






开源项目热度榜单
某个开源社区希望将最近热度比较高的开源项目出一个榜单,推荐给社区里面的开发者。对于每个开源项目,开发者可以进行关注(watch)、收藏(star)、fork、提issue、提交合并请求(MR)等。
数据库里面统计了每个开源项目关注、收藏、fork、issue、MR的数量,开源项目的热度根据这5个维度的加权求和进行排序。
H = (Wwatch * #watch) + (Wstar * #star) + (Wfork * #fork) + (Wissue * #issue) + (Wmr * #mr)
H表示热度值
Wwatch、Wstar、Wfork、Wissue、Wmr分别表示5个统计维度的权重。
#watch、#star、#fork、#issue、#mr分别表示5个统计维度的统计值。
榜单按照热度值降序排序,对于热度值相等的,按照项目名字转换为全小写字母后的字典序排序(‘a’,‘b’,‘c’,…,‘x’,‘y’,‘z’)。
输入描述
第一行输入为N,表示开源项目的个数,0 < N <100。
第二行输入为权重值列表,一共 5 个整型值,分别对应关注、收藏、fork、issue、MR的权重,权重取值 0 < W ≤ 50。
第三行开始接下来的 N 行为开源项目的统计维度,每一行的格式为:
name nr_watch nr_start nr_fork nr_issue nr_mr
其中 name 为开源项目的名字,由英文字母组成,长度 ≤ 50,其余 5 个整型值分别为该开源项目关注、收藏、fork、issue、MR的数量,数量取值 0 < nr ≤ 1000。
输出描述
按照热度降序,输出开源项目的名字,对于热度值相等的,按照项目名字转换为全小写后的字典序排序(‘a’ > ‘b’ > ‘c’ > … > ‘x’ > ‘y’ > ‘z’)。

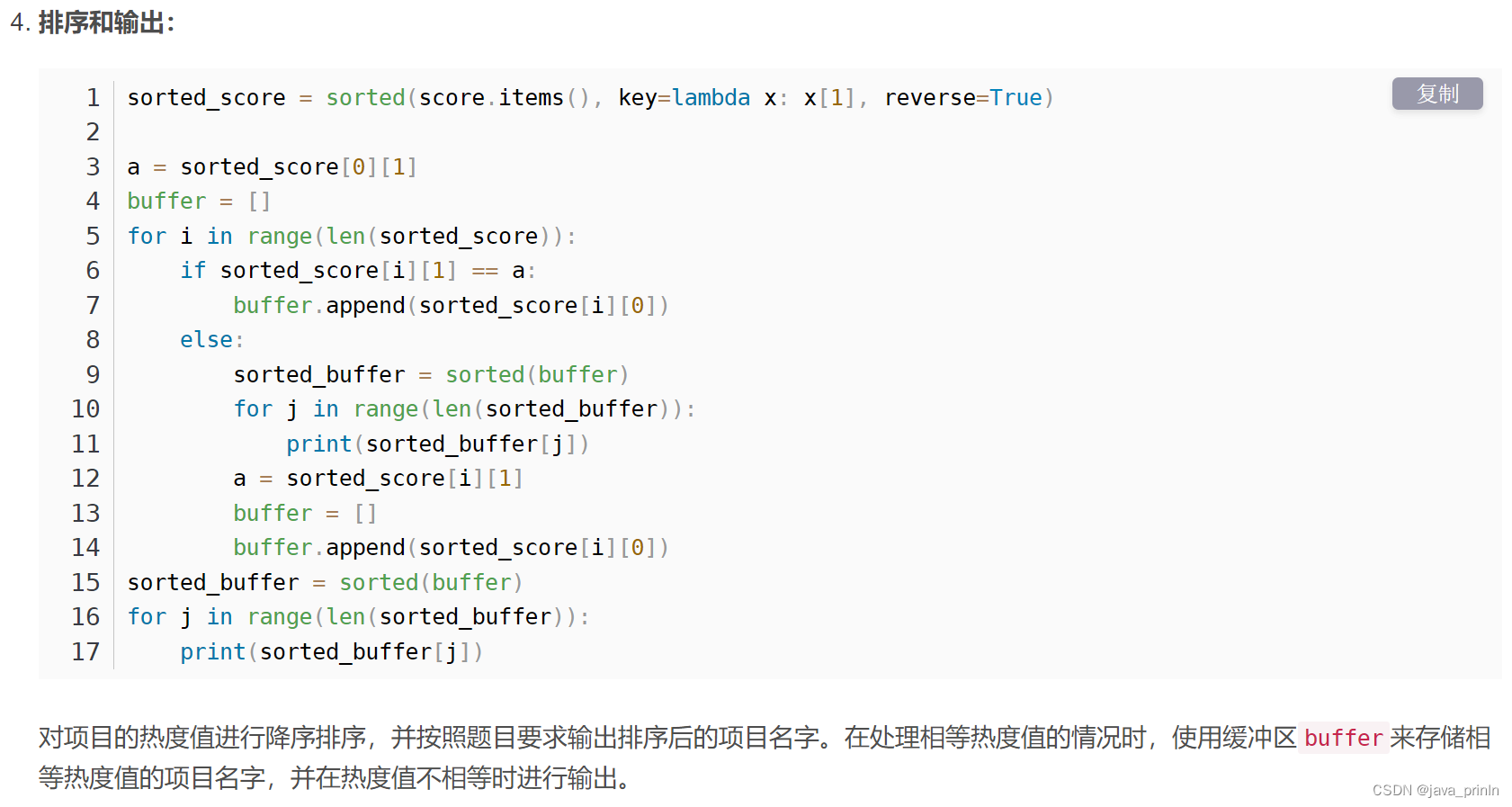
def calc(list1, list2):
ret = 0
for i in range(len(list1)):
ret += list1[i] * list2[i]
return ret
number = int(input())
weights = list(map(int, input().split()))
projects = {}
for i in range(number):
tmp = input().split()
name = tmp[0]
tmp.pop(0)
projects[name] = list(map(int, tmp))
score = {}
for name in projects:
score[name] = calc(weights, projects[name])
sorted_score = sorted(score.items(), key=lambda x: x[1], reverse=True)
a = sorted_score[0][1]
buffer = []
for i in range(len(sorted_score)):
if sorted_score[i][1] == a:
buffer.append(sorted_score[i][0])
else:
sorted_buffer = sorted(buffer)
for j in range(len(sorted_buffer)):
print(sorted_buffer[j])
a = sorted_score[i][1]
buffer = []
buffer.append(sorted_score[i][0])
sorted_buffer = sorted(buffer)
for j in range(len(sorted_buffer)):
print(sorted_buffer[j])



API集群负载统计
题目描述
某个产品的RESTful API集合部署在服务器集群的多个节点上,近期对客户端访问日志进行了采集,需要统计各个API的访问频次,根据热点信息在服务器节点之间做负载均衡,现在需要实现热点信息统计查询功能。
RESTful API是由多个层级构成,层级之间使用 / 连接,如 /A/B/C/D 这个地址,A属于第一级,B属于第二级,C属于第三级,D属于第四级。
现在负载均衡模块需要知道给定层级上某个名字出现的频次,未出现过用0表示,实现这个功能。
输入描述
第一行为N,表示访问历史日志的条数,0 < N ≤ 100。
接下来N行,每一行为一个RESTful API的URL地址,约束地址中仅包含英文字母和连接符 / ,最大层级为10,每层级字符串最大长度为10。
最后一行为层级L和要查询的关键字。
输出描述
输出给定层级上,关键字出现的频次,使用完全匹配方式(大小写敏感)。

def do_search(paths, layer, key):
count = 0
for path in paths:
components = path.split("/")
if len(components) >= layer + 1 and components[layer] == key:
count += 1
print(count)
# 读取输入
N = int(input())
logs = [input() for _ in range(N)]
level, keyword = input().split()
# 调用函数进行统计和输出
do_search(logs, int(level) - 1, keyword)

整数对最小和
题目描述:整数对最小和(分值100)
给定两个整数数组array1、array2,数组元素按升序排列。
假设从array1、array2中分别取出一个元素可构成一对元素,现在需要取出k对元素,
并对取出的所有元素求和,计算和的最小值。
注意:
两对元素如果对应于array1、array2中的两个下标均相同,则视为同一对元素。
输入描述
输入两行数组array1、array2,每行首个数字为数组大小size(0 < size <= 100);
0 < array1[i] <= 1000
0 < array2[i] <= 1000
接下来一行为正整数k
0 < k <= array1.size() * array2.size()
输出描述
满足要求的最小和

import heapq
def min_sum(array1, array2, k):
array = []
total = 0
i, j = 0, 0
heapq.heappush(array, (array1[i] + array2[j], i, j))
visited = set()
while k > 0 and array:
value, i, j = heapq.heappop(array)
if (value, i, j) in visited:
continue
visited.add((value, i, j))
total += value
if i + 1 < len(array1):
heapq.heappush(array, (array1[i + 1] + array2[j], i + 1, j))
if j + 1 < len(array2):
heapq.heappush(array, (array1[i] + array2[j + 1], i, j + 1))
k -= 1
return total
# 读取输入
lines = [line.strip() for line in sys.stdin.readlines()]
array1 = [int(n) for n in lines[0].split()][1:]
array2 = [int(n) for n in lines[1].split()][1:]
k = int(lines[2])
# 计算并输出结果
result = min_sum(array1, array2, k)
print(result)
















 173
173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









