







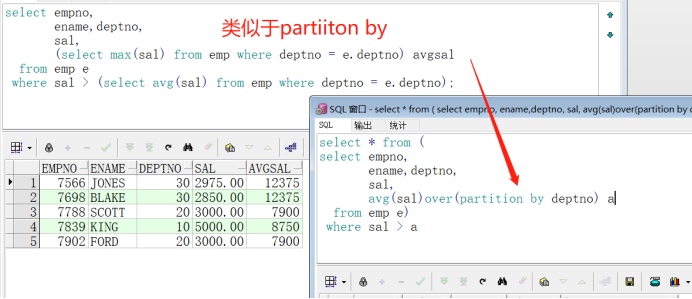
4、窗口总结
1、unbounded preceding:从当前分区的第一行开始,到当前行结束。
2、current row:从当前行开始,也结束于当前行。
3、[numeric expression] preceding:对于rows来说从当前行之前的第[numeric expression]行开始,到当前行结束。对range来说从小于数值表达式的值开始,到当前行结束。
4、[numeric expression] following:与[numeric expression] preceding相反。
oracle窗口函数
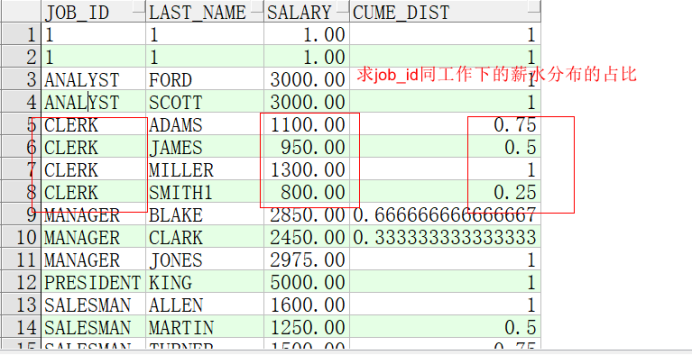
CUME_DIST
下面的示例计算采购部门中每个员工的薪水百分比。例如,40%的文员的薪水低于或等于Himuro。
SELECT job_id, last_name, salary, CUME_DIST()
OVER (PARTITION BY job_id ORDER BY salary) AS cume_dist
FROM employees
ORDER BY job_id, last_name, salary, cume_dist;
FIRST
LAST
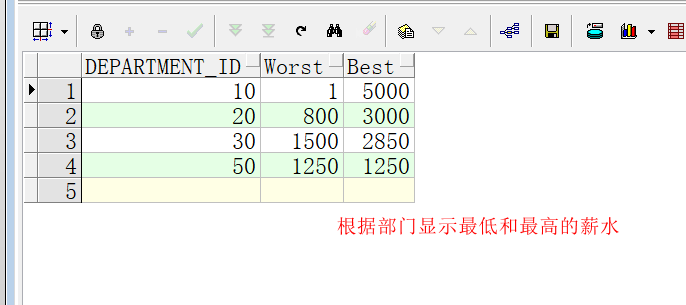
以下示例在示例表的每个部门中返回hr.employees佣金最低的员工的最低薪水和佣金最高的员工的最高薪水:
SELECT department_id,
MIN(salary) KEEP (DENSE_RANK FIRST ORDER BY commission_pct) "Worst",
MAX(salary) KEEP (DENSE_RANK LAST ORDER BY commission_pct) "Best"
FROM employees
GROUP BY department_id
ORDER BY department_id;
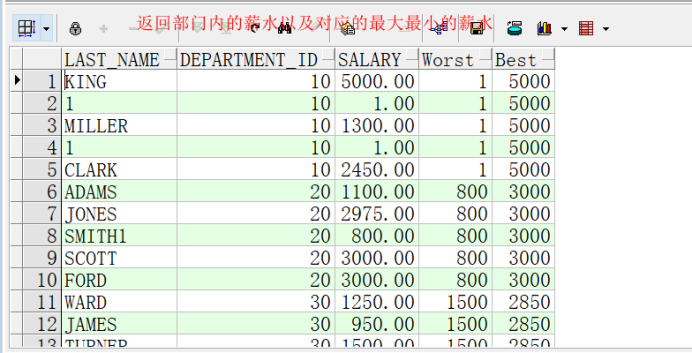
下一个示例进行与上一个示例相同的计算,但是返回部门内每个员工的结果:
SELECT last_name, department_id, salary,
MIN(salary) KEEP (DENSE_RANK FIRST ORDER BY commission_pct)
OVER (PARTITION BY department_id) "Worst",
MAX(salary) KEEP (DENSE_RANK LAST ORDER BY commission_pct)
OVER (PARTITION BY department_id) "Best"
FROM employees
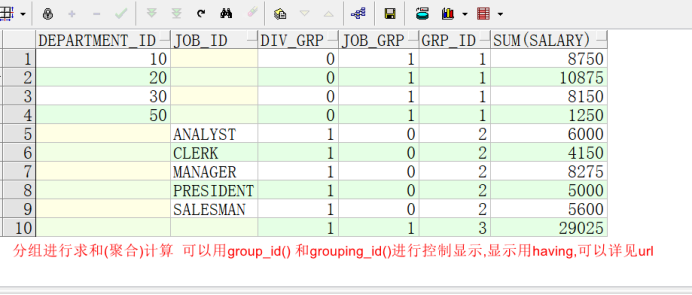
GROUP_ID
Grouping
GROUP_ID
GROUPING_ID
Grouping
grou cude
Grou by grouping sets都是用来分组求统计的
select
DEPARTMENT_ID,job_id,
grouping(DEPARTMENT_ID) as div_grp,
grouping(job_id) as job_grp,
grouping_id(DEPARTMENT_ID,job_id) as grp_id,
sum(salary)
from employees
group by cube(DEPARTMENT_ID,job_id)
having grouping_id(DEPARTMENT_ID,job_id) > 0
order by DEPARTMENT_ID,job_id;
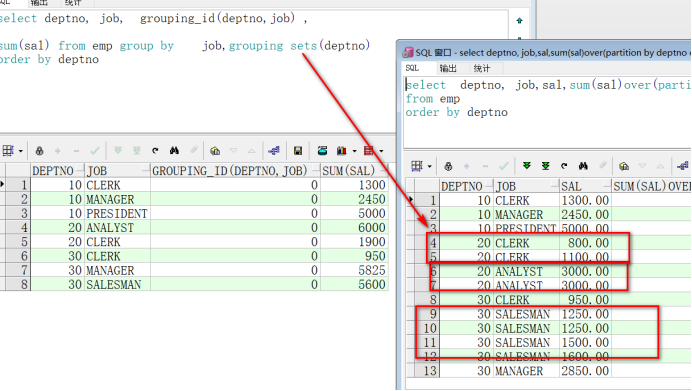
select deptno, job, grouping_id(deptno,job) ,
sum(sal) from emp group by job,grouping sets(deptno)
order by deptno
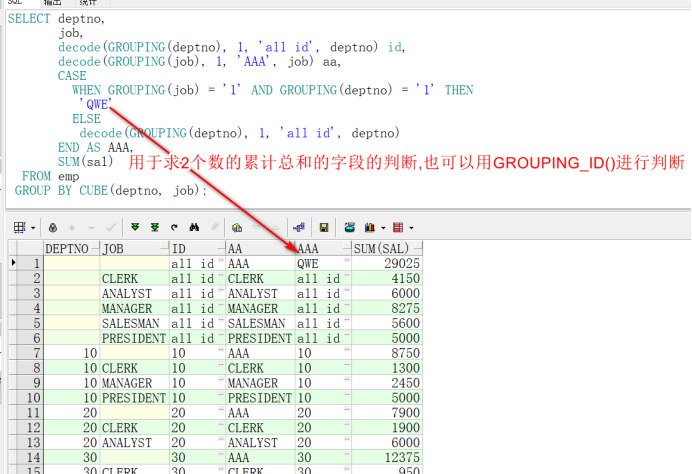
SELECT deptno,
job,
decode(GROUPING(deptno), 1, 'all id', deptno) id,
decode(GROUPING(job), 1, 'AAA', job) aa,
CASE
WHEN GROUPING(job) = '1' AND GROUPING(deptno) = '1' THEN
'QWE'
ELSE
decode(GROUPING(deptno), 1, 'all id', deptno)
END AS AAA,
SUM(sal)
FROM emp
GROUP BY CUBE(deptno, job);
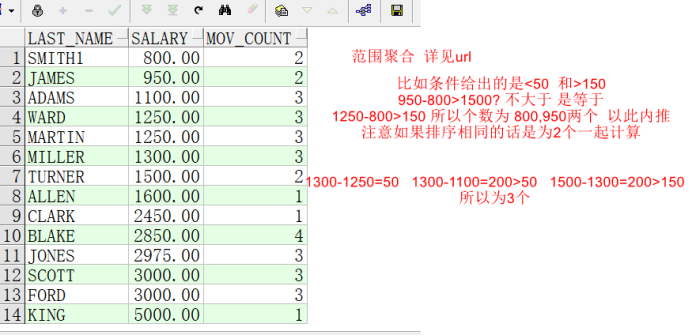
SELECT last_name, salary,
COUNT(*) OVER (ORDER BY salary RANGE BETWEEN 50 PRECEDING AND
150 FOLLOWING) AS mov_count
FROM employees
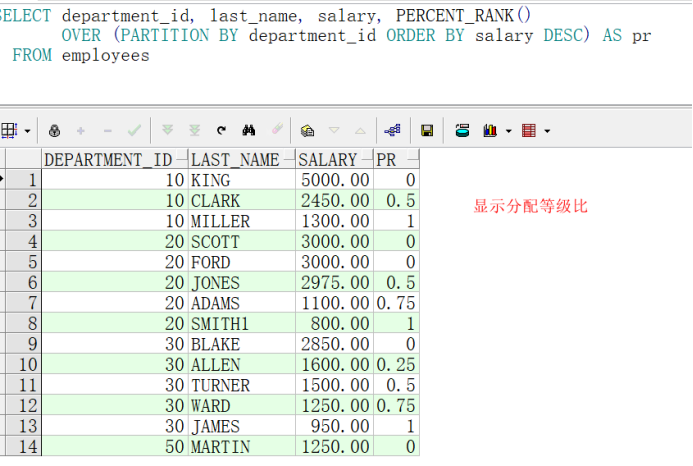
PERCENT_RANK
SELECT department_id, last_name, salary, PERCENT_RANK()
OVER (PARTITION BY department_id ORDER BY salary DESC) AS pr
FROM employees

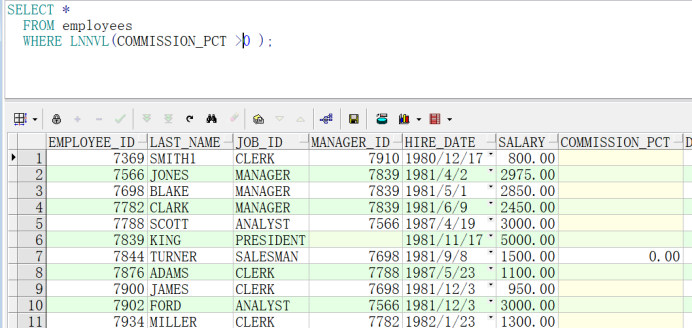
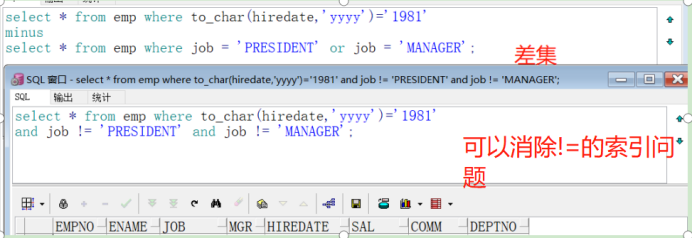
LNNVL
得到与条件相反的结果 空值包含所有范围 要用is null 进行过滤
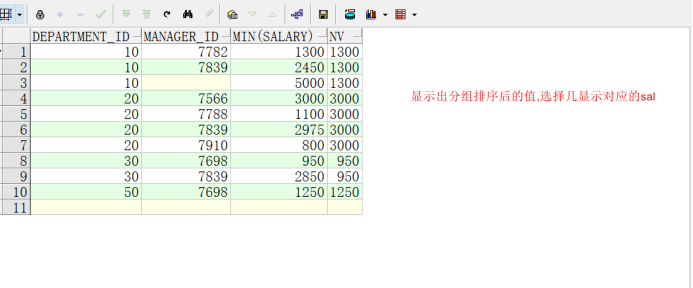
NTH_VALUE
SELECT DEPARTMENT_ID, MANAGER_ID, MIN(SALARY),
NTH_VALUE(MIN(SALARY), 1) OVER (PARTITION BY DEPARTMENT_ID ORDER BY MANAGER_ID
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) nv
FROM employees
GROUP BY DEPARTMENT_ID, MANAGER_ID
order by DEPARTMENT_ID
NTILE
SELECT last_name, salary, NTILE(7) OVER (ORDER BY salary DESC) AS quartile
FROM employees

PERCENT_RANK
PRESENTNNV
PRESENTV
Oracle的 MODEL 查询
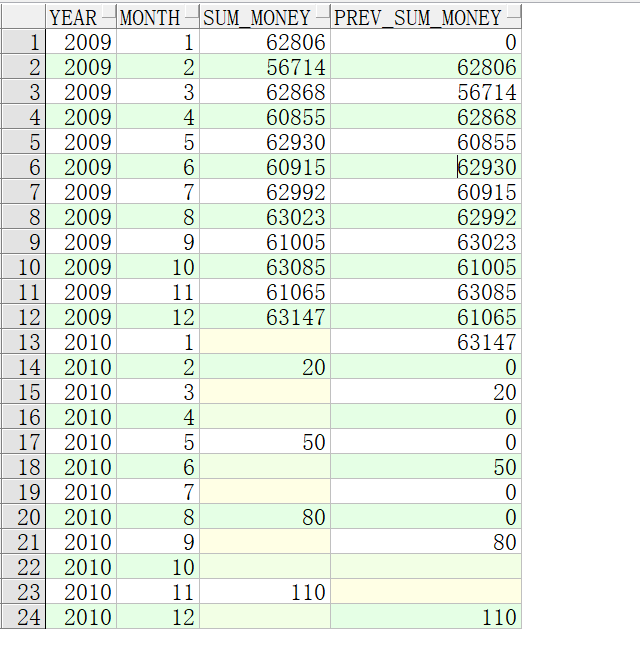
介绍了根据日期进行操作的方法
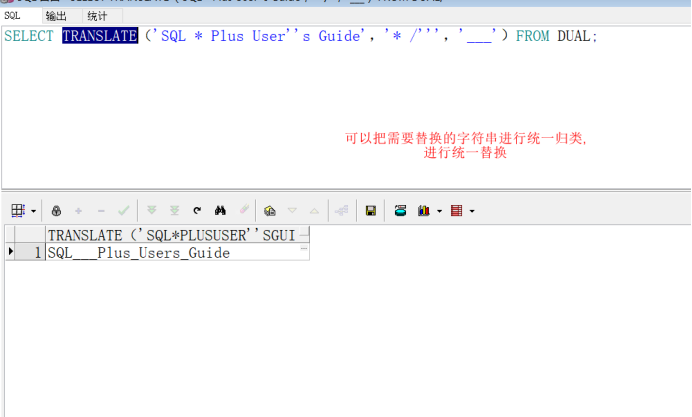
TRANSLATE

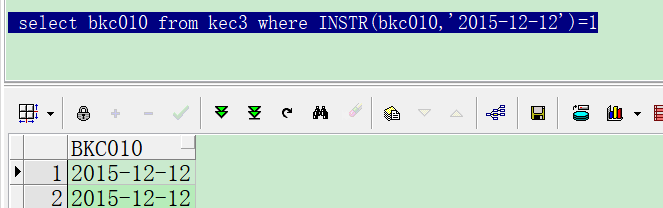
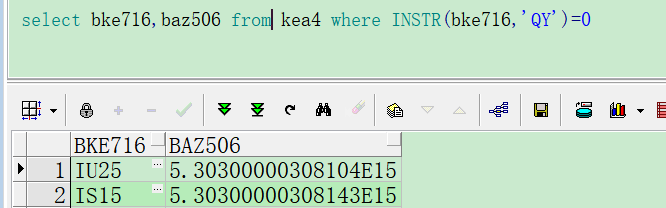



Oracle中REGEXP_SUBSTR函数的使用说明:
Oracle Start With关键字
Oracle函数sys_connect_by_path 详解
oracle的 listagg() WITHIN GROUP ()函数使用
sum()over()
Oracle分析函数Over()
Oracle中row_number()、rank()、dense_rank() 的区别
create select from 和 insert select from
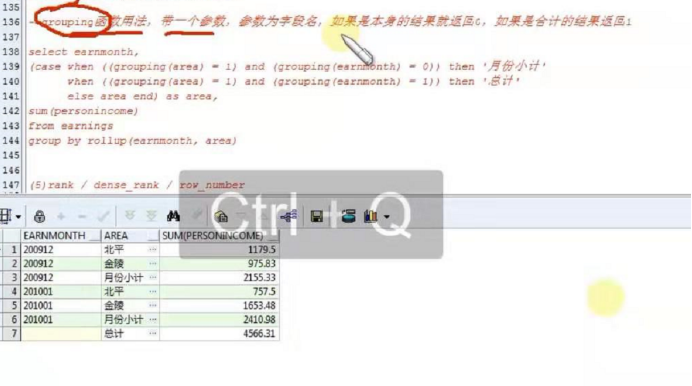
oracle分组汇总统计函数grouping
roup by、rollup、cube的用法以及区别
oracle 递归查询 CONNECT BY、START WITH、CONNECT_BY_ROOT、CONNECT_BY_ISLEAF、SYS_CONNECT_BY_PATH
oracle函数merger用法

Oracle数据库,数字强制显示2位小数
oracle使用 extract获取当前时间,并比较两个时间
Oracle:Pivot 和 Unpivot 转多列并包含多个名称
Oracle行转列,pivot函数和unpivot函数
wm_concat函数用法
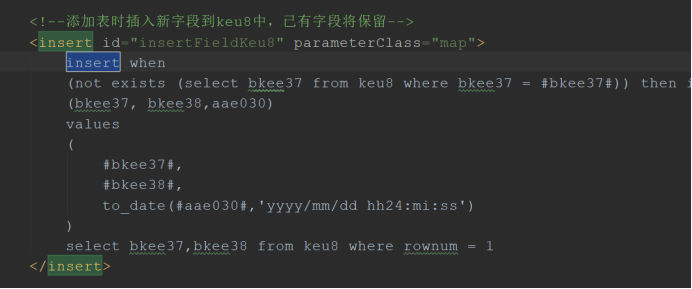
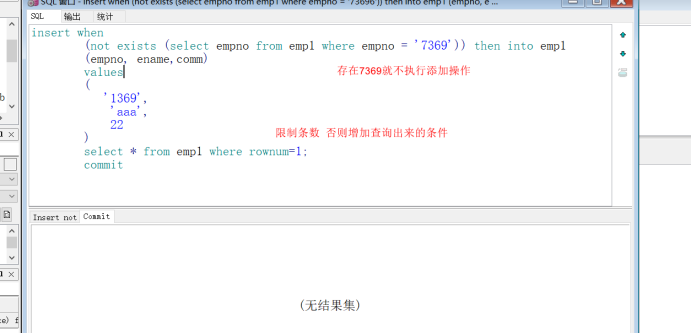
注意,使用insert when需要表里面有数据,如果没数据则添加不进去,建议先添加一条数据在使用此语法
增加序列为一列字段(适用于新增后序列空着的情况)
update kh25 set bkej43=SE_AAZ866.nextval;

















 4273
4273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











