






十二.左程云算法基础班整理(十二)(c++)
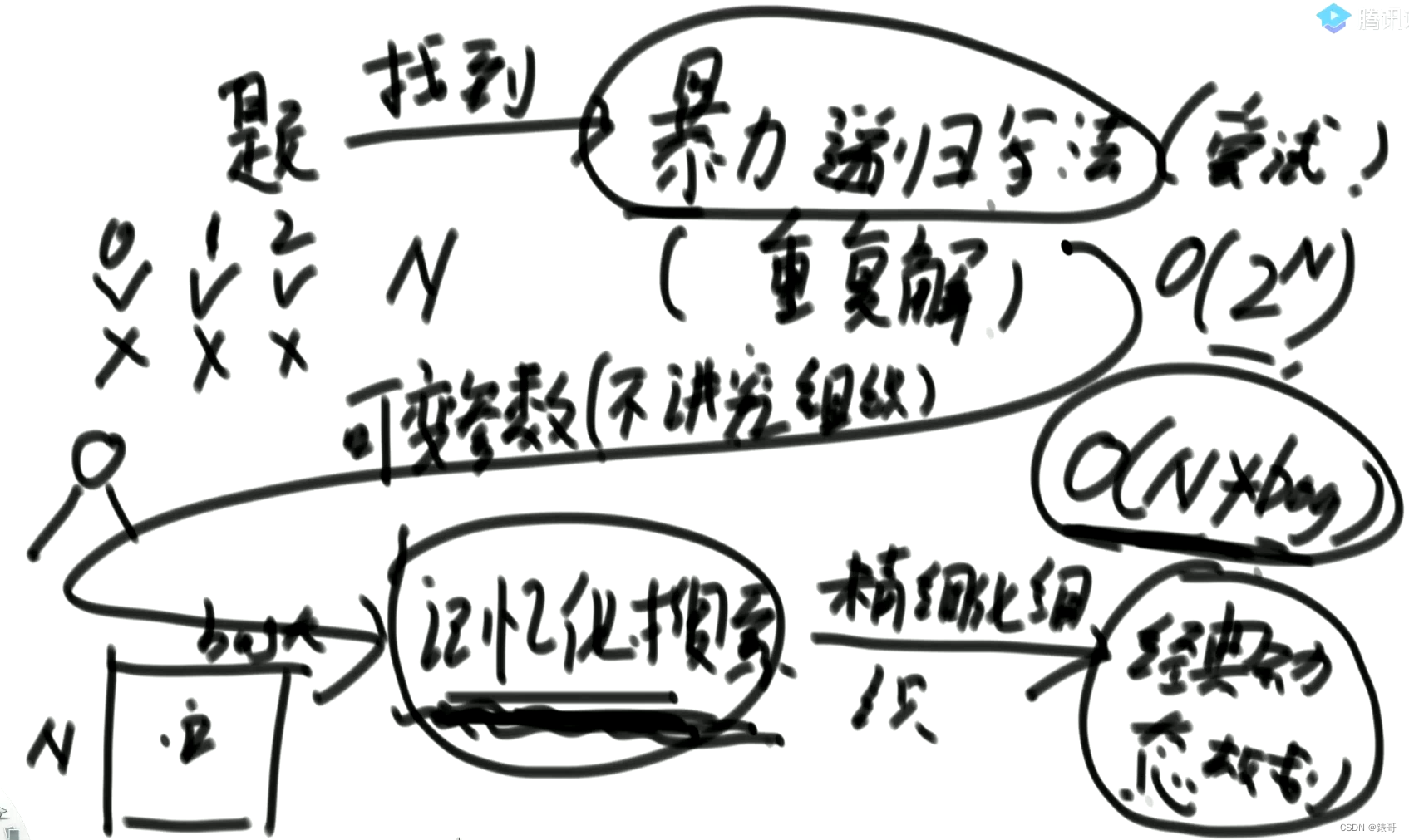
几个模型反复练
3条主线,暴力递归一旦改出来,怎么往下优化。
设计暴力递归怎么知道靠谱不靠谱
给4个模型,往上面编。
按照设计原则来往尝试模型上套
常见的四种尝试模型
1.从左往右的尝试模型(背包问题,从左往右考虑每个位置要还是每个位置不要,数字转换成字母的问题,考虑多大一串数字转换成字母)
2.范围上的尝试模型(纸牌博弈问题)
3.多样本位置全对应的尝试模型
4.寻找业务限制的尝试模型
如何分析有没有重复解?
列出调用过程,可以只列出前几层
有没有重复解,一看便知
如何找打某个问题的动态规划方式?
1.设计暴力递归:重要原则+4种常见尝试模型!重点!!!
2.分析有没有重复解:套路解决
3.用记忆化搜索->用严格表结构实现动态规划:套路解决
4.看看能否继续优化:套路解决
怎么猜才能猜得对?
面试中暴力递归的设计原则
1.每一个可变参数的类型,一定不要比int更加复杂
2.原则1可以违反,让类型突破到一维线性结构,那必须是唯一可变参数(比如线性字符串)
3.如果发现原则1被违反,但不违反原则2,只需要做到记忆化搜索即可
4.可变参数的个数,能少则少
如果可变参数是int a,则是一张一维表。如果可变参数是int a,int b,则dp是一张二维表。如果可变参数一个是int a,一个是bool b,则dp表有两张,为true时一张一维表,为false时一张一维表。
不可能让设计数组的参数。

暴力递归改动态规划如下所示。
如果递归过程中无枚举行为,意思是依赖的是优先的状态,记忆化搜索傻缓存,cache就可以了,不用再改动态规划,两者时间复杂度是一样的。但是表中有枚举行为的话,要转成经典动态规划,因为后续可能会有新的优化,枚举是指for或者while循环枚举。
12.1斐波那契数列
什么暴力递归可以继续进行优化?
有重复调用同一个子问题的解,这种递归可以进行优化。
如果每一个子问题都是不同的解,无法优化也不用优化。
斐波那契数列,可以进行优化。
暴力递归为什么暴力?
因为有大量的重复计算过程。比如计算斐波那契的第七项F(7);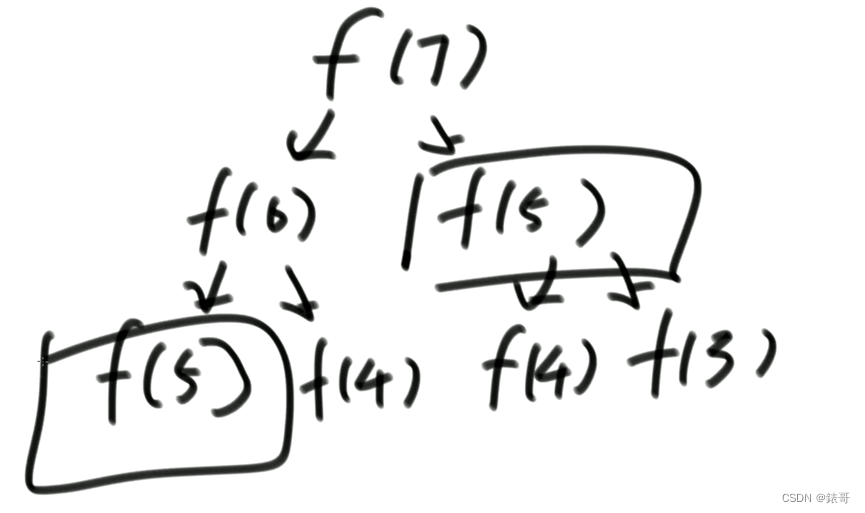
再次计算F(5),就会浪费大量时间。因此可以用一个缓存结构将下面的结果存下来,可以带来时间上的大量优化。
#include<iostream>
using namespace std;
int f(int n)
{
if (n == 1)
{
return 1;
}
if (n == 2)
{
return 1;
}
return f(n - 1) + f(n - 2);
}
int main()
{
cout << f(10) << endl;
system("pause");
return 0;
}
斐波那契数列可以用一种方法把O(N)的时间复杂度优化成log(N)的。
12.2机器人行走(阿里巴巴原题)
假设有排成一行的N个位置,记为1~N,N一定大于或等于2.
开始时机器人在其中的M位置上(M一定是1-N位置中的一个)。
如果开始机器人来到1位置,那么下一步只能往右来到2位置;
如果机器人来到N位置,那么下一步只能往左来到N-1位置;
如果机器人来到中间位置,那么下一步可以往左走或者往右走;
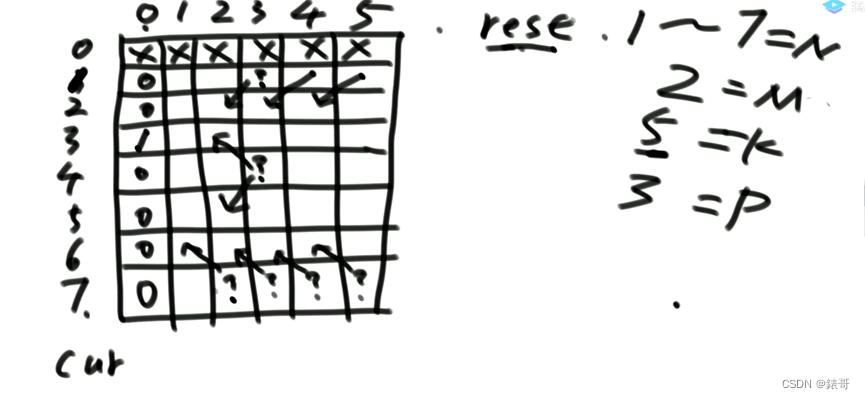
规定机器人必须走K步,最终能来到P位置(P也是1-N中的一个)的方法有多少种。
给定四个参数N、M、K、P,返回方法数。
N是几个位置,M是开始点,P是结束点,K是经过了几步。
例如,F(6,3,3,4)的构成
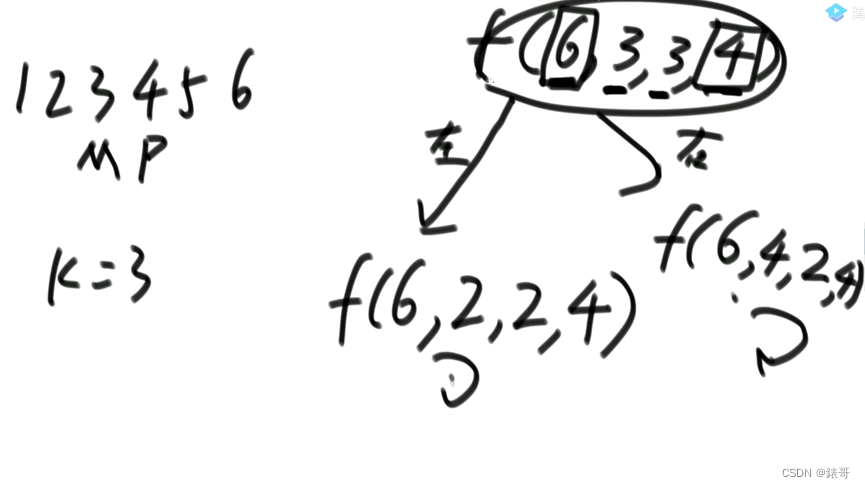
其中有很多过程可以进行重复使用,因此可以用一个缓存将其记录下来,加快速度。
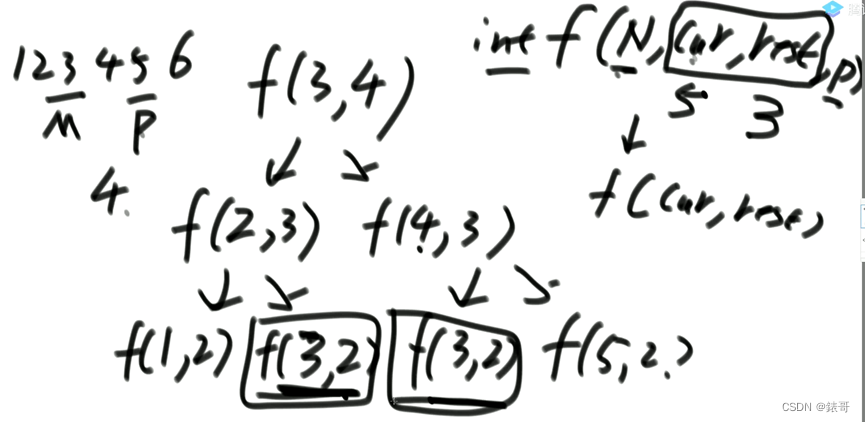
如上图所示,其中f(3,2)重复了很多次,完全可以用一个缓存将其记录下来,之后不用再次计算,直接在里面取值就行了。
int waysCache(int N, int M, int K, int P)
{
//参数无效直接返回0
if (N < 2 || K < 1 || M < 1 || M > N || P < 1 || P > N)
{
return 0;
}
//可以根据实际题解进行初始化
vector<vector<int>> dp(N + 1, vector<int>(K + 1));
for (int row = 0; row <= N; row++)
{
for (int col = 0; col <= K; col++)
{
dp[row][col] = -1;//先初始化为-1,表示当前的组合还没有算过。
}
}
return walkCache(N, M, K, P, dp);
}
int walkCache(int N, int cur, int rest, int P, vector<vector<int>>& dp)//要指出后面的来
{
if (dp[cur][rest] != -1)
{
return dp[cur][rest];
}
if (rest == 0)
{
dp[cur][rest] = cur == P ? 1 : 0;
return dp[cur][rest];
}
if (cur == 1)
{
dp[cur][rest] = walkCache(N, 2, rest - 1, P, dp);
return dp[cur][rest];
}
if (cur == N)
{
dp[cur][rest] = walkCache(N, N - 1, rest - 1, P, dp);
return dp[cur][rest];
}
dp[cur][rest] = walkCache(N, cur + 1, rest - 1, P, dp)
+ walkCache(N, cur - 1, rest - 1, P, dp);
return dp[cur][rest];
}
这就是动态规划,什么是动态规划,递归过程中有重复过程,加缓存记录下来,下次直接用,这就是动态规划。
遇到重复的解,就去拿缓存里的东西,如果没算过,那就去算,这就是动态规划。
这道题的动态规划是一张二维表,因为两个可变参数,所有组合都要去求。
找依赖关系,箭头表示了依赖关系。
看着暴力递归过程,根据表改动态规划。
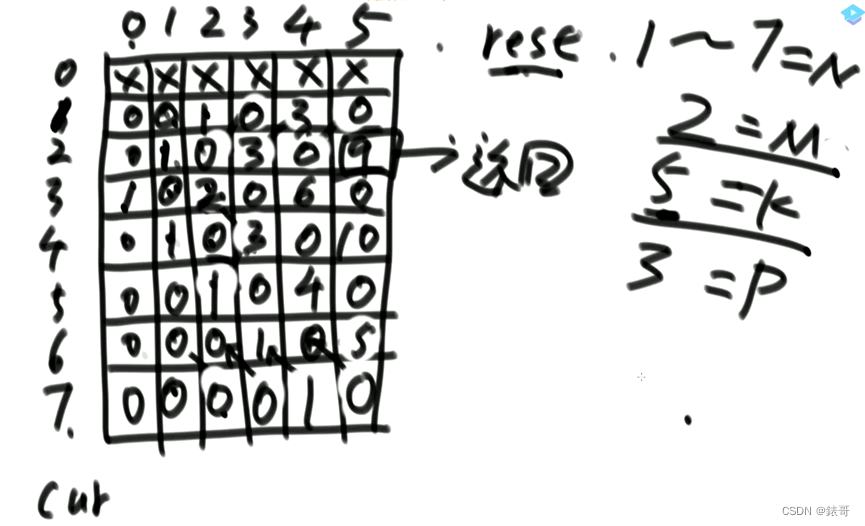
把暴力递归的分析过程抽象出来,都会得到动态规划。
有限参数是N个,则dp就是一个N维表。
只要能试出由可变参数改成的暴力递归,就能改成动态规划。
不是所有暴力递归都能改成动态规划,而是所有动态规划都来自某些暴力递归。
有一些暴力递归无法改成动态规划是因为没有足够的重复的过程(因为没有大量的使用重复解。)
其实就是把参数组合完成了结构化的。
//根据递归过程改动态规划
int ways2(int N,int M,int K,int P)
{
// 参数无效直接返回0
if (N < 2 || K < 1 || M < 1 || M > N || P < 1 || P > N) {
return 0;
}
vector<vector<int>> dp(N + 1, vector<int>(K + 1));
dp[0][P] = 1;
for (int i =1; i <= K; i++)
{
for (int j = 1; j <= N; j++)
{
if (j == 1)
{
dp[i][j] = dp[i - 1][2];
}
else if (j == N)
{
dp[i][j] = dp[i - 1][N - 1];
}
else
{
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j + 1];
}
}
}
return dp[K][M];
}
12.3背包问题改动态规划
背包问题改动态规划,因为会有重复利用的问题,所以说会有动态规划的意义的存在。
下图就说明了重复在哪。
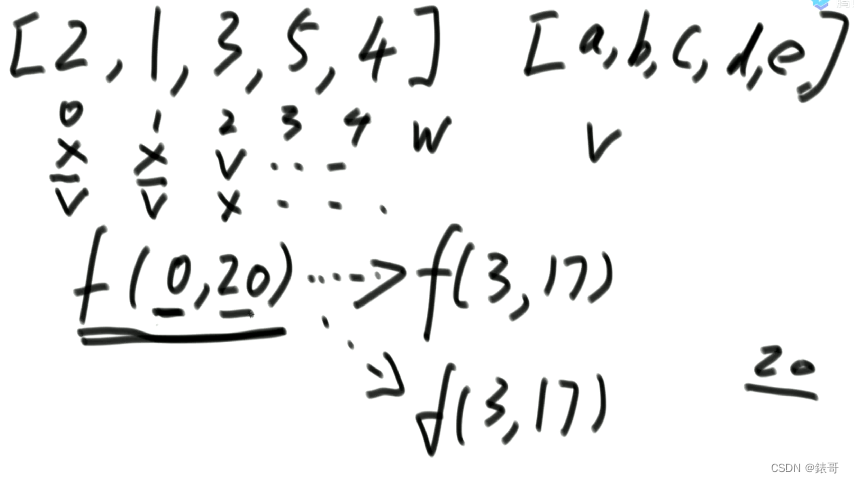
一旦写出暴力递归,那么递归就能改动态规划,不用再看原始题意就可以,解耦了。
背包问题,最后要的是dp表(0,bag)位置的返回值。
所谓动态规划转移方程,其实就是暴力递归的点。
把两个可变参数变化范围整理清楚后,生成一张二维表。
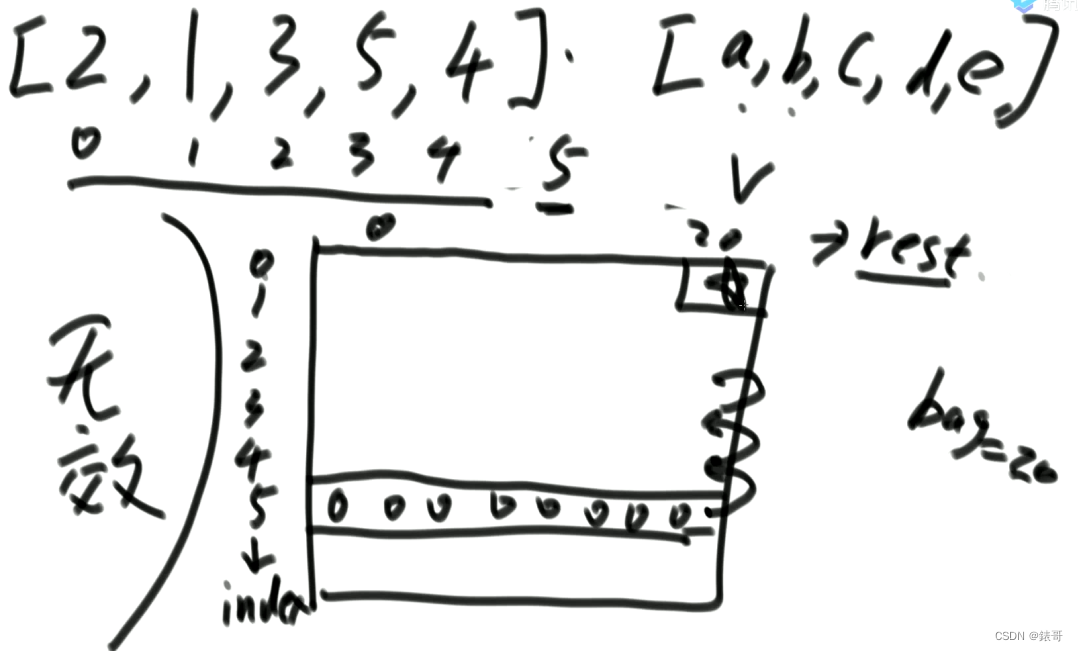
有了递归后,改动态规划和原题意没有任何关系,看着递归过程就能改出来。
#include<vector>
#include<iostream>
using namespace std;
// 只剩下rest的空间了,
// index...货物自由选择,但是剩余空间不要小于0
// 返回 index...货物能够获得的最大价值
int process(vector<int>& w, vector<int>& v, int index, int rest)
{
if (rest < 0)
{
return -1;
}
if (index == w.size())
{
return 0;
}
//背包既有空地方又没选完呢
int p1 = process(w, v, index + 1, rest);//没选
int p2 = -1;//先假设p2方案无效
int p2next = process(w, v, index + 1, rest - w[index]);//index位置上的物品要了,因此剩余的物品重量要减去,但是之后要确认负重是否合理
if (p2next != -1)
{
p2 = v[index] + p2next;//当p2Next是有效的时候,p2修改为有效
}
return max(p1, p2);
}
int dpWay(vector<int>& w, vector<int>& v, int bag)
{
int N = w.size();
//里面必须要填上常量
vector<vector<int>> dp(N + 1, vector<int>(bag + 1));
for (int i = 0; i < 12; i++)
{
dp[N][i] = 0;
}
for (int index = N - 1; index >= 0; index--)//第一个for循环规定了从下面行往上面行开始填
{
for (int rest = 0; rest <= bag; rest++)// rest < 0 从左往右填好每一行
{
//在每一个循环体内,都把index和rest定了下来,其实就是求dp[index][rest]?
int p1 = dp[index + 1][rest];
int p2 = -1;
if (rest - w[index] > 0)//保证数组内的不越界
{
p2 = v[index] + dp[index + 1][rest - w[index]];//后面那个要保证不越界才行
}
dp[index][rest] = max(p1, p2);
/*
//背包既有空地方又没选完呢
int p1 = process(w, v, index + 1, rest);//没选
int p2 = -1;//先假设p2方案无效
int p2next = process(w, v, index + 1, rest - w[index]);//index位置上的物品要了,因此剩余的物品重量要减去,但是之后要确认负重是否合理
if (p2next != -1)
{
p2 = v[index] + p2next;//当p2Next是有效的时候,p2修改为有效
}
return max(p1, p2);
*/
}
}
return dp[0][bag];
}
int maxValue(vector<int>& w, vector<int>& v, int bag)
{
return process(w, v, 0, bag);
}
int main()
{
vector<int> weights = { 3,2,4,7 };
vector<int> values = { 5,6,3,19 };
int bag = 11;
cout << dpWay(weights, values, bag) << endl;
cout << maxValue(weights, values, bag) << endl;
system("pause");
return 0;
}
12.4字符串转数字动态规划
只有一个可变参数,所以是一维表,根据初始信息,可以后面的信息。
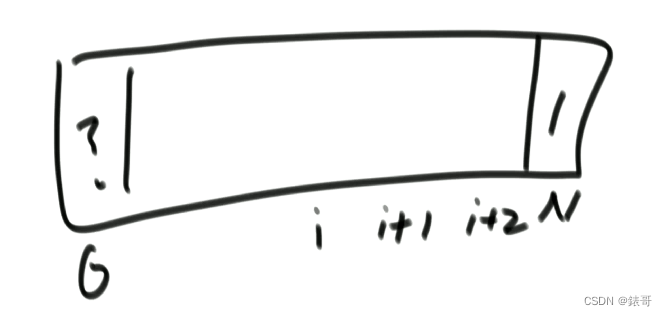
毫无疑问,这张表要从右往左填。
这里有个小疑问,一维表比大小多了1个?这是为啥
#include<iostream>
#include<vector>
using namespace std;
// str[0...i-1]已经转化完了,固定了
// i之前的位置,如何转化已经做过决定了, 不用再关心
// i... 有多少种转化的结果
int process(string str, int index)
{
if (index == str.size())// base case
{
return 1;//终止条件,返回1,,可以进行相加
}
//i没有到终止位置
if (str[index] == '0')
{
return 0;
} //0没有办法转化,1对应a,26对应z,0是没法转换的,所以只要i位置出现0,就不用管后面的情况,直接return 0退出就行。
//i没有到终止位置
//str[i]字符不是‘0’
if (str[index] == '1')
{
int res = process(str, index + 1);//i自己作为单独的部分,后续有多少种方法
if (index + 1 < str.size())
{
res += process(str, index + 2);//i和i+1作为单独的部分,后续有多少种方法
}
return res;
}
if (str[index] == '2')
{
int res = process(str, index + 1); //i自己作为单独的部分,后续有多少种方法
//i和i+1作为单独的部分并且没有超过26.后续有多少种方法。
if (index + 1 < str.size() && str[index + 1] >= '0' && str[index + 1] <= '6')
{
res += process(str, index + 2);// (i和i+1)作为单独的部分,后续有多少种方法
}
return res;
}
//str[i] == ‘3’~‘9’,不可能和i+1位置共同进行转换了,因为肯定会超过26.
return process(str, index + 1);
}
int dpWay(string str)
{
int n = str.size();
if (n == 0)return 0;
//只有index是一个可变参数,从0到n-1
vector<int> dp(n+1,0);
dp[n] = 1;
for (int i = n - 1; i >= 0; i--)
{
//dp[i] = ?
if (str[i] == '0')
{
dp[i] = 0;
}
if (str[i] == '1')
{
dp[i] = dp[i + 1];
if (i + 1 < n)
{
dp[i] += dp[i + 2];
}
}
if (str[i] == '2')
{
dp[i] = dp[i + 1];
if ((i + 1) <n && str[i + 1] >= '0' && str[i + 1] <= '6')
{
dp[i] += dp[i + 2];
}
}
}
return dp[0];
}
int number(string str)
{
if (str.size() == 0)
{
return 0;
}
return process(str, 0);
}
int main()
{
cout << number("111") << endl;
cout << dpWay("111") << endl;
system("pause");
return 0;
}
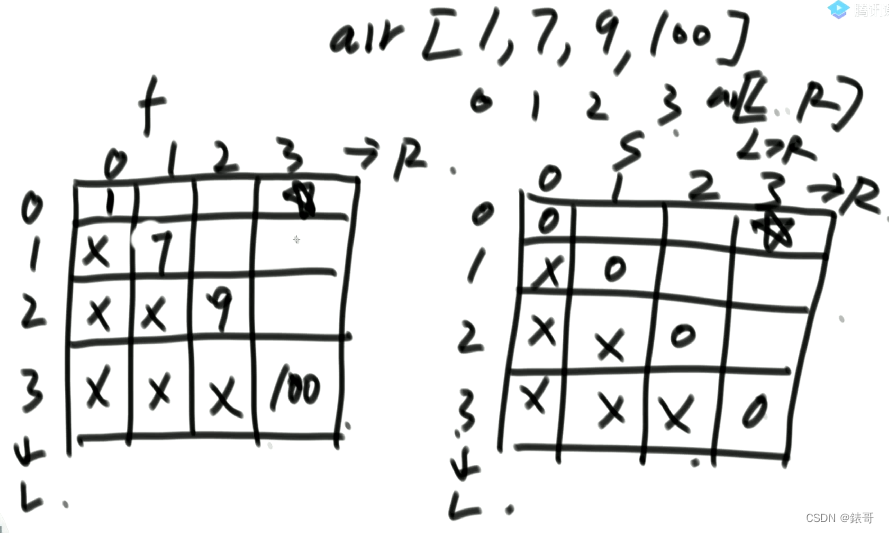
12.5卡牌问题转动态规划
两个参数L和R代表卡牌的范围。
所以如果是正方形的表,如果F和S是两个过程的话,则对应两张正方形的表。
并且因为L>R 时无效,所以半张表是无效的。
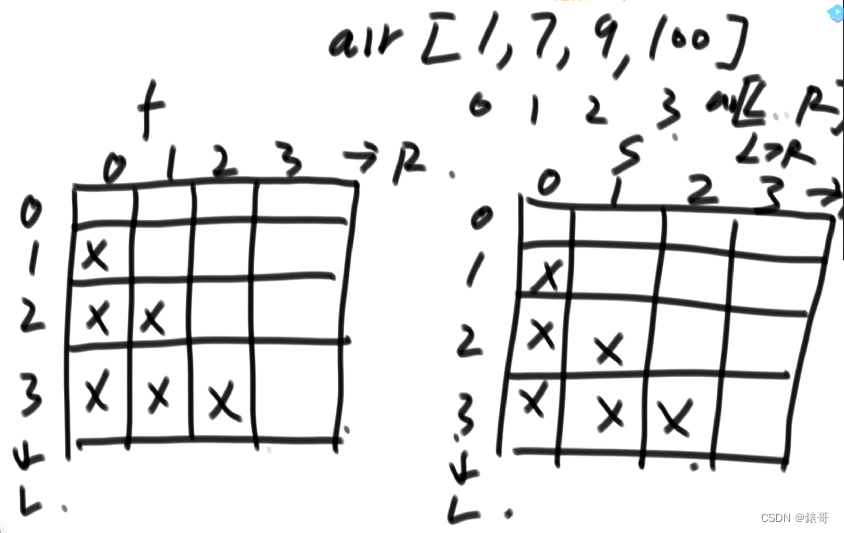
用f的对象线来推s对角线上一条,用s对角线来推f对角线上一条,以此类推。
两个表交替往上推,推到星号就可以结束了。
只要从已知推得星号位置的信息,就可以了。
#include<iostream>
#include<vector>
using namespace std;
int f(vector<int>& card, int L, int R);
int s(vector<int>& card, int L, int R);
int win(vector<int>& card)
{
if (card.size() == 0)return 0;
return max(f(card, 0, card.size() - 1), s(card, 0, card.size() - 1));
}
// L....R
// F S L+1..R
// L..R-1
//L和R是用来在范围中拿值的
int f(vector<int>& card, int L, int R)
{
if (L == R)return card[L];
return max(card[L] + s(card, L + 1, R), card[R] + s(card, L, R - 1));
}
//后手的选择权并不在自己,因此对方一定是按后手的效益最低化来选取的,所以说是min,你没得选,对手丢给你两者中最小的
int s(vector<int>& card, int L, int R)
{
if (L == R)return 0;
return min(f(card, L, R - 1), f(card,L + 1, R));
}
//这里又是n的大小了。
int win2(vector<int>& card)
{
int n = card.size();
vector<vector<int>> f(n, vector<int>(n));
vector<vector<int>> s(n, vector<int>(n));
for (int i = 0; i < n; i++)
{
f[i][i] = card[i];
}
//s[i][i]=0;
for (int i = 1; i < n; i++)
{
int L = 0;
int R = i;
while (L < n && R < n)
{
//dp[L][R] = ?
f[L][R] = max(card[L] + s[L + 1][R], card[R] + s[L][R - 1]);
s[L][R] = min(f[L + 1][R], f[L][R - 1]);
L++;
R++;
}
}
return max(f[0][n - 1], s[0][n - 1]);
}
int main()
{
vector<int> card = { 4,7,9,5,19,29,80,4 };
cout << win(card) << endl;
cout << win2(card) << endl;
system("pause");
return 0;
}
12.6钱的方法数
题目:
给定数组arr,arr中所有的值都为正数且不重复。
每个值代表一种面值的货币,每种面值的货币可以使用任意张,再给定一个正数aim,代表要找的钱数。
求组成aim的方法数。
后效性:前面的选择影响后面,比如一个1*2的网格往正方形的方格里面摆。多少种摆法。如下的摆法,不管怎么摆都是一样的。
可变参数选对了,前面的选择不会影响后面的状态,只要看状态就行了,就是无后效性的。类似于状态同步。
整体顺序从小往上,具体每一行从左往右。
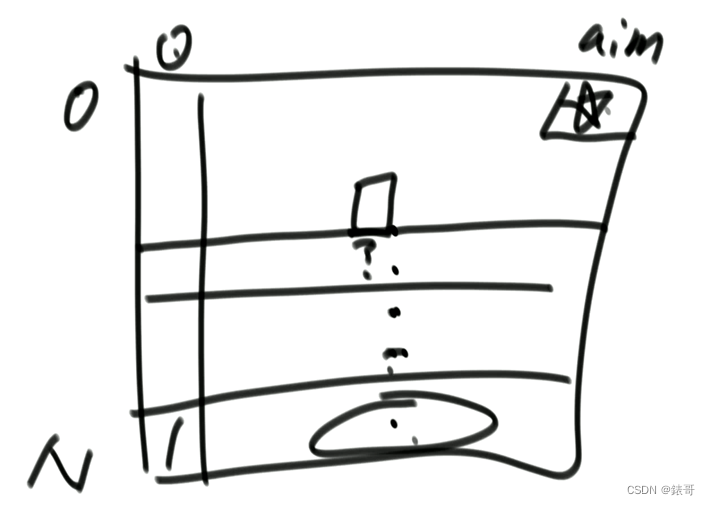
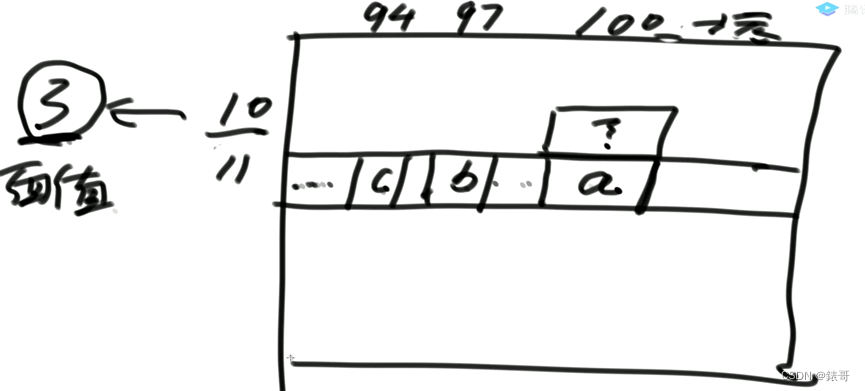

12.6.1暴力递归方法实现
#include<iostream>
#include<vector>
using namespace std;
int process(vector<int>& money, int index, int rest);
int process1(vector<int>& money, int index, int rest, vector<vector<int>>& dp);
//money中都是正数且无重复值,返回组成aim的方法数
int ways1(vector<int>& money, int aim)
{
if (money.size() == 0 || aim < 0)
{
return 0;
}
return process(money, 0, aim);//直接返回,当1张还没选时,目标是aim的方法数
}
//暴力递归过程
//可以自由使用money[index...]所有的面值,每一种面值都可以使用任意张,
//组成rest,有多少种方法
int process(vector<int>& money, int index, int rest)
{
if (rest < 0)
{
return 0;//其实由于下面,rest - (zhang * money[index])肯定>0,所以说这里可以不用写。
}
//rest>=0;
if (index == money.size())//没有货币可以进行选择了
{
return rest == 0 ? 1 : 0;
}
//当前有货币,money[index]
int ways = 0;
for (int zhang = 0; zhang * money[index] <= rest; zhang++)
{
ways += process(money, index + 1, rest - (zhang * money[index]));
}
return ways;
}
12.6.2记忆化搜索方式(自顶向下的的动态规划)
傻缓存也是动态规划的一种,只不过不够精细化,有点傻= 。=
傻缓存思路很简单,算过的直接去缓存里拿,没算过的就算了之后存进去。
//记忆化搜索过程
int ways2(vector<int>& money, int aim)
{
int n = money.size();
if (money.size() == 0||aim<0)
{
return 0;
}
vector<vector<int>> dp(n + 1, vector<int>(aim + 1,-1));
//一开始所有的过程,都没有计算呢
//dp[..][..]
return process1(money, 0, aim, dp);
}
// 如果index和rest的参数组合,是没算过的,dp[index][rest] == -1
// 如果index和rest的参数组合,是算过的,dp[index][rest] > - 1
// 这叫自顶向下的动态规划,没算过的我就给他算,算过的就给他值。
int process1(vector<int>& money, int index, int rest, vector<vector<int>>& dp)
{
if (dp[index][rest] != -1)
{
return dp[index][rest];
}
if (index == money.size())
{
dp[index][rest] = rest == 0 ? 1 : 0;//在return之前要把dp表进行更新
return dp[index][rest];
}
int ways = 0;
for (int zhang = 0; zhang * money[index] <= rest; zhang++)
{
ways += process1(money, index + 1, rest - (zhang * money[index]), dp);
}
dp[index][rest] = ways;
return ways;
}
12.6.3正版动态规划
//第一版动态规划,但是每一行有枚举行为,和记忆化搜索等效,因为有枚举行为,所以还是可以进行优化的。
int ways3(vector<int>& money, int aim)
{
int n = money.size();
if (n == 0||aim<0) return 0;
vector<vector<int>> dp(n + 1, vector<int>(aim + 1, 0));
dp[n][0] = 1;// dp[N][1...aim] = 0;dp[n][0]是指已经选了n种钱了,此时剩余0元要选,符合题意。
//怎么得到dp[index][rest]?
for (int index = n - 1; index >= 0; index--)
{
for (int rest = 0; rest <= aim; rest++)
{
int ways = 0;
for (int zhang = 0; zhang * money[index] <= rest; zhang++)
{
ways += dp[index + 1][rest - (zhang * money[index])];
}//预处理数组的某些题,斜率优化的某些题,四边形不等式的某些题,都是可以优化的。
dp[index][rest] = ways;
}
}
return dp[0][aim];
}
12.6.4优化后的动态规划
int ways4(vector<int>& money, int aim)
{
int n = money.size();
if (n == 0||aim < 0) return 0;
vector<vector<int>> dp(n + 1, vector<int>(aim + 1, 0));
dp[n][0] = 1;
for (int index = n - 1; index >= 0; index--)
{
for (int rest = 0; rest <= aim; rest++)
{
dp[index][rest] = dp[index + 1][rest];
if (rest - money[index] >= 0)
{
dp[index][rest] += dp[index][rest - money[index]];
}
}
}
return dp[0][aim];
}
12.7贴纸问题
问题:给定一个字符串str,给定一个字符串类型的数组arr。
arr里的每一个字符串,代表一张贴纸,你可以把单个字符剪开使用,目的是拼出str来。
返回需要至少多少张贴纸可以完成这个任务。
例子:str= “babac”,arr={“ba”,“c”,“abcd”}
至少需要两张贴纸‘ba’和“abcd”,因为使用这两张贴纸,把每一个字符单独剪开,含有2个a,2个b和1个c,是可以拼出str的。所以返回2
最简单的方法,先排个序。选择第一张贴纸,进行枚举。搞定rest的第一张贴纸是什么。
一开始先判断数组中包含的字符能否覆盖该问题,没有直接返回假。
不要跳过暴力递归过程直接来动态转移。
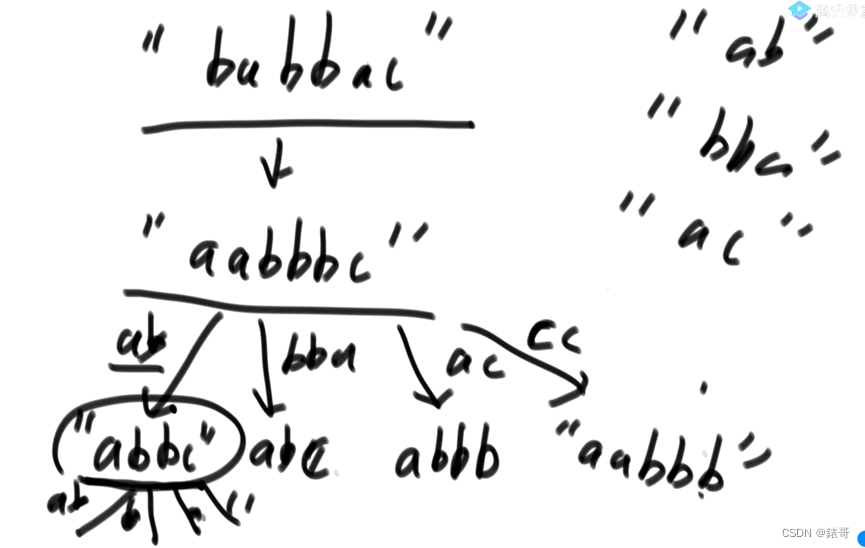
没必要留贴纸的字符串,我们只需要留下词频就可以。完全可以转化成数组。数组长度26,对应26个字母。
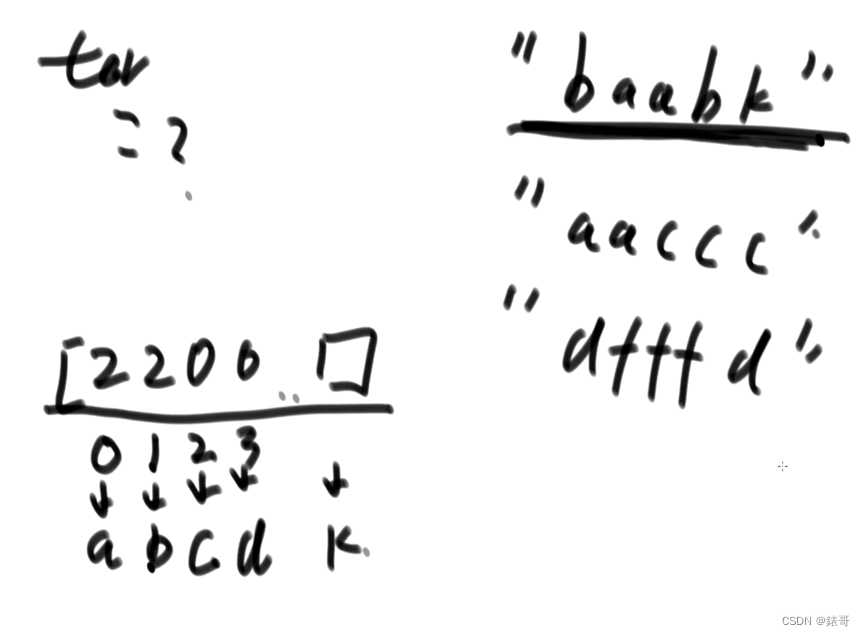
等价生成一个代表词频的数组。
这里的傻缓存叫rest。
傻缓存的思路就是,算过的去用,没算过的去算。
在这里插入代码片
这道题,第一轮选aa,第二轮bb,和第一轮bb,第二轮aa,对第三轮的选择是没有影响的,如果能记录下来,就可以加速,因此可以改为动态规划。
但是rest的可能性有无数个,因此精细化的动态规划没必要,所以傻缓存就可以了。
细粒度的种类太多了,不好枚举。
continue那个地方,起到了贪心加速的过程,但是不能去掉。比如消不掉xyz的话,不加速的话,会无限循环。
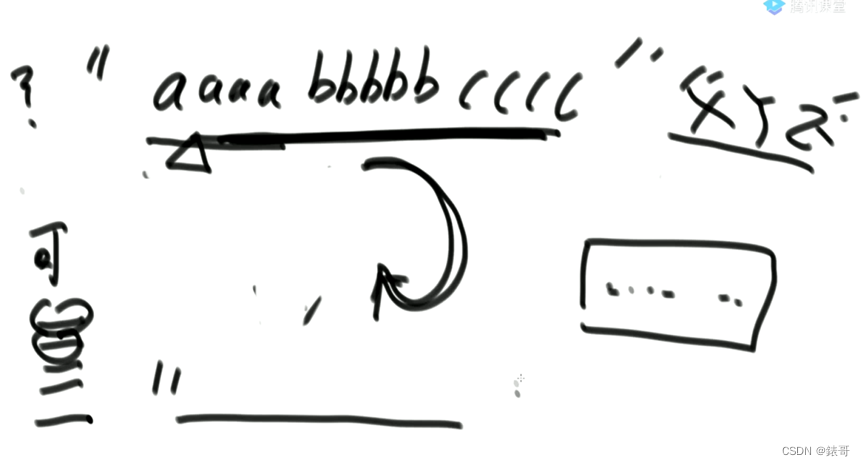
设计递归的原则,可变参数越少越好,越少dp表的维数越低,缓存命中率越高,越好写。
12.8两个字符串的最长公共子序列(多样本位置全对应问题)
题目类似下图所示,两个字符串,都包含1,2,3,4,5,且是其最大的公共子序列(序列和是否连续是无关的)
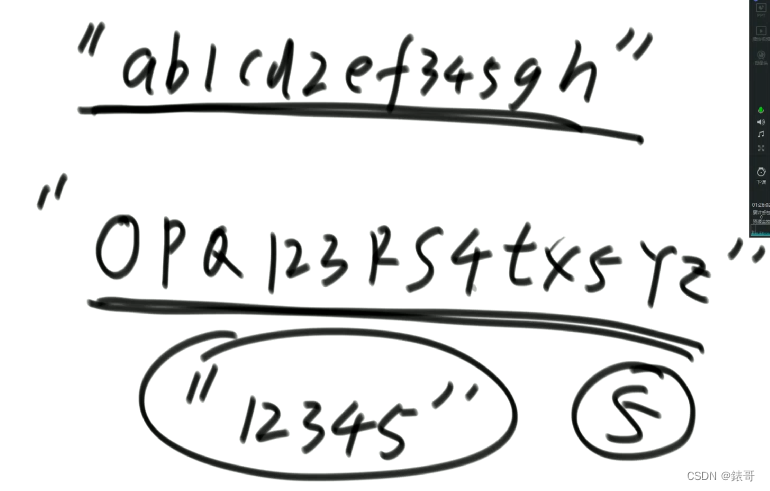
两个样本的对应模型,就是一个字符串做行,一个字符串做列,两个对应成一个二维表,全对应。
可以设计一个f,f(str1,i1,str2,i2)。表示到了str1的i1位置,str2的i2位置
但是这里左神为了节省时间,直接就对表下手了,dp[i][j]的含义是,str1[0…i],str2[0…j]的公共子序列有多长,那个int值放到dp表内。
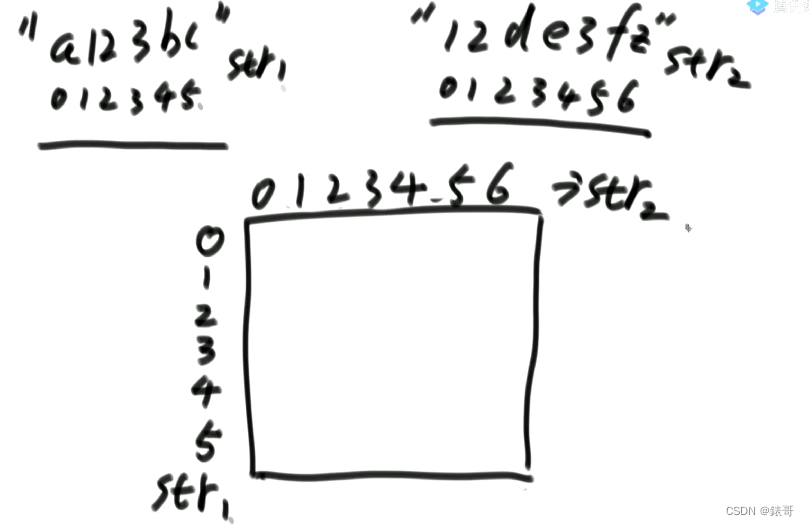
对于这道题,我们要找的是dp[5][6];
先解决边界问题,也就是第一行和第一列。
之后在想办法去找dpij;
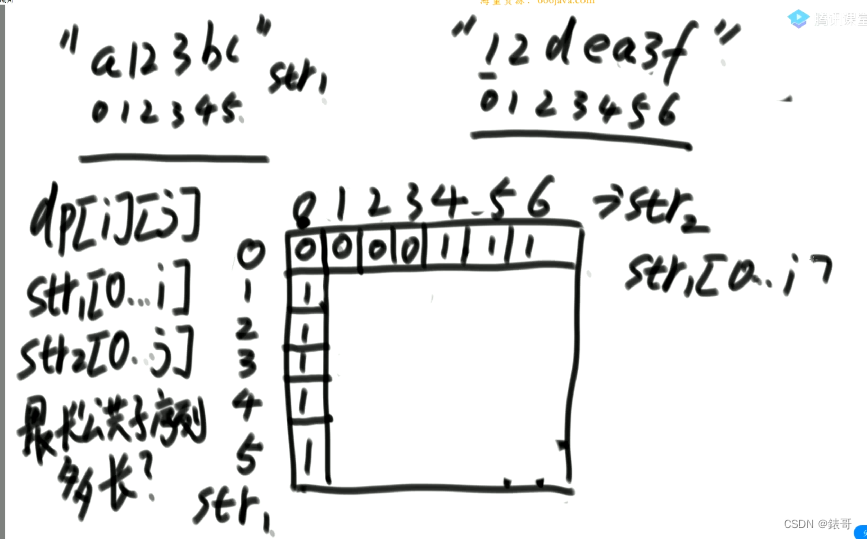
有四种可能的情况
1.最长公共子序列不以i和j结尾。在都不结尾的情况下,与i,j位置没关系。也就是说依赖于i-1,j-1的位置的情况。
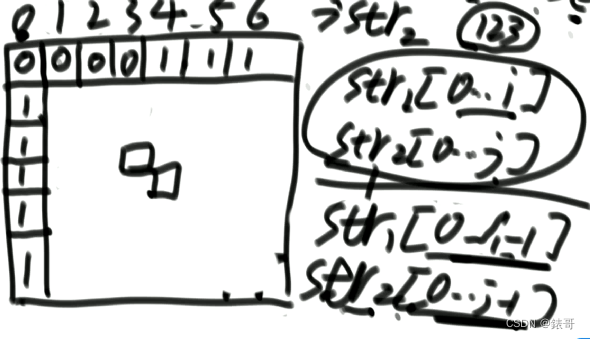


2.最长公共子序列以i结尾,不以j结尾。
第二种依赖左侧格子的解。
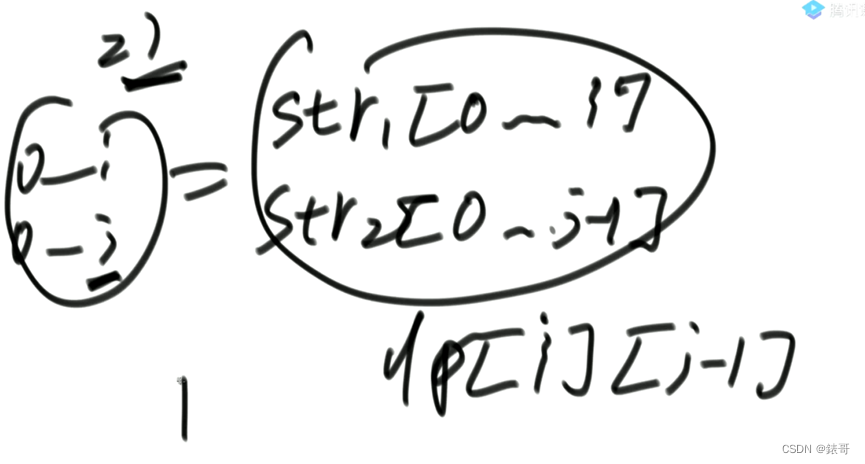
3.最长公共子序列以j结尾,不以i结尾。与2同理,依赖的是上面格子。

4.最长公共子序列,以i,j位置结尾。
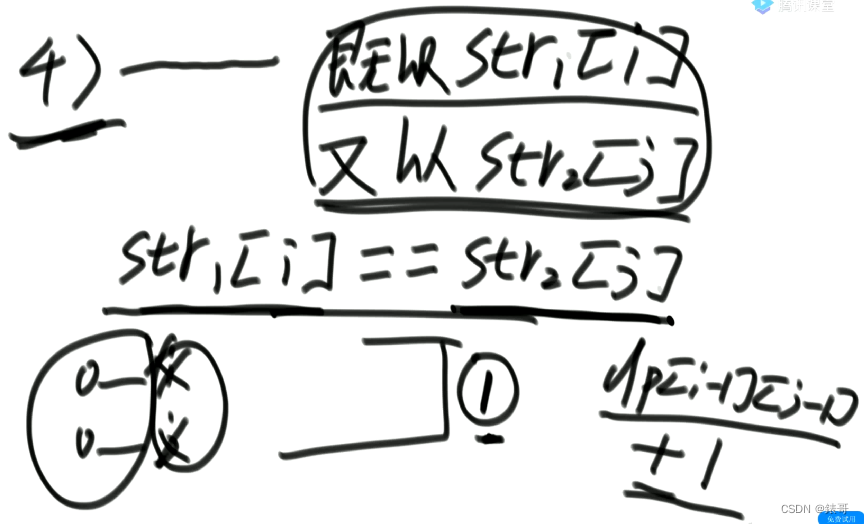
按照最长公共子序列结尾在哪进行的组织的可能性。
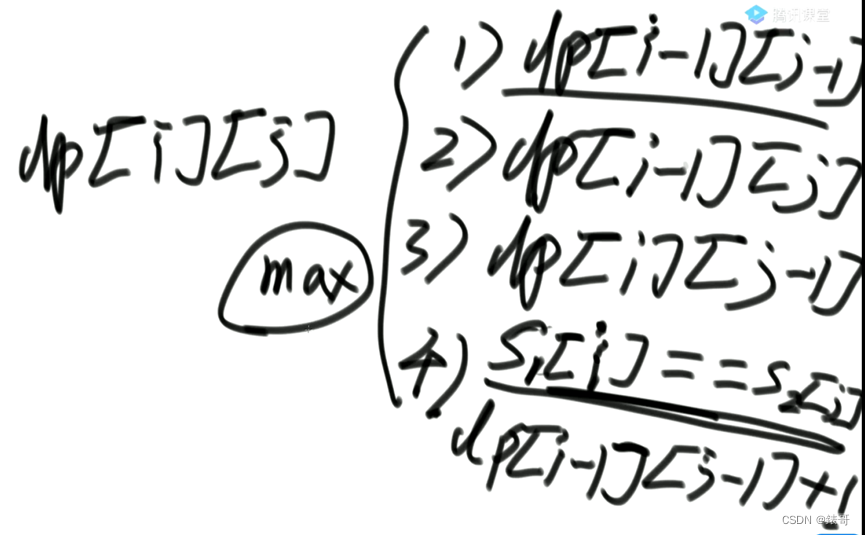
#include<iostream>
#include<vector>
using namespace std;
int lcse(string str1,string str2)
{
int m = str1.size();
int n = str2.size();
vector<vector<int>> dp(m, vector<int>(n));
dp[0][0] = str1[0] == str2[0] ? 1 : 0;
for (int i = 1;i< str1.size(); i++)
{
//下边那个表示,一旦出现了相同字符,则后面的全是1
dp[i][0] = max(dp[i - 1][0], str1[i] == str2[0] ? 1 : 0);
}
for (int j = 1; j < str2.size(); j++)
{
//下边那个表示,一旦出现了相同字符,则下面的全是1
dp[0][j] = max(dp[0][j-1], str1[0] == str2[j] ? 1 : 0);
}
for (int i = 1; i < m; i++)
{
for (int j = 1; j < n; j++)
{
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]);
if (str1[i] == str2[j])
{
dp[i][j] = max(dp[i][j], dp[i - 1][j - 1] + 1);
}
}
}
return dp[m-1][n-1];
}
int main()
{
system("pause");
return 0;
}
12.9寻找业务限制的尝试模型
题目:给定一个数组,代表每个人喝完咖啡准备刷杯子的时间
只有一台咖啡机,一次只能洗一个杯子,时间耗费a,洗完才能洗下一杯。
每个咖啡杯也可以自己挥发干净,时间耗费b,咖啡杯可以并行挥发
返回让所有咖啡杯变干净的最早完成时间
三个参数,vector
coffee ,int a,int b;
只要决定要洗,就不能再挥发了。
挥发可以是并行的,但是洗咖啡杯是串行的。
这是一个从左往右的尝试模型,也是一个业务限制的模型。
#include<iostream>
#include<vector>
using namespace std;
//process(drinks,3,10,0,0)
//a 洗一杯的时间
//b 自己挥发干净的时间,固定变量
//drinks 每一个员工喝完的时间,固定变量
//drinks[0..index-1]都已经干净了,不用你操心了
//drinks[index...]都想变干净,这是我操心的,washLine表示洗的机器何时可用
//drinks[index...]变干净,最少的时间点返回
//从左往右的尝试模型加业务限制模型
//只有index和washine是可变参数。
int process(vector<int>& drinks,int a,int b,int index,int washLine)
{//关心咖啡机来到什么时候就行了,washline最夸张的情况是全洗
//n是员工个数
int n = drinks.size();
if (index == n - 1)
{//min比较的是洗一杯和挥发的时间最小值。其中洗又要选喝完和机器的最大值。
return min(max(washLine, drinks[index]) + a, drinks[index] + b);
}
// 剩不止一杯咖啡
// wash是我当前的咖啡杯,
int wash = max(washLine, drinks[index]) + a;// 洗,index一杯,结束的时间点
// index+1...变干净的最早时间
int next1 = process(drinks, a, b, index + 1, wash);//如果index选择洗的话,下一杯也就是index+1及其之后的杯子变干净的话最早时间点。
//所以index往后的最短时间,即要index洗完,也要求index+1即往后洗完.
int p1 = max(wash, next1);
int dry = drinks[index] + b;//当前杯index挥发的时间
int next2 = process(drinks, a, b, index + 1, washLine);//在前一杯index选择挥发的前提下,index+1及其后面变干净的最早时间点
//所以index往后的最短时间,即要index挥发完,也要求index+1及往后都干净.
int p2 = max(dry, next2);
return min(p1, p2);
}
int dp(vector<int>& drinks,int a,int b)
{
int n = drinks.size();
//洗一杯的时间比挥发的时间长,那直接都挥发就行了。。。。
if (a >= b)
{
return drinks[n - 1] + b;//挥发的时间比洗的时间短,还洗个球球
}
//a<b
int limit = 0;// 咖啡机什么时候可用
for (int i = 0; i < n; i++)
{
limit = max(limit, drinks[i]) + a;washline的极限,是不可能超过limit的
}
vector<vector<int>> dp(n, vector<int>(limit + 1));//0-limit都可能,所以是limit+1
//n-1行,所有的值
for (int washLine = 0; washLine <= limit; washLine++)
{
dp[n - 1][washLine] = min(max(washLine, drinks[n - 1]) + a, drinks[n - 1] + b);
}
for (int index = n - 2; index >= 0; index--)
{
for (int washLine = 0; washLine <= limit; washLine++)
{
int p1 = INT16_MAX;
int wash = max(washLine, drinks[index]) + a;
if (wash <= limit)//怎么知道p1存在不存在,只有左边的不越界才存在。
{
p1 = max(wash, dp[index + 1][wash]);
}
//p2不会越界,因为washLine一直没有变化。
int p2 = max(drinks[index] + b, dp[index + 1][washLine]);
dp[index][washLine] = min(p1, p2);
}
}
return dp[0][0];
}
int main()
{
vector<int> test = { 1,1,5,5,7,10,12,12,12,12,12,12,15 };
int a1 = 3;
int b1 = 10;
cout << process(test, a1, b1, 0, 0) << endl;
cout << dp(test, a1, b1) << endl;
system("pause");
return 0;
}
12.9跳马棋的题目
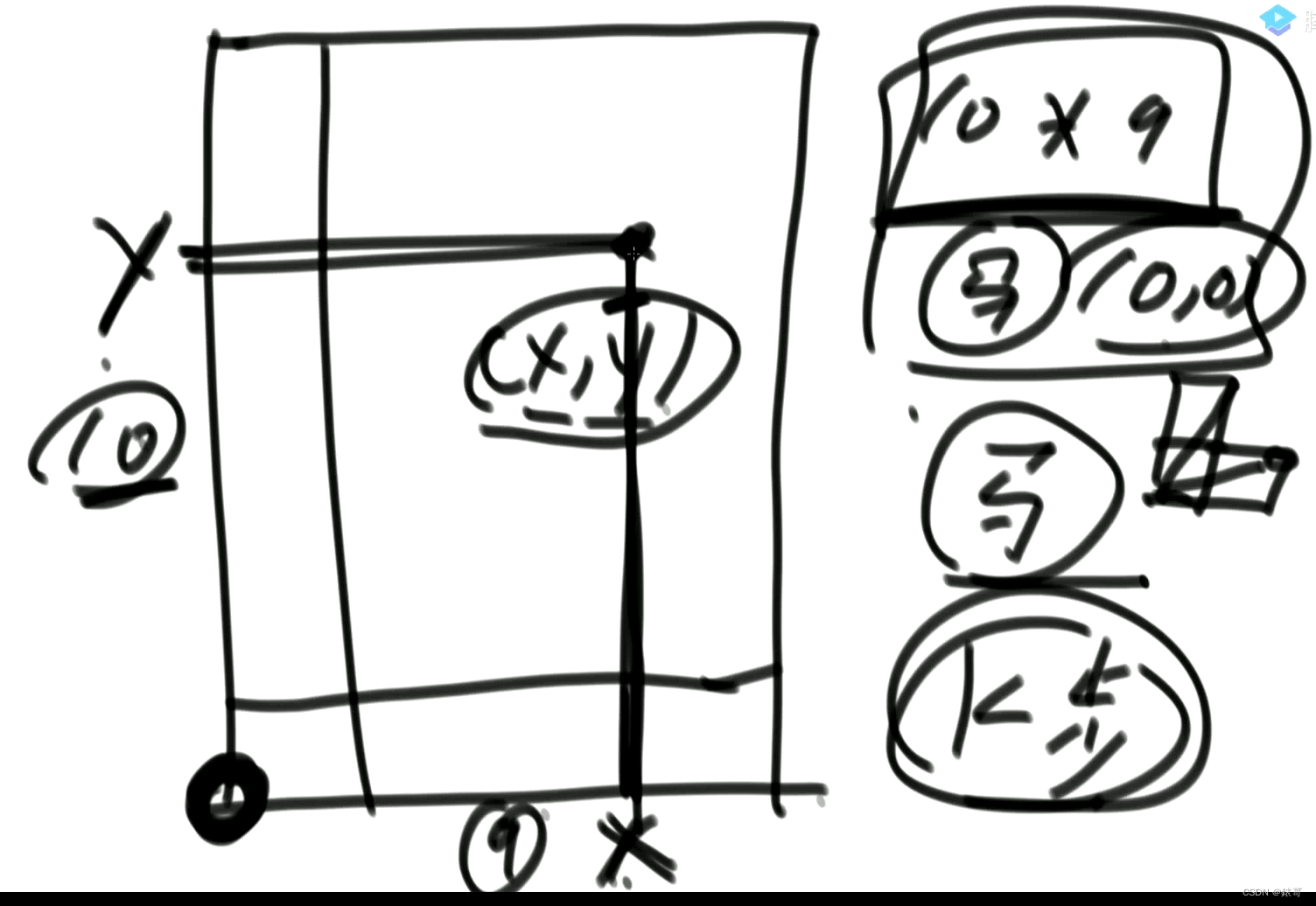
在象棋中,有一个竖着10条线,横着9条线的棋盘。
假设马在最左下的位置,马走日。
马从开始跳K步,跳到(x,y)点,问总共有多少种跳法。
递归函数这样就可以了。走k步,来到x,y的位置,问多少种方法。
可变参数有三个,当前位置的横纵坐标,和步数。
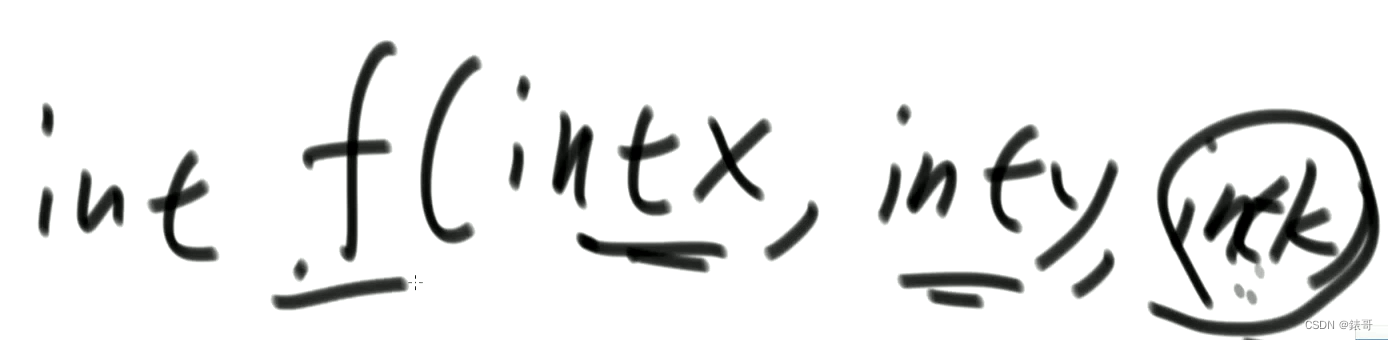
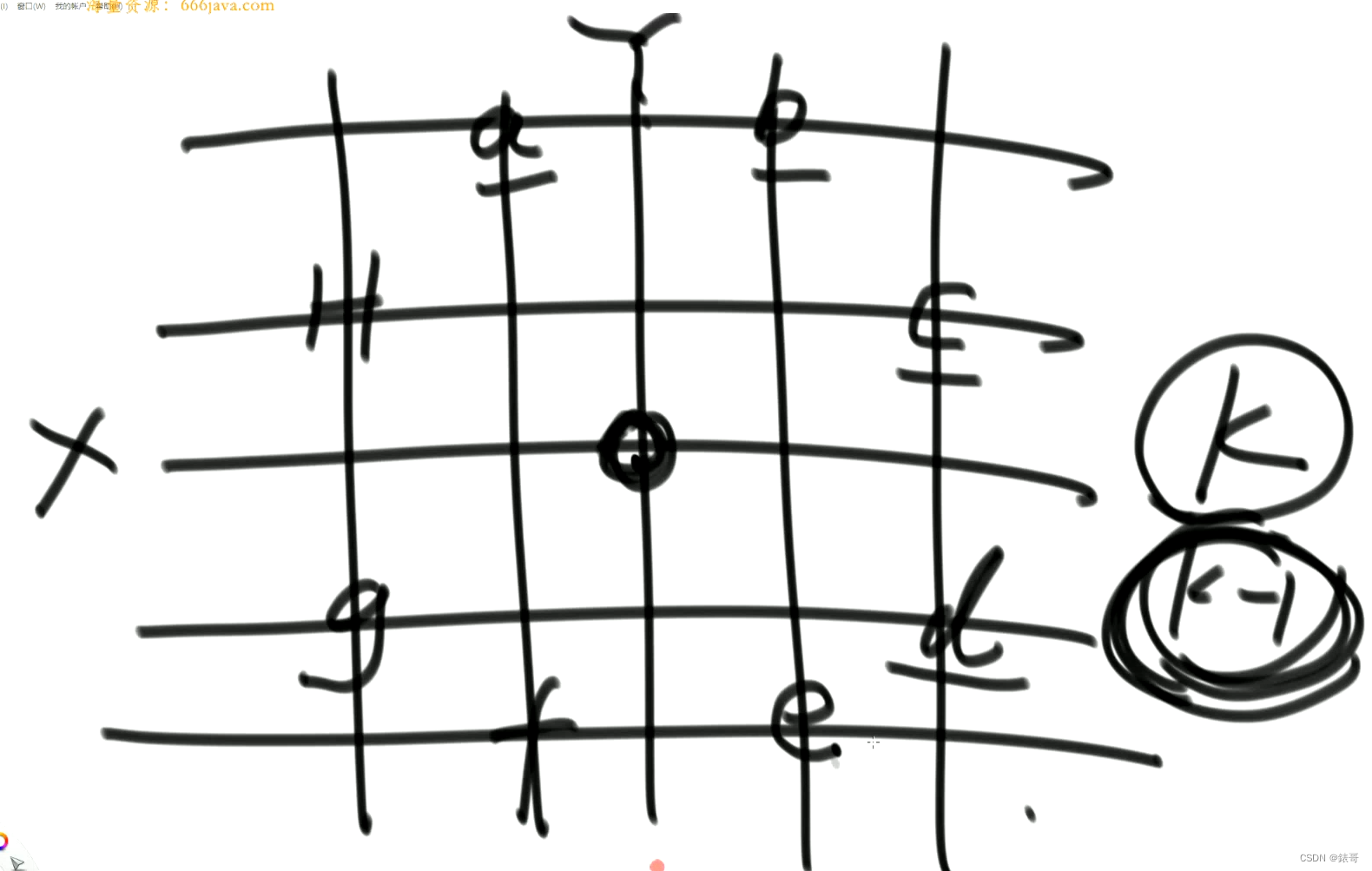
哪些位置能来到X,Y位置呢?
邻近的8个位置。
只要在k-1步的时候来到了邻近的8个位置之一,那下一步一定可以到达该地方。
int ways(int a, int b, int step)
{
return f(0,0,step,a,b);
}
//马初始是在(0,0),要走step步,走到(a,b)的位置,最终要来到x,y的位置上的方法数是多少种,i,j是当前的位置
int f(int i, int j, int step,int a,int b)
{
if (step == 0)
{
return (i == a && j == b) ? 1 : 0;
}
if (i < 0 || i>9 || j < 0 || j>8)
{
return 0;
}
//有步数要走,X,y也是棋盘上的位置
return f(i - 2, j + 1, step - 1, a, b)
+ f(i - 1, j + 2, step - 1, a, b)
+ f(i + 1, j + 2, step - 1, a, b)
+ f(i + 2, j + 1, step - 1, a, b)
+ f(i + 2, j - 1, step - 1, a, b)
+ f(i + 1, j - 2, step - 1, a, b)
+ f(i - 1, j - 2, step - 1, a, b)
+ f(i - 2, j - 1, step - 1, a, b);
}
改成动态规划,这里要注意,8个位置,每个位置的判定时,都有两种终止可能,一是返回1,二是直接越界返回0;所以不如直接写成个函数,好判别。
int getValue(vector<vector<vector<int>>>& dp, int i, int j, int step)
{
if (i < 0 || i>9 || j < 0 || j>8)
{
return 0;
}
return dp[i][j][step];
}
int dpWay(int a, int b, int s)
{
//i,j,0-step
vector<vector<vector<int>>> dp(10, vector<vector<int>>(9, vector<int>(s + 1)));
dp[a][b][0] = 1;
for (int step = 1; step <= s; step++)
{
for (int i = 0; i < 10; i++)
{
for (int j = 0; j < 9; j++)
{
dp[i][j][step] = getValue(dp, i - 2, j + 1, step - 1)
+ getValue(dp, i - 1, j + 2, step - 1)
+ getValue(dp, i + 1, j + 2, step - 1)
+ getValue(dp, i + 2, j + 1, step - 1)
+ getValue(dp, i + 2, j - 1, step - 1)
+ getValue(dp, i + 1, j - 2, step - 1)
+ getValue(dp, i - 1, j - 2, step - 1)
+ getValue(dp, i - 2, j - 1, step - 1);
}
}
}
return dp[0][0][s];
}
int main()
{
int x = 7;
int y = 7;
int step = 10;
cout << ways(x, y, step) << endl;
cout << dpWay(x, y, step) << endl;
system("pause");
return 0;
}















 125
125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









