部维护了两个锁,一个用于读操作,一个用于写操作。所有 ReadWriteLock实现都必须保证 writeLock操作的内存同步效果也要保持与相关 readLock的联系。也就是说,成功获取读锁的线程会看到写入锁之前版本所做的所有更新。
ReentrantReadWriteLock支持以下功能:
1)支持公平和非公平的获取锁的方式;
2)支持可重入。读线程在获取了读锁后还可以获取读锁;写线程在获取了写锁之后既可以再次获取写锁又可以获取读锁;
3)还允许从写入锁降级为读取锁,其实现方式是:先获取写入锁,然后获取读取锁,最后释放写入锁。但是,从读取锁升级到写入锁是不允许的;
4)读取锁和写入锁都支持锁获取期间的中断;
5)Condition支持。仅写入锁提供了一个 Conditon 实现;读取锁不支持 Conditon ,readLock().newCondition() 会抛出 UnsupportedOperationException。
class CachedData {
Object data;
volatile boolean cacheValid; //缓存是否有效
ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
void processCachedData() {
rwl.readLock().lock(); //获取读锁
//如果缓存无效,更新cache;否则直接使用data
if (!cacheValid) {
// Must release read lock before acquiring write lock
//获取写锁前须释放读锁
rwl.readLock().unlock();
rwl.writeLock().lock();
// Recheck state because another thread might have acquired
// write lock and changed state before we did.
if (!cacheValid) {
data = ...
cacheValid = true;
}
// Downgrade by acquiring read lock before releasing write lock
//锁降级,在释放写锁前获取读锁
rwl.readLock().lock();
rwl.writeLock().unlock(); // Unlock write, still hold read
}
use(data);
rwl.readLock().unlock(); //释放读锁
}
}
Java并发编程–ReentrantReadWriteLock
Semaphore
emaphore 是一个计数信号量,必须由获取它的线程释放。
常用于限制可以访问某些资源的线程数量,例如通过 Semaphore 限流。
Semaphore 只有3个操作:
初始化
增加
减少
停车场停车例子:
import android.util.Log;
import java.util.concurrent.Semaphore;
public class SemaphoreExample {
private final Semaphore placeSemaphore = new Semaphore(5);
public boolean parking() throws InterruptedException {
if (placeSemaphore.tryAcquire()) {
Log.d("test", Thread.currentThread().getName() + "停车成功");
return true;
} else {
Log.d("test", Thread.currentThread().getName() + "没有空位");
return false;
}
}
public void leaving() throws InterruptedException {
placeSemaphore.release();
Log.d("test", Thread.currentThread().getName() + "驶离");
}
public static void main(String[] args) throws InterruptedException {
int tryToParkCnt = 10;
final SemaphoreExample example = new SemaphoreExample();
Thread[] parkers = new Thread[tryToParkCnt];
for (int i = 0; i < tryToParkCnt; i++) {
parkers[i] = new Thread(new Runnable() {
@Override
public void run() {
try {
long randomTime = (long) (Math.random() * 1000);
Thread.sleep(randomTime);
if (example.parking()) {
long parkingTime = (long) (Math.random() * 1200);
Thread.sleep(parkingTime);
example.leaving();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
parkers[i].start();
}
for (int i = 0; i < tryToParkCnt; i++) {
parkers[i].join();
}
}
}
Latch
等待锁,是一个同步辅助类
用来同步执行任务的一个或者多个线程
不是用来保护临界区或者共享资源
CountDownLatch
countDown()计数减1
await()等待latch变成0
Barrier
集合点,也是一个同步辅助类
允许多个线程在某一个点上进行同步
CyclicBarrier
构造函数是需要同步的线程数量
await等待其他线程,到达数量后就放行
CyclicBarrier是一个同步工具类,它允许一组线程互相等待,直到到达某个公共屏障点。与CountDownLatch不同的是该barrier在释放等待线程后可以重用,所以称它为循环(Cyclic)的屏障(Barrier)。
CyclicBarrier支持一个可选的Runnable命令,在一组线程中的最后一个线程到达之后(但在释放所有线程之前),该命令只在每个屏障点运行一次。若在继续所有参与线程之前更新共享状态,此屏障操作很有用。
import android.util.Log;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class CyclicBarrierExample {
/**
* 假定有三行数,用三个线程分别计算每一行的和,最终计算总和
* @param args
*/
public static void main(String[] args){
final int[][] numbers = new int[3][5];
final int[] results = new int[3];
int[] row1 = new int[]{1,2,3,4,5};
int[] row2 = new int[]{6,7,8,9,10};
int[] row3 = new int[]{11,12,13,14,15};
numbers[0] = row1;
numbers[1] = row2;
numbers[2] = row3;
CalculateFinalResult finalResultCalculator = new CalculateFinalResult(results);
CyclicBarrier barrier = new CyclicBarrier(3,finalResultCalculator);
//当有3个线程在barrier上await,就执行finalResultCalculator
for (int i =0;i<3;i++){
CalculateEachRow rowCalculate = new CalculateEachRow(barrier,numbers,i,results);
new Thread(rowCalculate).start();
}
}
}
class CalculateEachRow implements Runnable{
final int[][] numbers;
final int rowNumber;
final int[]res;
final CyclicBarrier barrier;
CalculateEachRow(CyclicBarrier barrier,int[][]numbers,int rowNumber,int[]res){
this.barrier = barrier;
this.numbers = numbers;
this.rowNumber = rowNumber;
this.res = res;
}
@Override
public void run() {
int[]row = numbers[rowNumber];
int sum = 0;
for (int data:row){
sum+=data;
res[rowNumber]=sum;
}
try {
Log.d("test",Thread.currentThread().getName()+":计算第"+(rowNumber+1)+"行结束,结果为:"+sum);
barrier.await();
}catch (InterruptedException | BrokenBarrierException e){
e.printStackTrace();
}
}
}
class CalculateFinalResult implements Runnable{
final int[]eachRowRes;
int finalRes;
public int getFinalResult(){
return finalRes;
}
CalculateFinalResult(int[]eachRowRes){
this.eachRowRes = eachRowRes;
}
@Override
public void run() {
int sum = 0;
for (int data:eachRowRes){
sum+=data;
}
finalRes = sum;
Log.d("test","最终的结果为:"+finalRes);
}
}
Phaser
允许执行阶段性的任务,同步辅助类
在每个阶段结束位置对线程进行同步,当所有的线程都达到了这步,再进行下一步
Phaser
arrive()
arriveAndAwaitAdvance()
import android.util.Log;
import java.util.concurrent.Phaser;
public class PhaserExample {
/**
* 假设举行考试,总共三道大题,每次下发一道题目,等所有学生完成后再进行下一道
*/
public static void main(String[]args){
int studentsCnt = 5;
Phaser phaser = new Phaser(studentsCnt);
for (int i =0;i<studentsCnt;i++){
new Thread(new Student(phaser)).start();
}
}
}
class Student implements Runnable{
private final Phaser phaser;
public Student(Phaser phaser){
this.phaser = phaser;
}
@Override
public void run() {
try {
doTesting(1);
phaser.arriveAndAwaitAdvance();//等到5个线程都到了才放行
doTesting(2);
phaser.arriveAndAwaitAdvance();
doTesting(3);
phaser.arriveAndAwaitAdvance();
}catch (InterruptedException e){
e.printStackTrace();
}
}
private void doTesting(int i) throws InterruptedException{
String name = Thread.currentThread().getName();
Log.d("test",name+"开始答第"+i+"题");
long thinkingTime = (long)(Math.random()*1000);
Thread.sleep(thinkingTime);
Log.d("test",name+"第"+i+"题答题结束");
}
}
Exchanger
允许在并发线程中互相交换消息
允许在2个线程中定义同步点,当两个线程都到达同步点,他们交换数据结构
exchange(),线程双方互相交互数据
交换数据是双向的
import android.util.Log;
import java.util.Scanner;
import java.util.concurrent.Exchanger;
public class ExchangerExample {
public static void main(String[] args) throws InterruptedException {
Exchanger<String> exchanger = new Exchanger<>();
BackgroundWorker worker = new BackgroundWorker(exchanger);
new Thread(worker).start();
Scanner scanner = new Scanner(System.in);
while (true) {
Log.d("test", "输入要查询属性的学生姓名");
String input = scanner.nextLine().trim();
exchanger.exchange(input);//把用户输入传递给线程
String value = exchanger.exchange(null);//拿到线程反馈结果
if ("exit".equals(value)) {
break;
}
Log.d("test", "查询结果:" + value);
}
scanner.close();
}
}
class BackgroundWorker implements Runnable {
final Exchanger<String> exchanger;
BackgroundWorker(Exchanger<String> exchanger) {
this.exchanger = exchanger;
}
@Override
public void run() {
while (true) {
try {
String item = exchanger.exchange(null);
switch (item) {
case "zhangsan":
exchanger.exchange("90");
break;
case "lisi":
exchanger.exchange("80");
break;
case "wangwu":
exchanger.exchange("70");
break;
case "exit":
exchanger.exchange("exit");
return;
default:
exchanger.exchange("查无此人");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
扩展
协程
协程这个概念几十年前就有了,但是协程只是在近年才开始兴起,应用的语言有:go 、goLand、kotlin、python , 都是支持协程的,可能不同平台 API 上有差异。Java不支持协程,但是Kotlin是支持的,kotlin是一种兼容java并且可以编译为java字节码的语言。其实我认为就是java的语法糖,比java更加简便安全。
协程 - 也叫微线程,是一种新的多任务并发的操作手段(也不是很新,概念早就有了)
协程的开发人员 Roman Elizarov 是这样描述协程的:协程就像非常轻量级的线程。线程是由系统调度的,线程切换或线程阻塞的开销都比较大。而协程依赖于线程,但是协程挂起时不需要阻塞线程,几乎是无代价的,协程是由开发者控制的。所以协程也像用户态的线程,非常轻量级,一个线程中可以创建任意个协程。
Coroutine,翻译成”协程“,初始碰到的人马上就会跟进程和线程两个概念联系起来。直接先说区别,Coroutine是编译器级的,Process和Thread是操作系统级的。Coroutine的实现,通常是对某个语言做相应的提议,然后通过后成编译器标准,然后编译器厂商来实现该机制。Process和Thread看起来也在语言层次,但是内生原理却是操作系统先有这个东西,然后通过一定的API暴露给用户使用,两者在这里有不同。Process和Thread是os通过调度算法,保存当前的上下文,然后从上次暂停的地方再次开始计算,重新开始的地方不可预期,每次CPU计算的指令数量和代码跑过的CPU时间是相关的,跑到os分配的cpu时间到达后就会被os强制挂起。Coroutine是编译器的魔术,通过插入相关的代码使得代码段能够实现分段式的执行,重新开始的地方是yield关键字指定的,一次一定会跑到一个yield对应的地方
对于多线程应用,CPU通过切片的方式来切换线程间的执行,线程切换时需要耗时(保存状态,下次继续)。协程,则只使用一个线程,在一个线程中规定某个代码块执行顺序。协程能保留上一次调用时的状态,不需要像线程一样用回调函数,所以性能上会有提升。缺点是本质是个单线程,不能利用到单个CPU的多个核
Coroutine 协程是跑在线程上的优化产物,被称为轻量级 Thread,拥有自己的栈内存和局部变量,共享成员变量。传统 Thread 执行的核心是一个while(true) 的函数,本质就是一个耗时函数,Coroutine 可以用来直接标记方法,由程序员自己实现切换,调度,不再采用传统的时间段竞争机制。在一个线程上可以同时跑多个协程,同一时间只有一个协程被执行,在单线程上模拟多线程并发,协程何时运行,何时暂停,都是有程序员自己决定的,使用: yield/resume API,优势如下:
因为在同一个线程里,协程之间的切换不涉及线程上下文的切换和线程状态的改变,不存在资源、数据并发,所以不用加锁,只需要判断状态就OK,所以执行效率比多线程高很多
协程是非阻塞式的(也有阻塞API),一个协程在进入阻塞后不会阻塞当前线程,当前线程会去执行其他协程任务
程序员能够控制协程的切换,是通过yield API 让协程在空闲时(比如等待io,网络数据未到达)放弃执行权,然后在合适的时机再通过resume API 唤醒协程继续运行。协程一旦开始运行就不会结束,直到遇到yield交出执行权。Yield、resume 这一对 API 可以非常便捷的实现异步,这可是目前所有高级语法孜孜不倦追求的
具体可以看原文 链接:https://www.jianshu.com/p/76d2f47b900d














 758
758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









